Datový model vztahů entit (ER) existuje již více než 35 let. Je vhodný pro datové modelování pro použití s databázemi, protože je poměrně abstraktní a snadno se o něm diskutuje a vysvětluje. Modely ER se snadno převádějí na vztahy. Modely ER, nazývané také schéma ER, jsou reprezentovány diagramy ER.
Modelování ER je založeno na dvou konceptech:
- Entity, definované jako tabulky, které obsahují konkrétní informace (data)
- Vztahy, definované jako asociace nebo interakce mezi entitami
Uveďme si příklad, jak lze tyto dva koncepty kombinovat v datovém modelu ER: Prof. Ba (entita) vyučuje (vztah) předmět Databázové systémy (entita).
Po zbytek této kapitoly budeme pro ilustraci konceptů modelu ER používat vzorovou databázi nazvanou databáze FIRMY. Tato databáze obsahuje informace o zaměstnancích, odděleních a projektech. Mezi důležité body, které je třeba si uvědomit, patří:
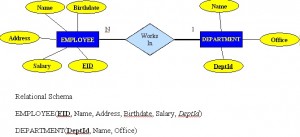
- Ve společnosti existuje několik oddělení. Každé oddělení má jedinečnou identifikaci, název, umístění kanceláře a konkrétního zaměstnance, který oddělení řídí.
- Oddělení řídí několik projektů, z nichž každý má jedinečný název, jedinečné číslo a rozpočet.
- Každý zaměstnanec má jméno, identifikační číslo, adresu, plat a datum narození. Zaměstnanec je přiřazen k jednomu oddělení, ale může se zapojit do několika projektů. Potřebujeme zaznamenat datum nástupu zaměstnance do každého projektu. Potřebujeme také znát přímého nadřízeného každého zaměstnance.
- U každého zaměstnance chceme evidovat závislé osoby. Každá závislá osoba má jméno, datum narození a vztah k zaměstnanci.
- Entita, množina entit a typ entity
- Závislost existence
- Druhy entit
- Nezávislé entity
- Závislé entity
- Charakteristické entity
- Atributy
- Typy atributů
- Jednoduché atributy
- Složené atributy
- Vícehodnotové atributy
- Odvozené atributy
- Klíče
- Typy klíčů
- Kandidátní klíč
- Složený klíč
- Primární klíč
- Sekundární klíč
- Alternate key
- Foreign key
- Nulový
- Příklad použití null
- Vztahy
- Typy vztahů
- Vztah jedna ku mnoha (1:M)
- Vztah jedna k jedné (1:1)
- Vztah mnoho k mnoha (M:N)
- Unární vztah (rekurzivní)
- Ternární vztahy
- Attribution
Entita, množina entit a typ entity
Entita je objekt v reálném světě s nezávislou existencí, který lze odlišit od ostatních objektů. Entita může být
Entity lze klasifikovat na základě jejich síly. Entita je považována za slabou, pokud jsou její tabulky existenčně závislé.
- To znamená, že nemůže existovat bez vztahu s jinou entitou
- Její primární klíč je odvozen od primárního klíče nadřazené entity
- Tabulka Manželé v databázi FIRMY je slabou entitou, protože její primární klíč je závislý na tabulce Zaměstnanci. Bez odpovídajícího záznamu zaměstnance by záznam manžela neexistoval.
Entita je považována za silnou, pokud může existovat odděleně od všech svých souvisejících entit.
- Jádra jsou silné entity.
- Tabulka bez cizího klíče nebo tabulka obsahující cizí klíč, který může obsahovat nuly, je silná entita
Dalším pojmem, který je třeba znát, je typ entity, který definuje soubor podobných entit.
Soubor entit je soubor entit typu entity v určitém okamžiku. V diagramu vztahů entit (ERD) je typ entity reprezentován názvem v rámečku. Například na obrázku 8.1 je typ entity EMPLOYEE.
Závislost existence
Existence entity je závislá na existenci související entity. Je závislá na existenci, pokud má povinný cizí klíč (tj. atribut cizího klíče, který nemůže být nulový). Například v databázi FIRMA je entita Manžel závislý na existenci entity Zaměstnanec.
Druhy entit
Měli byste také znát různé druhy entit včetně nezávislých entit, závislých entit a charakteristických entit. Ty jsou popsány níže.
Nezávislé entity
Nezávislé entity, označované také jako jádra, jsou páteří databáze. Na nich jsou založeny ostatní tabulky. Jádra mají následující vlastnosti:
- Jsou základním stavebním kamenem databáze.
- Primární klíč může být jednoduchý nebo složený.
- Primární klíč není cizí klíč.
- Svou existencí nezávisí na jiné entitě.
Pokud se vrátíme k naší databázi FIRMY, příkladem nezávislé entity je tabulka Zákazník, tabulka Zaměstnanec nebo tabulka Produkt.
Závislé entity
Závislé entity, označované také jako odvozené entity, jsou svým významem závislé na jiných tabulkách. Tyto entity mají následující vlastnosti:
- Závislé entity se používají k propojení dvou jader.
- Říká se, že jsou existenčně závislé na dvou nebo více tabulkách.
- Vztahy mnoho na mnoho se stávají asociativními tabulkami s nejméně dvěma cizími klíči.
- Mohou obsahovat další atributy.
- Cizí klíč identifikuje každou asociovanou tabulku.
- Existují tři možnosti primárního klíče:
- Použít složený cizí klíč přidružených tabulek, pokud je jedinečný
- Použít složený cizí klíč a kvalifikační sloupec
- Vytvořit nový jednoduchý primární klíč
Charakteristické entity
Charakteristické entity poskytují více informací o jiné tabulce. Tyto entity mají následující vlastnosti:
- Představují vícehodnotové atributy.
- Popisují jiné entity.
- Obvykle mají vztah jedna ku mnoha.
- Cizí klíč slouží k další identifikaci charakterizované tabulky.
- Možnosti primárního klíče jsou následující:
- Použít složený cizí klíč plus kvalifikační sloupec
- Vytvořit nový jednoduchý primární klíč. V databázi COMPANY to mohou být:
- Zaměstnanec (EID, Jméno, Adresa, Věk, Plat) – EID je jednoduchý primární klíč.
- ZaměstnanecTelefon (EID, Telefon) – EID je součástí složeného primárního klíče. Zde je EID zároveň cizím klíčem.
Atributy
Každá entita je popsána sadou atributů (např. zaměstnanec = (jméno, adresa, datum narození (věk), plat).
Každý atribut má název a je spojen s entitou a doménou legálních hodnot. Informace o doméně atributu však není v ERD uvedena.
V diagramu vztahů entit, který je znázorněn na obrázku 8.2, je každý atribut reprezentován oválem s názvem uvnitř.

Typy atributů
Existuje několik typů atributů, které je třeba znát. Některé z nich je třeba ponechat tak, jak jsou, ale některé je třeba upravit, aby se usnadnila reprezentace v relačním modelu. V této první části se budeme zabývat typy atributů. Později se budeme zabývat opravou atributů tak, aby správně zapadaly do relačního modelu.
Jednoduché atributy
Jednoduché atributy jsou ty, které jsou čerpány z domén atomických hodnot; říká se jim také jednohodnotové atributy. V databázi COMPANY by takovým příkladem byl např: Jméno = {John} ; Věk = {23}
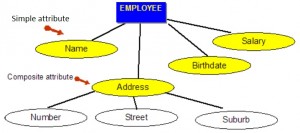
Složené atributy
Složené atributy jsou takové, které se skládají z hierarchie atributů. Na příkladu naší databáze, který je znázorněn na obrázku 8.3, se adresa může skládat z čísla, ulice a předměstí. Takže by se to zapsalo jako → Adresa = {59 + ‚Meek Street‘ + ‚Kingsford‘}
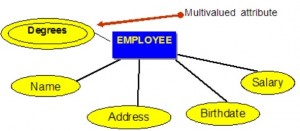
Vícehodnotové atributy
Vícehodnotové atributy jsou atributy, které mají pro každou entitu sadu hodnot. Příkladem vícehodnotového atributu z databáze COMPANY, jak je vidět na obrázku 8.4, jsou stupně zaměstnance:
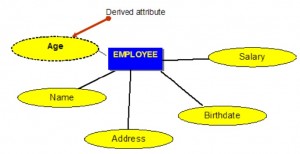
Odvozené atributy
Odvozené atributy jsou atributy, které obsahují hodnoty vypočtené z jiných atributů. Příklad je vidět na obrázku 8.5. Věk lze odvodit z atributu Datum narození. V této situaci se atribut Birthdate nazývá uložený atribut, který je fyzicky uložen v databázi.
