V tomto blogu probereme základní pojmy logistické regrese a jaké problémy nám může pomoci řešit.

Logistická regrese je klasifikační algoritmus používaný k přiřazení pozorování k diskrétní množině tříd. Některé z příkladů klasifikačních problémů jsou E-mailový spam nebo ne spam, Podvodné nebo nepodvodné online transakce, Zhoubný nebo nezhoubný nádor. Logistická regrese transformuje svůj výstup pomocí logistické sigmoidní funkce a vrací hodnotu pravděpodobnosti.
Jaké jsou typy logistické regrese
- Binární (např. Tumor Maligní nebo Benigní)
- Multilineární funkce selháváTřída (např. Kočky, psi nebo Ovce)
Logistická regrese
Logistická regrese je algoritmus strojového učení, který se používá pro klasifikační problémy, je to algoritmus prediktivní analýzy a je založen na konceptu pravděpodobnosti.

Hypotéza logistické regrese má tendenci omezovat nákladovou funkci v rozmezí 0 až 1.
Hypotéza logistické regrese má tendenci omezovat nákladovou funkci v rozmezí 0 až 1. Proto ji lineární funkce nedokáže reprezentovat, protože může mít hodnotu větší než 1 nebo menší než 0, což podle hypotézy logistické regrese není možné.
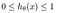
Co je to sigmoidní funkce?“
Pro zobrazení předpovídaných hodnot na pravděpodobnosti používáme sigmoidní funkci. Tato funkce mapuje libovolnou reálnou hodnotu na jinou hodnotu mezi 0 a 1. Ve strojovém učení používáme sigmoidu k mapování předpovědí na pravděpodobnosti.


Zobrazení hypotézy
Při použití lineární regrese jsme použili vzorec hypotézy, tj.
hΘ(x) = β₀ + β₁X
Pro logistickou regresi jej trochu upravíme, tj.Tj.
σ(Z) = σ(β₀ + β₁X)
Očekávali jsme, že naše hypotéza bude dávat hodnoty v rozmezí 0 až 1.
Z = β₀ + β₁X
hΘ(x) = sigmoid(Z)
tj. hΘ(x) = 1/(1 + e^-(β₀ + β₁X)

Hranice rozhodování
Očekáváme, že náš klasifikátor nám poskytne sadu výstupů nebo tříd na základě pravděpodobnosti, když vstupy projdeme predikční funkcí a vrátí skóre pravděpodobnosti mezi 0 a 1.
Pro příklad: Máme 2 třídy, berme je jako kočky a psy(1 – pes , 0 – kočky). V podstatě se rozhodneme pomocí prahové hodnoty, nad kterou hodnoty zařadíme do třídy 1 a z hodnoty, která je pod prahovou hodnotou, ji zařadíme do třídy 2.
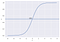
Jak ukazuje výše uvedený graf, zvolili jsme prahovou hodnotu 0,5, pokud by predikční funkce vrátila hodnotu 0,7, pak bychom toto pozorování zařadili do třídy 1(PES). Pokud by naše předpověď vrátila hodnotu 0,2, pak bychom pozorování klasifikovali jako třídu 2(KOČKA).
Nákladová funkce
V lineární regresi jsme se seznámili s nákladovou funkcí J(θ), nákladová funkce představuje optimalizační cíl, tj. vytváříme nákladovou funkci a minimalizujeme ji, abychom mohli vytvořit přesný model s minimální chybou.
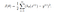
Pokud bychom se pokusili použít nákladovou funkci lineární regrese v „logistické regresi“, pak by byla k ničemu, protože by skončila jako nekonvexní funkce s mnoha lokálními minimy, v nichž by bylo velmi obtížné minimalizovat hodnotu nákladů a najít globální minimum.

Pro logistickou regresi je nákladová funkce definována jako:
-log(hθ(x)), pokud y = 1
-log(1-hθ(x)), pokud y = 0

.