- Strategie popolari per imputare statisticamente i valori mancanti in un set di dati.
- 2- Imputazione utilizzando i valori (mediana/media):
- 3- Imputazione con valori (più frequenti) o (zero/costanti):
- 4- Imputazione usando k-NN:
- Come funziona?
- 5- Imputazione utilizzando l’imputazione multivariata tramite equazione a catena (MICE)
- 6- Imputation Using Deep Learning (Datawig):
- Imputazione di regressione stocastica:
- Extrapolazione e interpolazione:
- Imputazione Hot-Deck:
Strategie popolari per imputare statisticamente i valori mancanti in un set di dati.
Molti set di dati del mondo reale possono contenere valori mancanti per vari motivi. Essi sono spesso codificati come NaN, spazi vuoti o qualsiasi altro segnaposto. Addestrare un modello con un set di dati che ha molti valori mancanti può avere un impatto drastico sulla qualità del modello di apprendimento automatico. Alcuni algoritmi come gli stimatori di scikit-learn assumono che tutti i valori siano numerici e abbiano e mantengano un valore significativo.
Un modo per gestire questo problema è quello di liberarsi delle osservazioni che hanno dati mancanti. Tuttavia, si rischia di perdere punti di dati con informazioni preziose. Una strategia migliore sarebbe quella di imputare i valori mancanti. In altre parole, dobbiamo dedurre quei valori mancanti dalla parte esistente dei dati. Ci sono tre tipi principali di dati mancanti:
- Mancanti completamente a caso (MCAR)
- Mancanti a caso (MAR)
- Non mancanti a caso (NMAR)
Tuttavia, in questo articolo, mi concentrerò su 6 modi popolari per l’imputazione dei dati per set di dati cross-sectional (i set di dati time-series sono una storia diversa).
Questo è facile. Basta lasciare che l’algoritmo gestisca i dati mancanti. Alcuni algoritmi possono tenere conto dei valori mancanti e imparare i migliori valori di imputazione per i dati mancanti in base alla riduzione della perdita di formazione (ad esempio XGBoost). Alcuni altri hanno l’opzione di ignorarli (es. LightGBM – use_missing=false). Tuttavia, altri algoritmi andranno nel panico e lanceranno un errore lamentandosi dei valori mancanti (es. Scikit learn – LinearRegression). In questo caso, sarà necessario gestire i dati mancanti e pulirli prima di fornirli all’algoritmo.
Vediamo alcuni altri modi per imputare i valori mancanti prima dell’allenamento:
Nota: Tutti gli esempi che seguono utilizzano il California Housing Dataset di Scikit-learn.
2- Imputazione utilizzando i valori (mediana/media):
Questo funziona calcolando la media/mediana dei valori non mancanti in una colonna e poi sostituendo i valori mancanti all’interno di ogni colonna separatamente e indipendentemente dagli altri. Può essere usato solo con dati numerici.

Pro:
- Facile e veloce.
- Funziona bene con piccoli insiemi di dati numerici.
Cons:
- Non fattorizza le correlazioni tra le caratteristiche. Funziona solo a livello di colonna.
- Dà scarsi risultati su caratteristiche categoriche codificate (NON usarlo su caratteristiche categoriche).
- Non è molto accurato.
- Non tiene conto dell’incertezza nelle imputazioni.
3- Imputazione con valori (più frequenti) o (zero/costanti):
Il più frequente è un’altra strategia statistica per imputare valori mancanti e SI! Funziona con caratteristiche categoriche (stringhe o rappresentazioni numeriche) sostituendo i dati mancanti con i valori più frequenti all’interno di ogni colonna.
Pros:
- Funziona bene con caratteristiche categoriche.
Cons:
- Non fattorizza anche le correlazioni tra caratteristiche.
- Può introdurre distorsioni nei dati.
Imputazione zero o costante – come suggerisce il nome – sostituisce i valori mancanti con zero o qualsiasi valore costante specificato

4- Imputazione usando k-NN:
Il k nearest neighbours è un algoritmo utilizzato per la classificazione semplice. L’algoritmo usa la “somiglianza delle caratteristiche” per predire i valori di qualsiasi nuovo punto di dati. Questo significa che al nuovo punto viene assegnato un valore basato su quanto assomiglia ai punti nel set di allenamento. Questo può essere molto utile per fare previsioni sui valori mancanti, trovando i k più vicini all’osservazione con dati mancanti e poi imputandoli in base ai valori non mancanti nel vicinato. Vediamo alcuni esempi di codice usando la libreria Impyute che fornisce un modo semplice e facile di usare KNN per l’imputazione:
Come funziona?
Crea un’imputazione media di base poi usa la lista completa risultante per costruire un KDTree. Poi, usa il KDTree risultante per calcolare i vicini più vicini (NN). Dopo aver trovato i k-NN, ne prende la media ponderata.
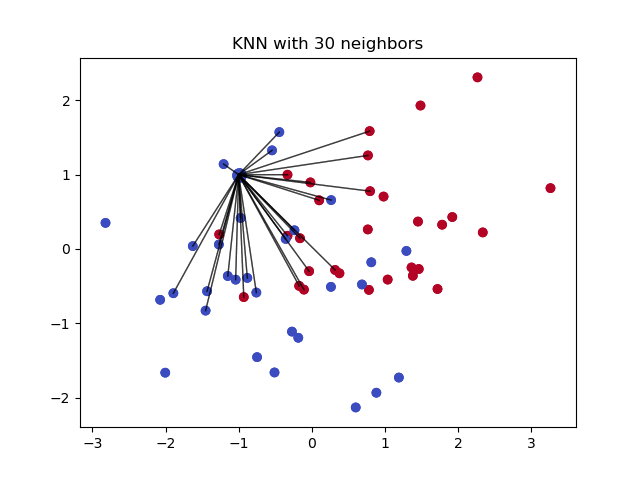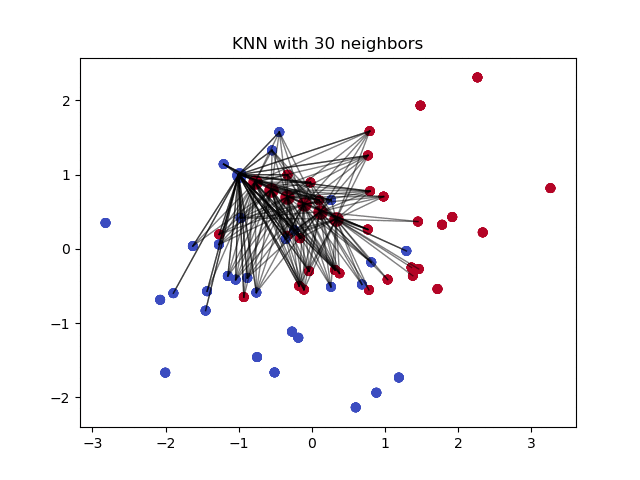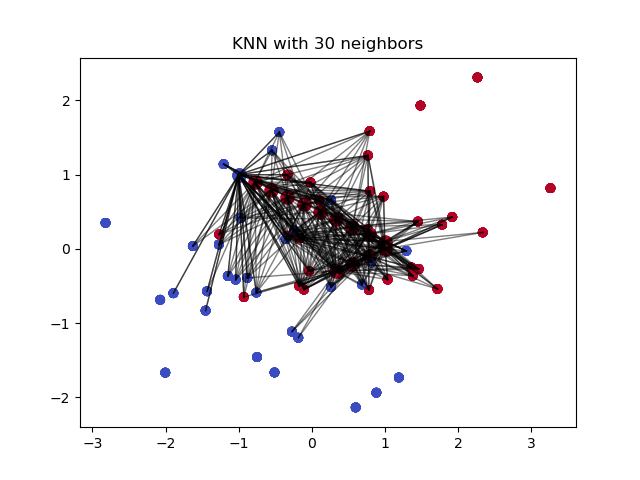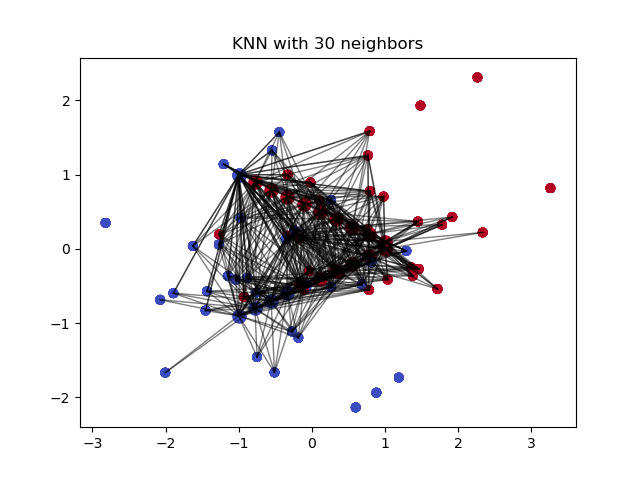
Pro:
- Può essere molto più accurato dei metodi di imputazione media, mediana o più frequenti (dipende dal dataset).
Cons:
- Costoso dal punto di vista informatico. KNN funziona memorizzando l’intero set di dati di allenamento in memoria.
- K-NN è abbastanza sensibile ai valori anomali nei dati (a differenza di SVM)
5- Imputazione utilizzando l’imputazione multivariata tramite equazione a catena (MICE)
Questo tipo di imputazione funziona riempiendo i dati mancanti più volte. Le imputazioni multiple (MI) sono molto meglio di una singola imputazione in quanto misurano l’incertezza dei valori mancanti in modo migliore. L’approccio delle equazioni concatenate è anche molto flessibile e può gestire diverse variabili di diversi tipi di dati (cioè, continui o binari) così come le complessità come i limiti o i modelli di salto del sondaggio. Per ulteriori informazioni sulla meccanica dell’algoritmo, è possibile fare riferimento al Research Paper

6- Imputation Using Deep Learning (Datawig):
Questo metodo funziona molto bene con caratteristiche categoriche e non numeriche. È una libreria che apprende modelli di apprendimento automatico utilizzando reti neurali profonde per imputare i valori mancanti in un dataframe. Supporta anche CPU e GPU per l’addestramento.
Pro:
- Quasi accurato rispetto ad altri metodi.
- Ha alcune funzioni che possono gestire dati categorici (Feature Encoder).
- Supporta CPU e GPU.
Cons:
- Singola colonna imputata.
- Può essere abbastanza lento con grandi set di dati.
- Devi specificare le colonne che contengono informazioni sulla colonna di destinazione che sarà imputata.
Imputazione di regressione stocastica:
È abbastanza simile all’imputazione di regressione che cerca di predire i valori mancanti regredendo da altre variabili correlate nello stesso set di dati più qualche valore residuo casuale.
Extrapolazione e interpolazione:
Tenta di stimare i valori da altre osservazioni entro l’intervallo di un insieme discreto di punti di dati noti.
Imputazione Hot-Deck:
Funziona scegliendo casualmente il valore mancante da un insieme di variabili correlate e simili.
In conclusione, non esiste un modo perfetto per compensare i valori mancanti in un dataset. Ogni strategia può funzionare meglio per certi set di dati e tipi di dati mancanti, ma può funzionare molto peggio su altri tipi di set di dati. Ci sono alcune regole fisse per decidere quale strategia utilizzare per particolari tipi di valori mancanti, ma al di là di questo, si dovrebbe sperimentare e verificare quale modello funziona meglio per il vostro set di dati.