Klíče
Důležitým omezením entity je klíč. Klíč je atribut nebo skupina atributů, jejichž hodnoty lze použít k jednoznačné identifikaci jednotlivé entity v souboru entit.
Typy klíčů
Existuje několik typů klíčů. Ty jsou popsány níže.
Kandidátní klíč
Kandidátní klíč je jednoduchý nebo složený klíč, který je jedinečný a minimální. Je jedinečný, protože žádné dva řádky v tabulce nesmí mít v žádném okamžiku stejnou hodnotu. Je minimální, protože k dosažení jedinečnosti je nutný každý sloupec.
Podle našeho příkladu databáze FIRMA, pokud je entita Zaměstnanec(EID, Jméno, Příjmení, SIN, Adresa, Telefon, Datum narození, Plat, ID oddělení), možné kandidátní klíče jsou:
- EID, SIN
- Jméno a příjmení – za předpokladu, že ve firmě není nikdo jiný se stejným jménem
- Příjmení a DepartmentID – za předpokladu, že dva lidé se stejným příjmením nepracují ve stejném oddělení
Složený klíč
Složený klíč je složen ze dvou nebo více atributů, ale musí být minimální.
Na příkladu z oddílu kandidátních klíčů jsou možné tyto složené klíče:
- Jméno a příjmení – za předpokladu, že ve firmě není nikdo jiný se stejným jménem
- Příjmení a ID oddělení – za předpokladu, že dvě osoby se stejným příjmením nepracují ve stejném oddělení
Primární klíč
Primární klíč je kandidátský klíč, který je vybrán návrhářem databáze, aby byl použit jako identifikační mechanismus pro celou množinu entit. Musí jednoznačně identifikovat tuply v tabulce a nesmí být nulový. Primární klíč je v ER modelu označen podtržením atributu.
- Kandidátní klíč je vybrán návrhářem k jednoznačné identifikaci tuplů v tabulce. Nesmí být nulový.
- Klíč vybírá návrhář databáze, aby byl použit jako identifikační mechanismus pro celou množinu entit. Označuje se jako primární klíč. Tento klíč je v ER modelu označen podtržením atributu.
V následujícím příkladu je primárním klíčem EID:
Zaměstnanec(EID, Jméno, Příjmení, SIN, Adresa, Telefon, Datum narození, Plat, ID oddělení)
Sekundární klíč
Sekundární klíč je atribut používaný výhradně pro účely vyhledávání (může být složený), např:
Alternate key
Alternate keys are all candidate keys not chosen as the primary key.
Foreign key
Cizí klíč (FK) je atribut v tabulce, který odkazuje na primární klíč v jiné tabulce NEBO může být nulový. Cizí i primární klíč musí být stejného datového typu.
V níže uvedeném příkladu databáze FIRMA je cizím klíčem DepartmentID:
Zaměstnanec(EID, Jméno, Příjmení, SIN, Adresa, Telefon, Datum narození, Plat, DepartmentID)
Nulový
Nulový klíč je speciální symbol nezávislý na datovém typu, který znamená buď neznámý, nebo nepoužitelný. Neznamená nulu nebo prázdné místo. Mezi vlastnosti null patří např:
- Nulový údaj
- Není přípustný v primárním klíči
- Měl by být vynechán v jiných atributech
- Může představovat
- Neznámou hodnotu atributu
- Známou, ale chybějící, hodnotu atributu
- Podmínku „neplatí“
- Může způsobit problémy při použití funkcí jako COUNT, AVERAGE a SUM
- Může způsobit logické problémy při propojení relačních tabulek
Poznámka: Výsledek porovnávací operace je nulový, pokud je některý z argumentů nulový. Výsledkem aritmetické operace je null, když je kterýkoli z argumentů null (s výjimkou funkcí, které null ignorují).
Příklad použití null
Pomocí tabulky Platy (Salary_tbl) na obrázku 8.6 můžete sledovat příklad použití null.
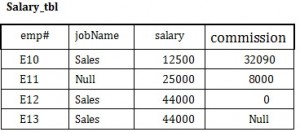
Na začátku najděte všechny zaměstnance (emp#) v oddělení Sales (ve sloupci jobName), jejichž plat plus provize jsou větší než 30 000 Kč.
- SELECT emp# FROM Salary_tbl
- WHERE jobName = Sales AND
- (provize + plat) > 30,000 -> E10 a E12
Tento výsledek nezahrnuje E13 kvůli nulové hodnotě ve sloupci provize. Abychom zajistili zahrnutí řádku s nulovou hodnotou, musíme se podívat na jednotlivá pole. Sečtením provize a platu zaměstnance E13 bude výsledkem nulová hodnota. Řešení je uvedeno níže.
Vztahy
Vztahy jsou lepidlem, které drží tabulky pohromadě. Používají se k propojení souvisejících informací mezi tabulkami.
Síla vztahů je založena na tom, jak je definován primární klíč související entity. Slabý neboli neidentifikovatelný vztah existuje, pokud primární klíč související entity neobsahuje složku primárního klíče nadřazené entity. Příklady firemních databází zahrnují:
- Customer(CustID, CustName)
- Order(OrderID, CustID, Date)
Silný neboli identifikační vztah existuje, pokud primární klíč související entity obsahuje komponentu primárního klíče nadřazené entity. Příklady zahrnují:
- Course(CrsCode, DeptCode, Description)
- Class(CrsCode, Section, ClassTime…)
Typy vztahů
Níže jsou uvedeny popisy různých typů vztahů.
Vztah jedna ku mnoha (1:M)
Vztah jedna ku mnoha (1:M) by měl být normou v každém návrhu relační databáze a vyskytuje se ve všech relačních databázových prostředích. Například jedno oddělení má mnoho zaměstnanců. Na obrázku 8.7 je znázorněn vztah jednoho z těchto zaměstnanců k oddělení.
Vztah jedna k jedné (1:1)
Vztah jedna k jedné (1:1) je vztah jedné entity pouze k jedné jiné entitě a naopak. Měl by být vzácný v každém návrhu relační databáze. Ve skutečnosti může znamenat, že dvě entity ve skutečnosti patří do stejné tabulky.
Příklad z databáze FIRMY je jeden zaměstnanec spojen s jedním manželem a jeden manžel je spojen s jedním zaměstnancem.
Vztah mnoho k mnoha (M:N)
V případě vztahu mnoho k mnoha zvažte následující body:
- V relačním modelu nemůže být implementován jako takový.
- Může být změněn na dva vztahy 1:M.
- Může být implementována rozdělením, aby vznikla sada vztahů 1:M.
- Obsahuje implementaci složené entity.
- Vytváří dva nebo více vztahů 1:M.
- Tabulka složené entity musí obsahovat alespoň primární klíče původních tabulek.
- Spojovací tabulka obsahuje více výskytů hodnot cizích klíčů.
- Podle potřeby lze přiřadit další atributy.
- Vytvořením složené entity nebo přemosťující entity se lze vyhnout problémům vlastním vztahu M:N. Například zaměstnanec může pracovat na mnoha projektech NEBO na projektu může pracovat mnoho zaměstnanců v závislosti na obchodních pravidlech. Nebo student může mít mnoho tříd a třída může mít mnoho studentů.
Obrázek 8.8 ukazuje další jiný aspekt vztahu M:N, kdy zaměstnanec má různá data zahájení pro různé projekty. Proto potřebujeme tabulku JOIN, která obsahuje EID, kód a datum zahájení.
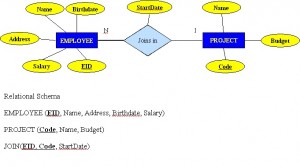
Příklad mapování binárního typu vztahu M:N
- Pro každý binární vztah M:N určete dva vztahy.
- A a B představují dva typy entit účastnících se R.
- Vytvořte nový vztah S, který bude reprezentovat R.
- S musí obsahovat PK A a B. Ty společně mohou být PK v tabulce S NEBO tyto společně s dalším jednoduchým atributem v nové tabulce R mohou být PK.
- Kombinace primárních klíčů (A a B) bude tvořit primární klíč tabulky S.
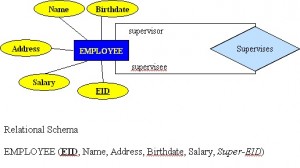
Unární vztah (rekurzivní)
Unární vztah, nazývaný také rekurzivní, je takový vztah, ve kterém existuje vztah mezi výskyty stejné množiny entit. V tomto vztahu jsou primární a cizí klíče stejné, ale představují dvě entity s různými rolemi. Příklad viz obrázek 8.9.
Pro některé entity v unárním vztahu může být vytvořen samostatný sloupec, který odkazuje na primární klíč stejné množiny entit.
