- Populaarisia strategioita puuttuvien arvojen tilastolliseksi imputoinniksi tietokokonaisuuksissa.
- 2- Imputointi käyttäen (keskiarvo/mediaani) arvoja:
- 3- Imputation Using (Most Frequent) or (Zero/Constant) Values:
- Miten se toimii?
- 5- Imputointi käyttäen Multivariate Imputation by Chained Equation (MICE)
- 6- Imputointi syväoppimista käyttäen (Datawig):
- Stokastinen regressioimputointi:
- Extrapolointi ja interpolointi:
- Hot-Deck-imputointi:
Populaarisia strategioita puuttuvien arvojen tilastolliseksi imputoinniksi tietokokonaisuuksissa.
Monissa reaalimaailman tietokokonaisuuksissa voi esiintyä puuttuvia arvoja erilaisista syistä. Ne on usein koodattu NaN:nä, tyhjinä tai muina sijoittimina. Mallin kouluttaminen aineistolla, jossa on paljon puuttuvia arvoja, voi vaikuttaa ratkaisevasti koneoppimismallin laatuun. Jotkin algoritmit, kuten scikit-learn-estimaattorit, olettavat, että kaikki arvot ovat numeerisia ja että niillä on ja pitää sisällään merkityksellinen arvo.
Yksi tapa käsitellä tätä ongelmaa on päästä eroon havainnoista, joissa on puuttuvia tietoja. Vaarana on kuitenkin menettää datapisteitä, joissa on arvokasta tietoa. Parempi strategia olisi imputoida puuttuvat arvot. Toisin sanoen meidän on pääteltävä nämä puuttuvat arvot olemassa olevasta datan osasta. Puuttuvia tietoja on kolmea päätyyppiä:
- Puuttuu täysin satunnaisesti (MCAR)
- Puuttuu satunnaisesti (MAR)
- Ei puutu satunnaisesti (NMAR)
Tässä artikkelissa keskityn kuitenkin 6:een suosittuun tapaan datan imputoimiseen poikkileikkaustietoaineistoissa ( aikasarjatietoaineisto on eri juttu ).
Tämä on helppo. Annat vain algoritmin käsitellä puuttuvat tiedot. Jotkut algoritmit voivat ottaa puuttuvat arvot huomioon ja oppia parhaat imputointiarvot puuttuville tiedoille koulutuksen tappion vähentämisen perusteella (esim. XGBoost). Joillakin muilla on mahdollisuus jättää ne huomiotta (esim. LightGBM – use_missing=false). Toiset algoritmit joutuvat kuitenkin paniikkiin ja heittävät virheilmoituksen, jossa valitetaan puuttuvista arvoista (esim. Scikit learn – LinearRegression). Tällöin sinun on käsiteltävä puuttuvat tiedot ja puhdistettava ne ennen niiden syöttämistä algoritmille.
Katsotaanpa muita tapoja imputoida puuttuvat arvot ennen harjoittelua:
Huomautus: Kaikissa alla olevissa esimerkeissä käytetään Kalifornian asuntotietoaineistoa (California Housing Dataset) Scikit-learnista.
2- Imputointi käyttäen (keskiarvo/mediaani) arvoja:
Tämä toimii laskemalla sarakkeen ei-puuttuvien arvojen keskiarvo/mediaani ja korvaamalla sitten puuttuvat arvot kussakin sarakkeessa erikseen ja muista riippumatta. Sitä voidaan käyttää vain numeeristen tietojen kanssa.

Pros:
- Helppo ja nopea.
- Toimii hyvin pienillä numeerisilla aineistoilla.
Cons:
- Ei ota huomioon piirteiden välisiä korrelaatioita. Se toimii vain saraketasolla.
- Antaa huonoja tuloksia koodatuille kategorisille piirteille (ÄLÄ käytä sitä kategorisille piirteille).
- Ei ole kovin tarkka.
- Ei ota huomioon imputaatioiden epävarmuutta.
3- Imputation Using (Most Frequent) or (Zero/Constant) Values:
Most Frequent on toinen tilastollinen strategia puuttuvien arvojen imputointiin ja KYLLÄ!!! Se toimii kategoristen piirteiden (merkkijonojen tai numeeristen esitysten) kanssa korvaamalla puuttuvat tiedot kussakin sarakkeessa useimmin esiintyvillä arvoilla.
Pros:
- Toimii hyvin kategoristen piirteiden kanssa.
Miinukset:
- Se ei myöskään ota huomioon piirteiden välisiä korrelaatioita.
- Voi tuoda vääristymiä tietoihin.
