- Popularne strategie statystycznej imputacji brakujących wartości w zbiorze danych.
- 2- Imputation Using (Mean/Median) Values:
- 3- Imputation Using (Most Frequent) or (Zero/Constant) Values:
- 4- Imputacja z użyciem k-NN:
- Jak to działa?
- 5-. Imputacja z wykorzystaniem metody Multivariate Imputation by Chained Equation (MICE)
- 6- Imputation Using Deep Learning (Datawig):
- Stochastyczna imputacja regresji:
- Extrapolacja i interpolacja:
- Hot-Deck imputacja:
Popularne strategie statystycznej imputacji brakujących wartości w zbiorze danych.
Wiele zbiorów danych w świecie rzeczywistym może zawierać brakujące wartości z różnych powodów. Często są one kodowane jako NaNs, puste miejsca lub jakiekolwiek inne placeholdery. Trening modelu z zestawem danych, który zawiera wiele brakujących wartości może drastycznie wpłynąć na jakość modelu uczenia maszynowego. Niektóre algorytmy, takie jak estymatory scikit-learn, zakładają, że wszystkie wartości są numeryczne i mają i przechowują znaczące wartości.
Jednym ze sposobów radzenia sobie z tym problemem jest pozbycie się obserwacji, które mają brakujące dane. Jednakże, ryzykujesz utratę punktów danych z cennymi informacjami. Lepszą strategią byłoby imputowanie brakujących wartości. Innymi słowy, musimy wywnioskować te brakujące wartości z istniejącej części danych. Istnieją trzy główne typy brakujących danych:
- Brak całkowicie losowy (MCAR)
- Brak losowy (MAR)
- Brak losowy (NMAR)
Jednakże w tym artykule skupię się na 6 popularnych sposobach imputacji danych dla przekrojowych zbiorów danych (zbiory danych szeregów czasowych to inna historia).
To jest łatwe. Po prostu pozwalasz algorytmowi obsługiwać brakujące dane. Niektóre algorytmy mogą uwzględniać brakujące wartości i uczyć się najlepszych wartości imputacji dla brakujących danych w oparciu o redukcję straty szkoleniowej (np. XGBoost). Niektóre inne mają opcję ignorowania ich (np. LightGBM – use_missing=false). Jednakże, inne algorytmy będą panikować i rzucać błąd narzekając na brakujące wartości (np. Scikit learn – LinearRegression). W takim przypadku trzeba będzie obsłużyć brakujące dane i oczyścić je przed podaniem do algorytmu.
Zobaczmy kilka innych sposobów imputowania brakujących wartości przed treningiem:
Uwaga: Wszystkie poniższe przykłady używają California Housing Dataset z Scikit-learn.
2- Imputation Using (Mean/Median) Values:
To działa poprzez obliczenie średniej/mediany wartości niepomijalnych w kolumnie, a następnie zastąpienie brakujących wartości w każdej kolumnie oddzielnie i niezależnie od innych. Można jej używać tylko z danymi liczbowymi.

Zalety:
- Łatwa i szybka.
- Dobrze sprawdza się w przypadku małych numerycznych zbiorów danych.
Cons:
- Nie uwzględnia korelacji między cechami. Działa tylko na poziomie kolumn.
- Daje słabe wyniki na zakodowanych cechach kategorycznych (NIE używaj go na cechach kategorycznych).
- Nie jest bardzo dokładny.
- Nie uwzględnia niepewności w imputacjach.
3- Imputation Using (Most Frequent) or (Zero/Constant) Values:
Most Frequent jest kolejną strategią statystyczną do imputacji brakujących wartości i TAK!!! Działa z cechami kategorycznymi (ciągami znaków lub reprezentacjami liczbowymi) zastępując brakujące dane najczęstszymi wartościami w każdej kolumnie.
Pros:
- Dobrze działa z cechami kategorycznymi.
Cons:
- Nie uwzględnia również korelacji między cechami.
- Może wprowadzać błąd w danych.
Imputacja zerowa lub stała – jak sama nazwa wskazuje – zastępuje brakujące wartości zerem lub dowolną stałą wartością określoną przez użytkownika

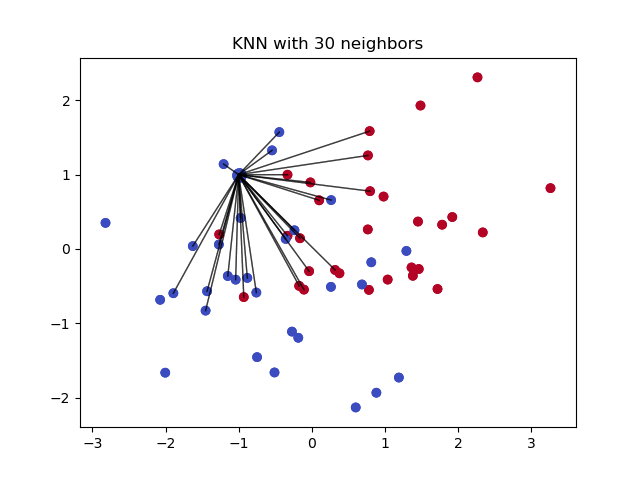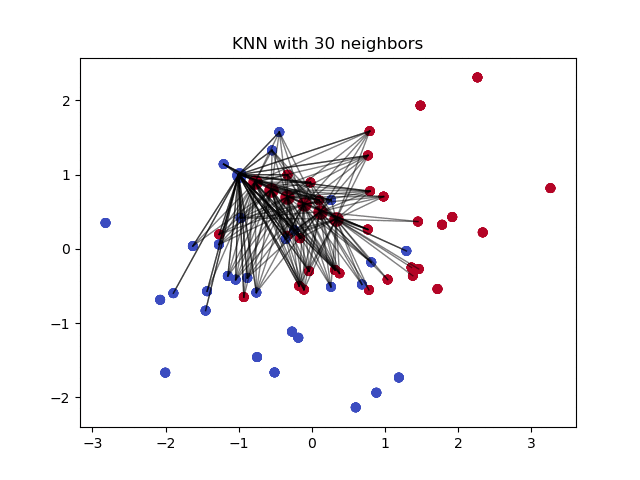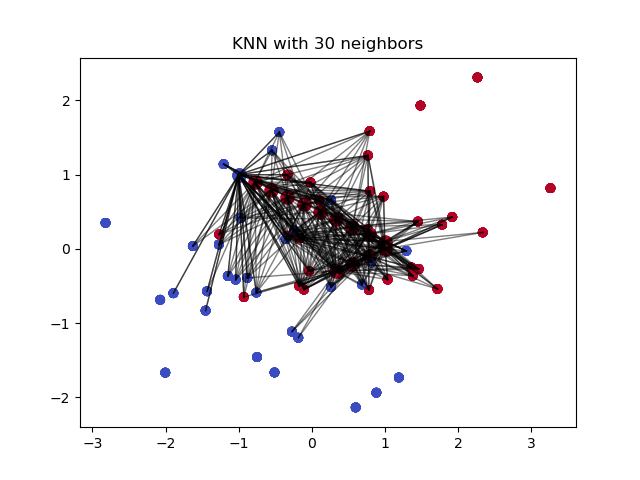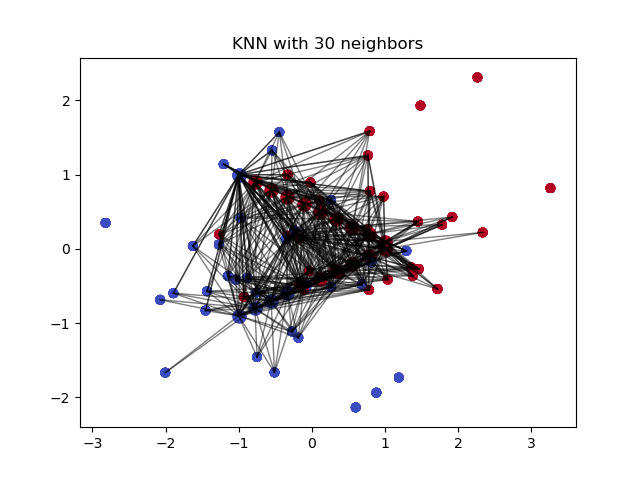
4- Imputacja z użyciem k-NN:
K nearest neighbours to algorytm, który jest używany do prostej klasyfikacji. Algorytm ten wykorzystuje „podobieństwo cech” do przewidywania wartości nowych punktów danych. Oznacza to, że nowemu punktowi przypisywana jest wartość na podstawie tego, jak bardzo jest on podobny do punktów w zbiorze treningowym. Może to być bardzo przydatne w przewidywaniu brakujących wartości poprzez znalezienie najbliższych sąsiadów obserwacji z brakującymi danymi, a następnie imputowanie ich w oparciu o niepomijające wartości w sąsiedztwie. Zobaczmy przykładowy kod wykorzystujący bibliotekę Impyute, która zapewnia prosty i łatwy sposób użycia KNN do imputacji:
Jak to działa?
Tworzy podstawową średnią imputacji, a następnie używa wynikowej kompletnej listy do skonstruowania KDTree. Następnie używa wynikowego drzewa KDTree do obliczenia najbliższych sąsiadów (NN). Po znalezieniu k-NNs, bierze średnią ważoną z nich.
Zalety:
- Może być znacznie dokładniejsza niż średnia, mediana lub najczęstsze metody imputacji (To zależy od zestawu danych).
Konsekwencje:
- Komputerowo kosztowne. KNN działa poprzez przechowywanie całego zbioru danych treningowych w pamięci.
- K-NN jest dość wrażliwy na wartości odstające w danych (w przeciwieństwie do SVM)
5-. Imputacja z wykorzystaniem metody Multivariate Imputation by Chained Equation (MICE)
Ten typ imputacji działa poprzez wielokrotne uzupełnianie brakujących danych. Wielokrotne imputacje (MI) są znacznie lepsze niż pojedyncza imputacja, ponieważ mierzą niepewność brakujących wartości w lepszy sposób. Podejście równań łańcuchowych jest również bardzo elastyczne i może obsługiwać różne zmienne o różnych typach danych (tj. ciągłe lub binarne), a także złożoności, takie jak granice lub wzorce pomijania ankiet. Więcej informacji na temat mechaniki algorytmu można znaleźć w dokumencie badawczym

6- Imputation Using Deep Learning (Datawig):
Ta metoda działa bardzo dobrze z cechami kategorycznymi i nienumerycznymi. Jest to biblioteka, która uczy się modeli uczenia maszynowego przy użyciu głębokich sieci neuronowych, aby imputować brakujące wartości w ramce danych. Obsługuje również zarówno CPU, jak i GPU do szkolenia.
Pros:
- Dość dokładna w porównaniu do innych metod.
- Ma pewne funkcje, które mogą obsługiwać dane kategoryczne (Feature Encoder).
- Obsługuje CPU i GPU.
Konsekwencje:
- Single Column imputation.
- Może być dość powolny w przypadku dużych zbiorów danych.
- Musisz określić kolumny, które zawierają informacje o kolumnie docelowej, która będzie imputowana.
Stochastyczna imputacja regresji:
Jest to dość podobne do imputacji regresji, która próbuje przewidzieć brakujące wartości przez regresję z innych powiązanych zmiennych w tym samym zbiorze danych plus pewna losowa wartość rezydualna.
Extrapolacja i interpolacja:
Próbuje oszacować wartości z innych obserwacji w zakresie dyskretnego zbioru znanych punktów danych.
Hot-Deck imputacja:
Działa poprzez losowy wybór brakującej wartości z zestawu powiązanych i podobnych zmiennych.
W podsumowaniu, nie ma idealnego sposobu na kompensację brakujących wartości w zbiorze danych. Każda strategia może działać lepiej dla pewnych zestawów danych i typów brakujących danych, ale może działać znacznie gorzej na innych typach zestawów danych. Istnieją pewne ustalone zasady, aby zdecydować, którą strategię zastosować dla poszczególnych typów brakujących wartości, ale poza tym należy eksperymentować i sprawdzić, który model działa najlepiej dla danego zbioru danych.
.