Ternární vztahy
Ternární vztah je typ vztahu, který zahrnuje vztahy mnoho k mnoha mezi třemi tabulkami.
Příklad mapování ternárního typu vztahu naleznete na obrázku 8.10. Všimněte si, že n-ární znamená více tabulek ve vztahu. (Pamatujte, že N = mnoho.)
- Pro každý n-ární (> 2) vztah vytvořte nový vztah, který bude tento vztah reprezentovat.
- Primární klíč nového vztahu je kombinací primárních klíčů zúčastněných entit, které drží stranu N (mnoho).
- Ve většině případů n-árního vztahu drží všechny zúčastněné entity stranu many.
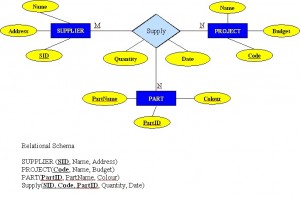
charakteristické entity:
kompozitní atributy: atributy, které se skládají z hierarchie atributů
kompozitní klíč: skládá se ze dvou nebo více atributů, ale musí být minimální
závislé entity: Tyto entity jsou svým významem závislé na jiných tabulkách
odvozené atributy: atributy, které obsahují hodnoty vypočtené z jiných atributů
odvozené entity: viz závislé entity
EID: identifikace zaměstnance (ID)
entita: věc nebo objekt v reálném světě s nezávislou existencí, kterou lze odlišit od jiných objektů
datový model vztahů entit (ER): nazývá se také ER schéma, jsou reprezentovány ER diagramy. Ty se dobře hodí k modelování dat pro použití s databázemi.
schéma vztahů entit: viz datový model vztahů entit
soubor entit:soubor entit určitého typu v určitém okamžiku
typ entit: soubor podobných entit
zahraniční klíč (FK): atribut v tabulce, který odkazuje na primární klíč v jiné tabulce NEBO může být nulový
nezávislá entita:
jádro: viz nezávislá entita
klíč: atribut nebo skupina atributů, jejichž hodnoty lze použít k jednoznačné identifikaci jednotlivé entity v souboru entit
vícehodnotové atributy: atributy, které mají pro každou entitu sadu hodnot
n-ární: více tabulek ve vztahu
null:
rekurzivní vztah: viz unární vztah
vztahy: asociace nebo interakce mezi entitami; používá se k propojení souvisejících informací mezi tabulkami
síla vztahu: na základě toho, jak je definován primární klíč související entity
sekundární klíč atribut používaný výhradně pro účely vyhledávání
jednoduché atributy: čerpané z domén atomických hodnot
SIN: číslo sociálního pojištění
jednohodnotové atributy: viz jednoduché atributy
uložený atribut: fyzicky uložený v databázi
ternární vztah: typ vztahu, který zahrnuje vztahy mnoho k mnoha mezi třemi tabulkami.
unární vztah: takový, ve kterém existuje vztah mezi výskyty stejné množiny entit.
- Na jakých dvou konceptech je založeno ER modelování
- Báze dat na obrázku 8.11 se skládá ze dvou tabulek. Pomocí tohoto obrázku odpovězte na otázky 2.1 až 2.5.
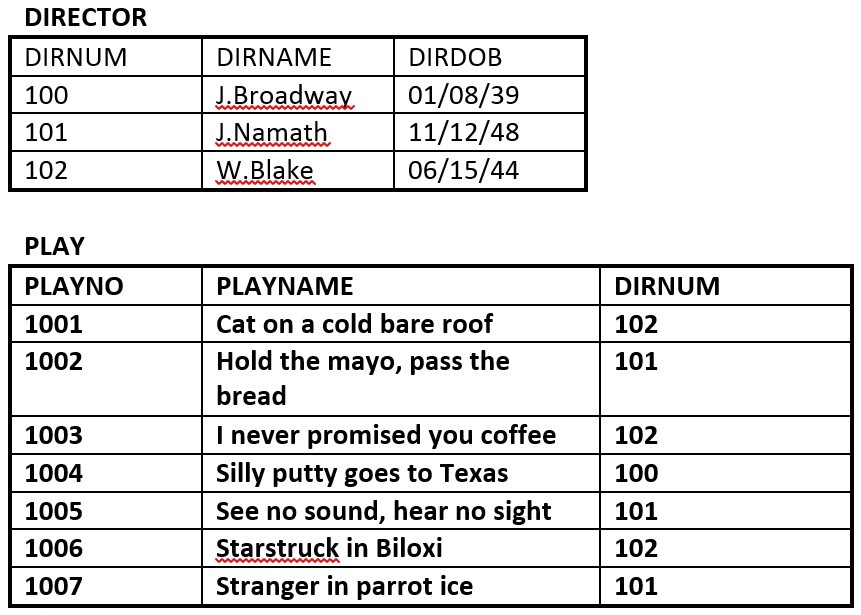
Obrázek 8.11. Tabulky Director a Play pro otázku 2, autor A. Watt. - Identifikujte primární klíč pro každou tabulku.
- Identifikujte cizí klíč v tabulce PLAY.
- Identifikujte kandidátní klíče v obou tabulkách.
- Nakreslete ER model.
- Vykazuje tabulka PLAY referenční integritu? Proč nebo proč ne?
- Definujte následující pojmy (pro některé z nich možná budete muset použít internet):
schema
hostitelský jazyk
podjazyk dat
jazyk definice dat
jednotkový vztah
cizí klíč
virtuální vztah
spojitost
kompozitní klíč
spojovací tabulka - Databáze společnosti RRE Trucking Company obsahuje tři tabulky na obrázku 8.12. Pomocí obrázku 8.12 odpovězte na otázky 4.1 až 4.5.
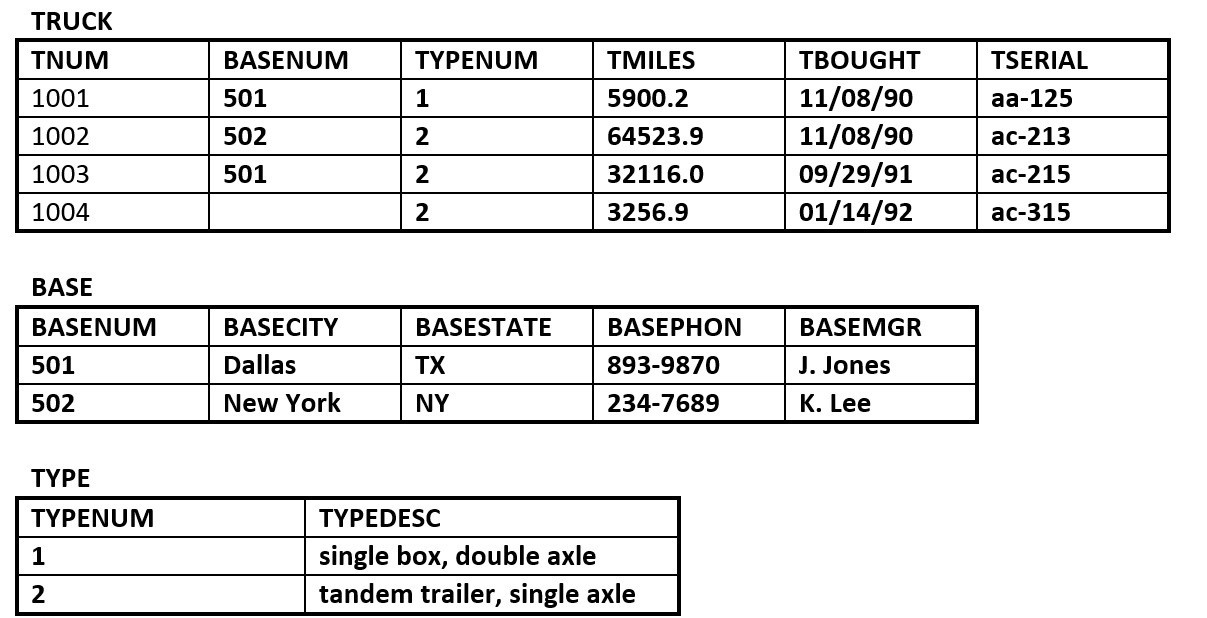
Obrázek 8.12. Tabulky Truck, Base a Type pro otázku 4 podle A. Watta. - Uveďte primární a cizí klíč(e) pro každou tabulku.
- Vykazuje tabulka TRUCK integritu entit a referenční integritu? Proč nebo proč ne? Vysvětlete svou odpověď.
- Jaký vztah existuje mezi tabulkami TRUCK a BASE?
- Kolik entit obsahuje tabulka TRUCK?
- Identifikujte kandidátský klíč (klíče) tabulky TRUCK.
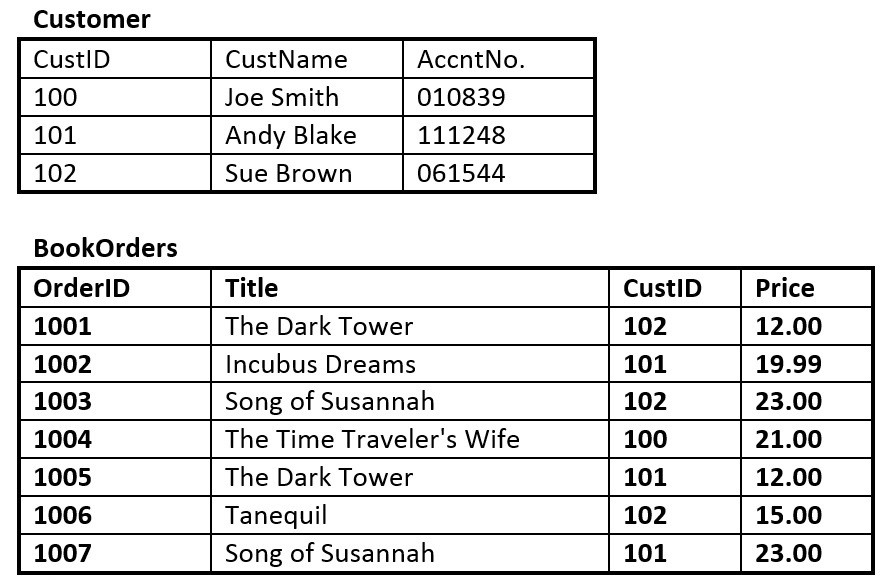
Obrázek 8.13: Jaký je vztah mezi tabulkami TRUCK a BASE? Tabulky Customer a BookOrders pro otázku 5 podle A. Watta.
- Předpokládejte, že používáte databázi na obrázku 8.13 složenou ze dvou tabulek. Použijte obrázek 8.13 k zodpovězení otázek 5.1 až 5.6.
- Identifikujte primární klíč v každé tabulce.
- Identifikujte cizí klíč v tabulce BookOrders.
- Jsou v obou tabulkách nějaké kandidátní klíče?
- Nakreslete ER model.
- Vykazuje tabulka BookOrders referenční integritu? Proč nebo proč ne?
- Obsahují tabulky nadbytečná data? Pokud ano, které tabulky a jaká jsou to redundantní data?
- Podívejte se na tabulku studentů na obrázku 8.14 a uveďte všechny možné kandidátní klíče. Proč jste vybrali právě tyto?
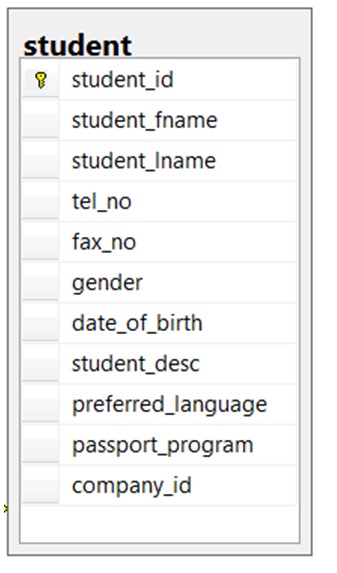
Obrázek 8.14. Studentská tabulka pro otázku 6, autor A. Watt. 
Obrázek 8.15. ERD školní databáze pro otázky 7-10, autor A. Watt. Pomocí ERD školní databáze na obrázku 8.15 zodpovězte otázky 7 až 10.
- Uveďte všechna jádra a závislé a charakteristické entity v ERD.
- Které z tabulek přispívají ke slabým vztahům? Silné vztahy?
- Podíváme-li se na každou z tabulek v databázi školy na obrázku 8.15, který atribut může mít hodnotu NULL? Proč?
- Které z tabulek byly vytvořeny v důsledku vztahů mnoho k mnoha?
Také viz Příloha B: Ukázková cvičení ERD
Attribution
Tato kapitola Návrh databáze (včetně obrázků, pokud není uvedeno jinak) je odvozenou kopií Data Modeling Using Entity-Relationship Model od Nguyen Kim Anh s licencí Creative Commons Attribution License 3.0 license
Následující materiál napsala Adrienne Watt:
- Kapitola a příklad Nulls
- Klíčové pojmy
- Cvičení
.