Nolla- tai vakioimputointi – kuten nimestä voi päätellä – se korvaa puuttuvat arvot joko nollalla tai jollakin määrittelemälläsi vakioarvolla

>
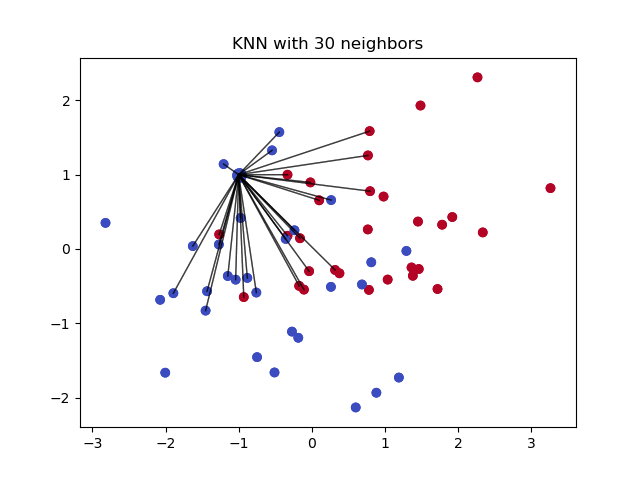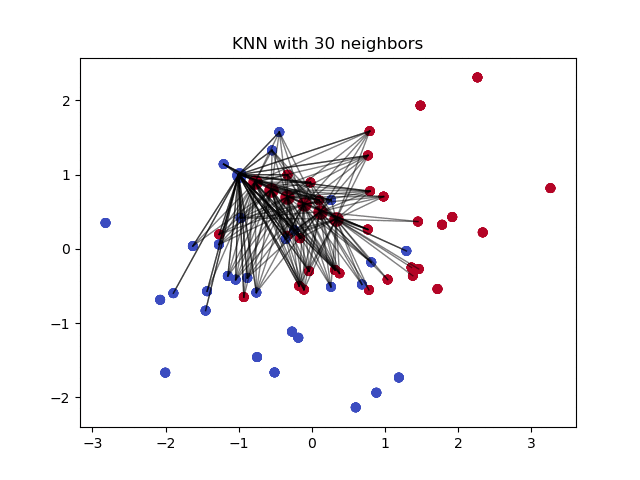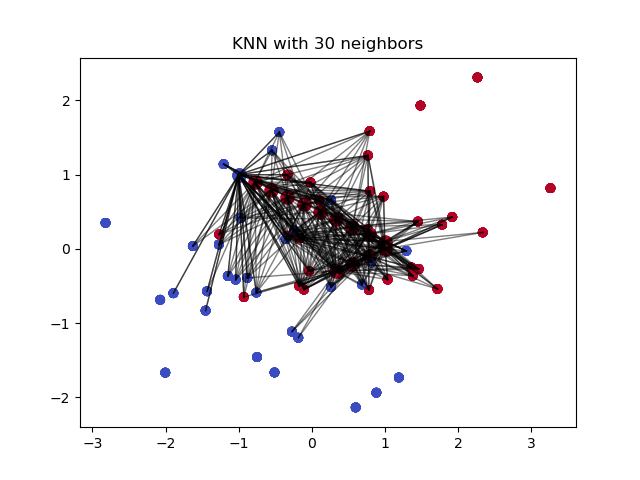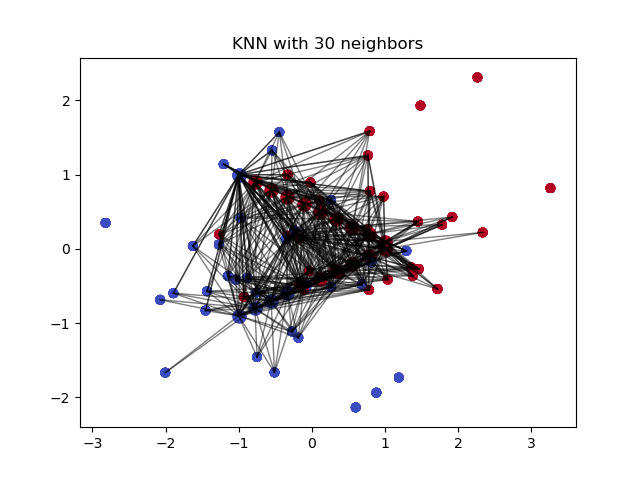
4- Imputointi k-NN:n avulla:
K lähimmät naapurit on algoritmi, jota käytetään yksinkertaiseen luokitteluun. Algoritmi käyttää ”ominaisuuksien samankaltaisuutta” kaikkien uusien datapisteiden arvojen ennustamiseen. Tämä tarkoittaa sitä, että uudelle pisteelle annetaan arvo sen perusteella, kuinka paljon se muistuttaa koulutusjoukon pisteitä. Tämä voi olla erittäin hyödyllistä ennustettaessa puuttuvia arvoja etsimällä k:n lähimmät naapurit havainnolle, josta puuttuvat tiedot puuttuvat, ja sitten imputoimalla ne naapurustossa olevien ei-puuttuvien arvojen perusteella. Katsotaanpa esimerkkikoodia, jossa käytetään Impyute-kirjastoa, joka tarjoaa yksinkertaisen ja helpon tavan käyttää KNN:ää imputointiin:
Miten se toimii?
