In questo blog, discuteremo i concetti di base della Regressione Logistica e che tipo di problemi può aiutarci a risolvere.

La regressione logistica è un algoritmo di classificazione usato per assegnare osservazioni ad un insieme discreto di classi. Alcuni esempi di problemi di classificazione sono Email spam o non spam, Frode o non Frode nelle transazioni online, Tumore maligno o benigno. La regressione logistica trasforma il suo output usando la funzione sigmoide logistica per restituire un valore di probabilità.
Quali sono i tipi di regressione logistica
- Binario (es. Tumore maligno o benigno)
- Funzioni multilineari failsClass (es. Gatti, cani o pecore)
Regressione logistica
La regressione logistica è un algoritmo di apprendimento automatico che viene utilizzato per i problemi di classificazione, è un algoritmo di analisi predittiva e basato sul concetto di probabilità.

Possiamo chiamare una Regressione Logistica un modello di Regressione Lineare ma la Regressione Logistica usa una funzione di costo più complessa, questa funzione di costo può essere definita come ‘funzione Sigmoide’ o anche conosciuta come ‘funzione logistica’ invece di una funzione lineare.
L’ipotesi della regressione logistica tende a limitare la funzione di costo tra 0 e 1. Perciò le funzioni lineari non riescono a rappresentarla perché può avere un valore maggiore di 1 o minore di 0, il che non è possibile secondo l’ipotesi della regressione logistica.
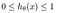
Cos’è la funzione Sigmoide?
Per mappare i valori predetti in probabilità, usiamo la funzione Sigmoide. La funzione mappa qualsiasi valore reale in un altro valore tra 0 e 1. Nel machine learning, usiamo la sigmoide per mappare le previsioni alle probabilità.


Rappresentazione dell’ipotesi
Quando usiamo la regressione lineare abbiamo usato una formula dell’ipotesi cioè
hΘ(x) = β₀ + β₁X
Per la regressione logistica la modifichiamo un po’ cioè.e.
σ(Z) = σ(β₀ + β₁X)
Abbiamo previsto che la nostra ipotesi darà valori tra 0 e 1.
Z = β₀ + β₁X
hΘ(x) = sigmoide(Z)
cioè hΘ(x) = 1/(1 + e^-(β₀ + β₁X)

Bordo di decisione
Ci aspettiamo che il nostro classificatore ci dia un insieme di output o classi basate sulla probabilità quando passiamo gli input attraverso una funzione di predizione e restituisce un punteggio di probabilità tra 0 e 1.
Per esempio, abbiamo 2 classi, prendiamole come gatti e cani (1 – cane, 0 – gatti). In pratica decidiamo con un valore di soglia sopra il quale classifichiamo i valori nella classe 1 e se il valore va sotto la soglia allora lo classifichiamo nella classe 2.
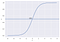
Come mostrato nel grafico sopra abbiamo scelto la soglia come 0.5, se la funzione di predizione restituisse un valore di 0.7 allora classificheremmo questa osservazione come Classe 1 (CANE). Se la nostra predizione restituisse un valore di 0,2 allora classificheremmo l’osservazione come Classe 2 (GATTO).
Funzione di costo
Abbiamo imparato la funzione di costo J(θ) nella regressione lineare, la funzione di costo rappresenta l’obiettivo di ottimizzazione cioè creiamo una funzione di costo e la minimizziamo in modo da poter sviluppare un modello accurato con un errore minimo.
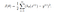
Se proviamo a usare la funzione di costo della regressione lineare nella ‘Regressione Logistica’ allora non sarebbe di nessuna utilità perché finirebbe per essere una funzione non convessa con molti minimi locali, in cui sarebbe molto difficile minimizzare il valore del costo e trovare il minimo globale.

Per la regressione logistica, la funzione Costo è definita come:
-log(hθ(x)) se y = 1
-log(1-hθ(x)) se y = 0