Se luo peruskeskiarvon imputoinnin ja käyttää sitten tuloksena syntyvää täydellistä listaa rakentaakseen KDTreen. Sitten se käyttää tuloksena saatua KDTree-puuta lähimpien naapureiden (NN) laskemiseen. Kun se on löytänyt k-NN:t, se ottaa niistä painotetun keskiarvon.
Pros:
- Voi olla paljon tarkempi kuin keskiarvo-, mediaani- tai tiheimmän esiintymistiheyden imputaatiomenetelmät (Riippuu aineistosta).
Miinukset:
- Laskennallisesti kallis. KNN toimii tallentamalla koko harjoitusaineiston muistiin.
- K-NN on melko herkkä aineiston poikkeaville arvoille (toisin kuin SVM)
5- Imputointi käyttäen Multivariate Imputation by Chained Equation (MICE)
Tämä imputointityyppi toimii siten, että puuttuvat tiedot täydennetään useaan kertaan. Moninkertaiset imputaatiot (Multiple Imputations, MI) ovat paljon parempia kuin yksittäinen imputaatio, koska ne mittaavat puuttuvien arvojen epävarmuutta paremmin. Ketjutettujen yhtälöiden lähestymistapa on myös hyvin joustava, ja se pystyy käsittelemään eri tietotyyppien muuttujia (eli jatkuvia tai binäärisiä) sekä monimutkaisuuksia, kuten rajoja tai tutkimuksen ohitusmalleja. Lisätietoa algoritmin mekaniikasta saa tutkimusjulkaisusta

6- Imputointi syväoppimista käyttäen (Datawig):
Tämä menetelmä toimii erittäin hyvin kategoristen ja ei-numeeristen piirteiden kanssa. Se on kirjasto, joka oppii koneoppimismalleja Deep Neural Networksin avulla imputoimaan puuttuvat arvot datakehyksessä. Se tukee myös sekä CPU:ta että GPU:ta harjoittelua varten.
Pros:
- Osa:
- Osa:
- Tämässä on joitain funktioita, jotka pystyvät käsittelemään kategorista dataa (Feature Encoder).
- Se tukee suorittimia ja grafiikkasuorittimia.
Miinukset:
- Yksittäinen sarakeimputointi.
- Voi olla melko hidas suurilla tietokokonaisuuksilla.
- Sinun on määritettävä sarakkeet, jotka sisältävät tietoa kohdesarakkeesta, joka imputoidaan.
Stokastinen regressioimputointi:
Se on melko samanlainen kuin regressioimputointi, joka yrittää ennustaa puuttuvat arvot regressioimputoimalla sen muista samassa tietokokonaisuudessa olevista toisiinsa liittyvistä muuttujista sekä jostain satunnaisesta jäännösarvosta.
Extrapolointi ja interpolointi:
Se pyrkii estimoimaan arvoja muista havainnoista tunnettujen datapisteiden diskreetin joukon vaihteluvälillä.
Hot-Deck-imputointi:
Toimii valitsemalla puuttuvan arvon satunnaisesti toisiinsa liittyvien ja samankaltaisten muuttujien joukosta.
Johtopäätöksenä voidaan todeta, että ei ole olemassa mitään täydellistä tapaa kompensoida puuttuvia arvoja tietokokonaisuuksilta. Kukin strategia voi toimia paremmin tietyissä tietokokonaisuuksissa ja puuttuvien tietojen tyypeissä, mutta se voi toimia paljon huonommin toisentyyppisissä tietokokonaisuuksissa. On olemassa joitakin asetettuja sääntöjä, joiden avulla voidaan päättää, mitä strategiaa käytetään tietyntyyppisille puuttuville arvoille, mutta sen lisäksi kannattaa kokeilla ja tarkistaa, mikä malli toimii parhaiten omalle tietokokonaisuudellesi.
- Osa: