Model danych oparty na związkach encji (ER) istnieje od ponad 35 lat. Nadaje się on dobrze do modelowania danych do użytku z bazami danych, ponieważ jest dość abstrakcyjny i łatwo go omówić i wyjaśnić. Modele ER są łatwo przekładalne na relacje. Modele ER, zwane również schematami ER, są reprezentowane przez diagramy ER.
Modelowanie ER opiera się na dwóch pojęciach:
- Entities, zdefiniowane jako tabele przechowujące określone informacje (dane)
- Relacje, zdefiniowane jako stowarzyszenia lub interakcje między encjami
Oto przykład połączenia tych dwóch pojęć w modelu danych ER: Prof. Ba (encja) wykłada (relacja) kurs Systemy baz danych (encja).
Przez resztę tego rozdziału będziemy używać przykładowej bazy danych o nazwie baza danych FIRMA, aby zilustrować koncepcje modelu ER. Ta baza danych zawiera informacje o pracownikach, działach i projektach. Ważne punkty, na które należy zwrócić uwagę, obejmują:
- W firmie istnieje kilka działów. Każdy dział ma unikalną identyfikację, nazwę, lokalizację biura i konkretnego pracownika, który zarządza działem.
- Dział kontroluje wiele projektów, z których każdy ma unikalną nazwę, unikalny numer i budżet.
- Każdy pracownik ma imię i nazwisko, numer identyfikacyjny, adres, wynagrodzenie i datę urodzenia. Pracownik jest przypisany do jednego działu, ale może brać udział w kilku projektach. Musimy zapisać datę rozpoczęcia pracy pracownika w każdym projekcie. Musimy również znać bezpośredniego przełożonego każdego pracownika.
- Chcemy śledzić osoby zależne dla każdego pracownika. Każda osoba zależna ma imię, datę urodzenia i związek z pracownikiem.
- Entity, Entity Set i Entity Type
- Zależność od istnienia
- Rodzaje encji
- Atencje niezależne
- Ekspozycje zależne
- Elementy charakterystyczne
- Atrybuty
- Typy atrybutów
- Proste atrybuty
- Atrybuty złożone
- Atrybuty wielowartościowe
- Atrybuty pochodne
- Keys
- Typy kluczy
- Klucz kandydujący
- Klucz złożony
- Klucz główny
- Klucz drugorzędny
- Klucz alternatywny
- Klucz obcy
- Nulls
- Przykład użycia null
- Relacje
- Typy relacji
- Relacja jeden do wielu (1:M)
- Związek jeden do jednego (1:1)
- Związki wiele do wielu (M:N)
- Związek jednoargumentowy (rekurencyjny)
- Związki trójstronne
- Attribution
Entity, Entity Set i Entity Type
Entity to obiekt w świecie rzeczywistym o niezależnym istnieniu, który można odróżnić od innych obiektów. Podmiot może być
Podmioty mogą być klasyfikowane na podstawie ich siły. Podmiot jest uważany za słaby, jeśli jego tabele są zależne od istnienia.
- To znaczy, że nie może istnieć bez relacji z innym podmiotem
- Jego klucz główny pochodzi od klucza głównego podmiotu nadrzędnego
- Tabela Małżonek, w bazie danych FIRMA, jest słabym podmiotem, ponieważ jej klucz główny jest zależny od tabeli Pracownik. Bez odpowiadającego jej rekordu pracownika rekord współmałżonka nie istniałby.
Ekspozycja jest uważana za silną, jeśli może istnieć poza wszystkimi powiązanymi z nią encjami.
- Kercje są silnymi encjami.
- Tabela bez klucza obcego lub tabela zawierająca klucz obcy, który może zawierać null, jest silną encją
Innym terminem, który należy znać, jest typ encji, który określa zbiór podobnych encji.
Zbiór encji jest zbiorem encji typu encji w określonym momencie. W diagramie związków encji (ERD) typ encji jest reprezentowany przez nazwę w ramce. Na przykład na rysunku 8.1 typem encji jest EMPLOYEE.
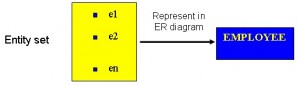
Zależność od istnienia
Istnienie encji jest zależne od istnienia encji powiązanej. Jest ona zależna od istnienia, jeśli ma obowiązkowy klucz obcy (tj. atrybut klucza obcego, który nie może mieć wartości null). Na przykład, w bazie danych FIRMA, encja Małżonek jest zależna od encji Pracownik.
Rodzaje encji
Powinieneś również znać różne rodzaje encji, w tym encje niezależne, encje zależne i encje charakterystyczne. Zostały one opisane poniżej.
Atencje niezależne
Atencje niezależne, zwane również jądrami, są szkieletem bazy danych. Są one tym, na czym opierają się inne tabele. Jądra mają następujące cechy:
- Są elementami konstrukcyjnymi bazy danych.
- Klucz główny może być prosty lub złożony.
- Klucz główny nie jest kluczem obcym.
- Nie zależą od innej encji, jeśli chodzi o ich istnienie.
Jeśli odniesiemy się z powrotem do naszej bazy danych FIRMA, przykłady niezależnej encji obejmują tabelę Klienci, tabelę Pracownicy lub tabelę Produkty.
Ekspozycje zależne
Ekspozycje zależne, zwane również pochodnymi, zależą od innych tabel w zakresie ich znaczenia. Te encje mają następujące cechy:
- Ekspozycje zależne są używane do łączenia dwóch jąder razem.
- Mówi się, że są zależne od istnienia dwóch lub więcej tabel.
- Zależności wiele do wielu stają się tabelami asocjacyjnymi z co najmniej dwoma kluczami obcymi.
- Mogą zawierać inne atrybuty.
- Klucz obcy identyfikuje każdą powiązaną tabelę.
- Istnieją trzy opcje dla klucza głównego:
- Użyj kompozytu kluczy obcych tabel stowarzyszonych, jeśli jest unikalny
- Użyj kompozytu kluczy obcych i kolumny kwalifikującej
- Utwórz nowy prosty klucz główny
Elementy charakterystyczne
Elementy charakterystyczne dostarczają więcej informacji o innej tabeli. Te encje mają następujące cechy:
- Oprezentują wielowartościowe atrybuty.
- Opisują inne encje.
- Zazwyczaj mają relację jeden do wielu.
- Klucz obcy jest używany do dalszej identyfikacji charakteryzowanej tabeli.
- Opcje dla klucza podstawowego są następujące:
- Użyj złożonego klucza obcego plus kolumny kwalifikującej
- Utwórz nowy prosty klucz podstawowy. W bazie danych FIRMA mogą to być:
- Employee (EID, Name, Address, Age, Salary) – EID jest prostym kluczem podstawowym.
- EmployeePhone (EID, Phone) – EID jest częścią złożonego klucza podstawowego. Tutaj EID jest również kluczem obcym.
Atrybuty
Każda encja jest opisana przez zestaw atrybutów (np. Pracownik = (Nazwisko, Adres, Data urodzenia (Wiek), Wynagrodzenie).
Każdy atrybut ma nazwę i jest związany z encją oraz domeną legalnych wartości. Jednak informacja o domenie atrybutów nie jest prezentowana na ERD.
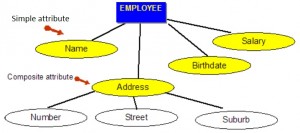
W diagramie związków encji, przedstawionym na rysunku 8.2, każdy atrybut jest reprezentowany przez owal z nazwą w środku.

Typy atrybutów
Istnieje kilka typów atrybutów, z którymi należy się zapoznać. Niektóre z nich należy pozostawić takimi, jakimi są, ale niektóre należy dostosować, aby ułatwić reprezentację w modelu relacyjnym. W tej pierwszej sekcji omówimy typy atrybutów. Później omówimy naprawianie atrybutów w celu ich prawidłowego dopasowania do modelu relacyjnego.
Proste atrybuty
Proste atrybuty to atrybuty zaczerpnięte z domen wartości atomowych; są one również nazywane atrybutami jednowartościowymi. W bazie danych FIRMA, przykładem takiego atrybutu byłoby: Imię = {John} ; Wiek = {23}
Atrybuty złożone
Atrybuty złożone to takie, które składają się z hierarchii atrybutów. Używając naszego przykładu bazy danych i pokazanego na rysunku 8.3, adres może składać się z numeru, ulicy i przedmieścia. Byłoby to więc zapisane jako → Adres = {59 + 'Meek Street’ + 'Kingsford’}
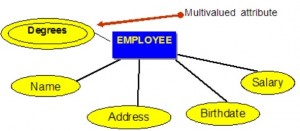
Atrybuty wielowartościowe
Atrybuty wielowartościowe to atrybuty, które mają zestaw wartości dla każdej encji. Przykładem atrybutu wielowartościowego z bazy danych FIRMA, jak widać na rysunku 8.4, są stopnie naukowe pracownika: BSc, MIT, PhD.
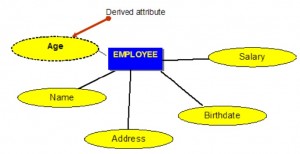
Atrybuty pochodne
Atrybuty pochodne to atrybuty, które zawierają wartości obliczone na podstawie innych atrybutów. Przykład takiego działania można zobaczyć na rysunku 8.5. Wiek może zostać wyprowadzony z atrybutu Data urodzenia. W tej sytuacji Birthdate jest nazywany atrybutem przechowywanym, który jest fizycznie zapisany w bazie danych.
Keys
Ważnym ograniczeniem na encji jest klucz. Klucz jest atrybutem lub grupą atrybutów, których wartości mogą być użyte do jednoznacznej identyfikacji pojedynczej encji w zbiorze encji.
Typy kluczy
Istnieje kilka typów kluczy. Są one opisane poniżej.
Klucz kandydujący
Klucz kandydujący jest kluczem prostym lub złożonym, który jest unikalny i minimalny. Jest unikalny, ponieważ żadne dwa wiersze w tabeli nie mogą mieć tej samej wartości w dowolnym momencie. Jest minimalny, ponieważ każda kolumna jest niezbędna do osiągnięcia unikalności.
Z naszego przykładu bazy danych COMPANY, jeśli encja to Employee(EID, First Name, Last Name, SIN, Address, Phone, BirthDate, Salary, DepartmentID), możliwe klucze kandydujące to:
- EID, SIN
- Imię i Nazwisko – zakładając, że w firmie nie ma nikogo innego o tym samym nazwisku
- Imię i Nazwisko oraz DepartmentID – zakładając, że dwie osoby o tym samym nazwisku nie pracują w tym samym dziale
Klucz złożony
Klucz złożony składa się z dwóch lub więcej atrybutów, ale musi być minimalny.
Używając przykładu z sekcji kluczy kandydujących, możliwe klucze złożone to:
- Imię i Nazwisko – przy założeniu, że w firmie nie ma nikogo innego o tym samym nazwisku
- Imię i Nazwisko oraz identyfikator działu – przy założeniu, że dwie osoby o tym samym nazwisku nie pracują w tym samym dziale
Klucz główny
Klucz główny to klucz kandydujący, który jest wybierany przez projektanta bazy danych do wykorzystania jako mechanizm identyfikacyjny dla całego zbioru encji. Musi on jednoznacznie identyfikować krotki w tabeli i nie może mieć wartości null. Klucz główny jest wskazywany w modelu ER przez podkreślenie atrybutu.
- Klucz kandydujący jest wybierany przez projektanta w celu unikalnej identyfikacji krotek w tabeli. Nie może być null.
- Klucz jest wybierany przez projektanta bazy danych, aby był używany jako mechanizm identyfikujący cały zbiór encji. Określa się go mianem klucza głównego. Klucz ten jest wskazywany przez podkreślenie atrybutu w modelu ER.
W poniższym przykładzie kluczem podstawowym jest EID:
Employee(EID, First Name, Last Name, SIN, Address, Phone, BirthDate, Salary, DepartmentID)
Klucz drugorzędny
Klucz drugorzędny to atrybut używany ściśle w celach wyszukiwawczych (może być złożony), na przykład: Telefon i Nazwisko.
Klucz alternatywny
Kluczami alternatywnymi są wszystkie klucze kandydujące, które nie zostały wybrane jako klucz główny.
Klucz obcy
Klucz obcy (FK) jest atrybutem w tabeli, który odwołuje się do klucza głównego w innej tabeli LUB może być zerowy. Oba klucze obce i podstawowe muszą być tego samego typu danych.
W poniższym przykładzie bazy danych COMPANY, DepartmentID jest kluczem obcym:
Employee(EID, First Name, Last Name, SIN, Address, Phone, BirthDate, Salary, DepartmentID)
Nulls
Null jest specjalnym symbolem, niezależnym od typu danych, który oznacza albo nieznany albo nie ma zastosowania. Nie oznacza zera ani pustki. Cechy null obejmują:
- Brak możliwości wprowadzania danych
- Niedozwolone w kluczu głównym
- Należy unikać w innych atrybutach
- Może reprezentować
- Nieznaną wartość atrybutu
- Znaną, ale brakującą, wartość atrybutu
- Warunek „nie dotyczy”
- Może powodować problemy, gdy używane są funkcje takie jak COUNT, AVERAGE i SUM
- Może powodować problemy logiczne, gdy łączone są tabele relacyjne
UWAGA: Wynik operacji porównania jest zerowy, gdy którykolwiek z argumentów jest zerowy. Wynik operacji arytmetycznej jest zerowy, gdy którykolwiek z argumentów jest zerowy (z wyjątkiem funkcji ignorujących zera).
Przykład użycia null
Użyj tabeli Salary (Salary_tbl) na rysunku 8.6, aby prześledzić przykład użycia null.
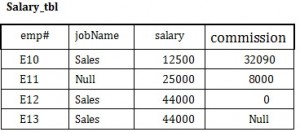
Na początek znajdź wszystkich pracowników (emp#) w dziale Sales (pod kolumną jobName), których wynagrodzenie plus prowizja są większe niż 30 000.
- SELECT emp# FROM Salary_tbl
- WHERE jobName = Sales AND
- (prowizja + pensja) > 30,000 -> E10 i E12
Ten wynik nie zawiera E13 ze względu na wartość null w kolumnie prowizja. Aby mieć pewność, że wiersz z wartością null zostanie uwzględniony, musimy przyjrzeć się poszczególnym polom. Dodając prowizję i wynagrodzenie dla pracownika E13, wynikiem będzie wartość null. Rozwiązanie przedstawiono poniżej.
Relacje
Relacje są klejem, który trzyma tabele razem. Są one używane do łączenia powiązanych informacji między tabelami.
Siła powiązań jest oparta na tym, jak zdefiniowany jest klucz główny powiązanej jednostki. Słaba lub nieidentyfikująca relacja istnieje, jeśli klucz podstawowy powiązanej jednostki nie zawiera składnika klucza podstawowego jednostki nadrzędnej. Przykłady firmowej bazy danych obejmują:
- Customer(CustID, CustName)
- Order(OrderID, CustID, Date)
Silna, lub identyfikująca, relacja istnieje, gdy klucz główny powiązanej jednostki zawiera składnik klucza głównego jednostki nadrzędnej. Przykłady obejmują:
- Kurs(CrsCode, DeptCode, Description)
- Klasa(CrsCode, Section, ClassTime…)
Typy relacji
Poniżej znajdują się opisy różnych typów relacji.
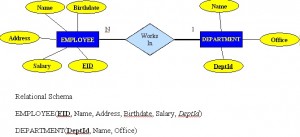
Relacja jeden do wielu (1:M)
Relacja jeden do wielu (1:M) powinna być normą w każdym projekcie relacyjnej bazy danych i występuje we wszystkich środowiskach relacyjnych baz danych. Na przykład jeden dział ma wielu pracowników. Rysunek 8.7 przedstawia relację jednego z tych pracowników do działu.
Związek jeden do jednego (1:1)
Związek jeden do jednego (1:1) to związek jednej jednostki z tylko jedną inną jednostką i odwrotnie. Powinna być rzadka w każdym projekcie relacyjnej bazy danych. W rzeczywistości może wskazywać, że dwie encje należą do tej samej tabeli.
Przykładem z bazy danych FIRMA jest jeden pracownik powiązany z jednym współmałżonkiem i jeden współmałżonek powiązany z jednym pracownikiem.
Związki wiele do wielu (M:N)
W przypadku związku wiele do wielu należy rozważyć następujące kwestie:
- Nie można go zaimplementować jako takiego w modelu relacyjnym.
- Można go zamienić na dwa związki 1:M.
- Może być zaimplementowany przez rozbicie w celu wytworzenia zestawu relacji 1:M.
- Wiąże się z implementacją encji złożonej.
- Tworzy dwie lub więcej relacji 1:M.
- Tabela encji złożonej musi zawierać co najmniej klucze podstawowe tabel oryginalnych.
- Tabela łącząca zawiera wiele wystąpień wartości kluczy obcych.
- Dodatkowe atrybuty mogą być przypisane w razie potrzeby.
- Można uniknąć problemów nieodłącznie związanych z relacją M:N poprzez utworzenie encji złożonej lub encji pomostowej. Na przykład, pracownik może pracować nad wieloma projektami LUB projekt może mieć wielu pracowników pracujących nad nim, w zależności od zasad biznesowych. Albo uczeń może mieć wiele klas, a klasa może mieć wielu uczniów.
Rysunek 8.8 pokazuje inny aspekt relacji M:N, gdzie pracownik ma różne daty rozpoczęcia dla różnych projektów. Dlatego potrzebujemy tabeli JOIN, która zawiera EID, Code i StartDate.
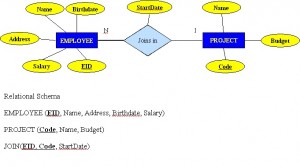
Przykład mapowania typu relacji binarnej M:N
- Dla każdej relacji binarnej M:N zidentyfikuj dwie relacje.
- A i B reprezentują dwa typy encji uczestniczące w R.
- Utwórz nową relację S, aby reprezentować R.
- S musi zawierać PK A i B. Te razem mogą być PK w tabeli S LUB te razem z innym prostym atrybutem w nowej tabeli R mogą być PK.
- Kombinacja kluczy podstawowych (A i B) będzie stanowić klucz podstawowy tabeli S.
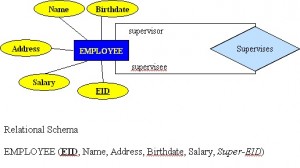
Związek jednoargumentowy (rekurencyjny)
Związek jednoargumentowy, zwany również rekurencyjnym, to taki, w którym związek istnieje między wystąpieniami tego samego zbioru encji. W tej relacji klucz główny i obcy są takie same, ale reprezentują dwie encje o różnych rolach. Zobacz przykład na rysunku 8.9.
Dla niektórych encji w relacji unarnej można utworzyć osobną kolumnę, która odnosi się do klucza głównego tego samego zbioru encji.
Związki trójstronne
Związek trójstronny to typ związku, który obejmuje relacje wiele do wielu między trzema tabelami.
Odnieś się do rysunku 8.10, aby zobaczyć przykład mapowania trójdzielnego typu relacji. Uwaga n-ary oznacza wiele tabel w relacji. (Pamiętaj, że N = wiele.)
- Dla każdej n-arygodnej (> 2) relacji utwórz nową relację, aby ją reprezentować.
- Klucz główny nowej relacji jest kombinacją kluczy głównych uczestniczących podmiotów, które posiadają stronę N (wiele).
- W większości przypadków relacji n-arycznej wszystkie uczestniczące encje posiadają stronę many.
jednostki charakterystyczne: encje, które dostarczają więcej informacji o innej tabeli
atrybuty złożone: atrybuty, które składają się z hierarchii atrybutów
klucz złożony: złożony z dwóch lub więcej atrybutów, ale musi być minimalny
atrybuty zależne: encje te zależą od innych tabel w zakresie swojego znaczenia
atrybuty pochodne: atrybuty, które zawierają wartości obliczone na podstawie innych atrybutów
atrybuty pochodne: patrz encje zależne
EID: identyfikacja pracownika (ID)
entyt: rzecz lub obiekt w świecie rzeczywistym o niezależnym istnieniu, który można odróżnić od innych obiektów
relacja między podmiotami (ER) Model danych: zwany również schematem ER, są reprezentowane przez diagramy ER. Są one dobrze przystosowane do modelowania danych do użytku z bazami danych.
schemat relacji między podmiotami: zob. model danych relacji między podmiotami
zbiór podmiotów: zbiór podmiotów danego typu w danym momencie
typ podmiotu: zbiór podobnych podmiotów
klucz obcy (FK): atrybut w tabeli, który odwołuje się do klucza głównego w innej tabeli LUB może być zerowy
niezależny podmiot: jako elementy składowe bazy danych, encje te są tym, na czym opierają się inne tabele
kernel: patrz encja niezależna
klucz: atrybut lub grupa atrybutów, których wartości mogą być użyte do jednoznacznej identyfikacji pojedynczej encji w zbiorze encji
atrybuty wielowartościowe: atrybuty, które mają zestaw wartości dla każdej encji
n-ary: wiele tabel w relacji
null: specjalny symbol, niezależny od typu danych, który oznacza nieznany lub niemożliwy do zastosowania; nie oznacza zera lub pustego miejsca
relacja rekursywna: patrz relacja jednoargumentowa
relacje: związki lub interakcje między podmiotami; używane do łączenia powiązanych informacji między tabelami
siła relacji: oparta na tym, jak zdefiniowany jest klucz główny powiązanej encji
klucz drugorzędny atrybut używany wyłącznie do celów wyszukiwania
atrybuty proste: zaczerpnięte z domen wartości atomowych
SIN: numer ubezpieczenia społecznego
atrybuty jednowartościowe: patrz atrybuty proste
atrybut przechowywany: zapisany fizycznie w bazie danych
relacja alternatywna: typ relacji, który obejmuje wiele do wielu związków między trzema tabelami.
związek jednolity: taki, w którym związek istnieje między wystąpieniami tego samego zbioru encji.
- Na jakich dwóch koncepcjach opiera się modelowanie ER?
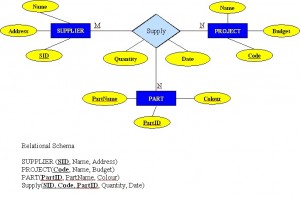
- Baza danych na rysunku 8.11 składa się z dwóch tabel. Wykorzystaj ten rysunek, aby odpowiedzieć na pytania od 2.1 do 2.5.
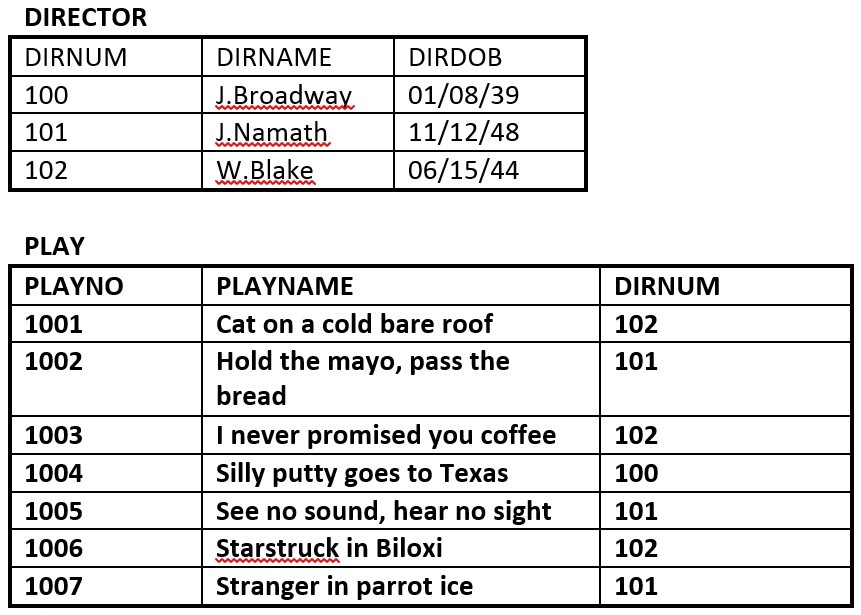
Rysunek 8.11. Tabele Director i Play dla pytania 2, autor: A. Watt. - Zidentyfikuj klucz główny dla każdej tabeli.
- Zidentyfikuj klucz obcy w tabeli PLAY.
- Zidentyfikuj klucze kandydujące w obu tabelach.
- Narysuj model ER.
- Czy tabela PLAY wykazuje integralność referencyjną? Dlaczego tak lub dlaczego nie?
- Zdefiniuj następujące pojęcia (w przypadku niektórych z nich może być konieczne skorzystanie z Internetu):
schemat
język hosta
podjęzyk danych
język definicji danych
relacja jednoargumentowa
klucz obcy
relacja wirtualna
łączność
klucz złożony
tabela łącząca - Baza danych RRE Trucking Company zawiera trzy tabele przedstawione na rysunku 8.12. Skorzystaj z rysunku 8.12, aby odpowiedzieć na pytania od 4.1 do 4.5.
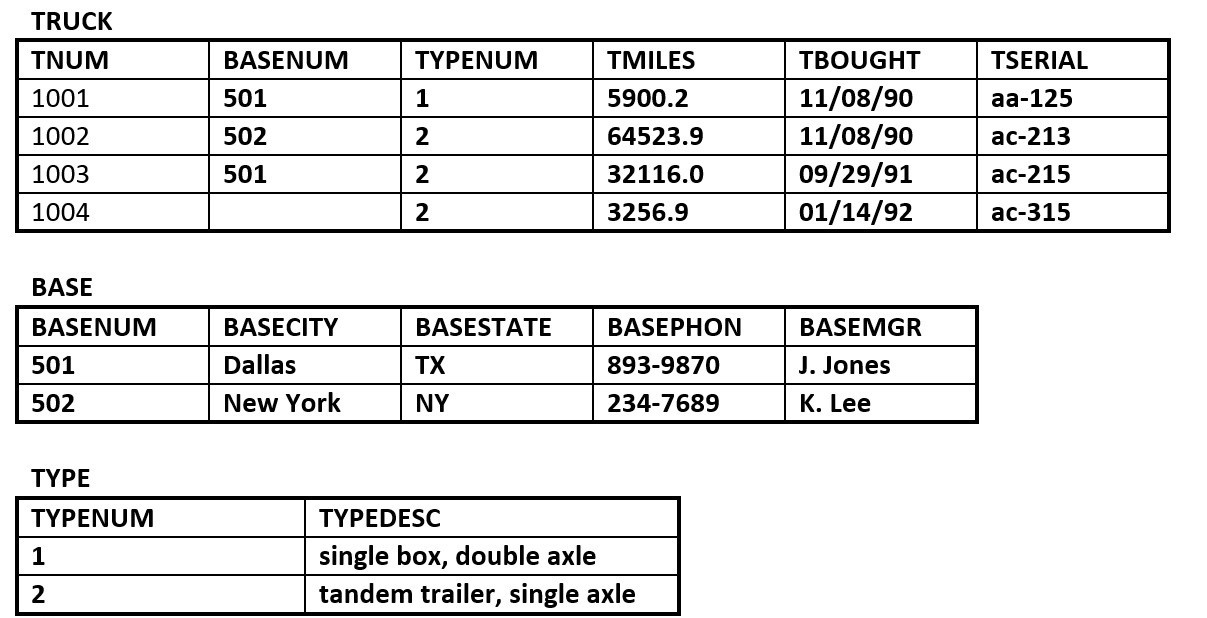
Rysunek 8.12. Tabele Truck, Base i Type dla pytania 4, autorstwa A. Watt. - Zidentyfikuj klucz główny i obcy(e) dla każdej tabeli.
- Czy tabela TRUCK wykazuje integralność encji i referencji? Dlaczego tak lub dlaczego nie? Wyjaśnij swoją odpowiedź.
- Jakiego rodzaju relacja istnieje między tabelami TRUCK i BASE?
- Ile encji zawiera tabela TRUCK?
- Zidentyfikuj klucz(y) kandydujący(e) do tabeli TRUCK.
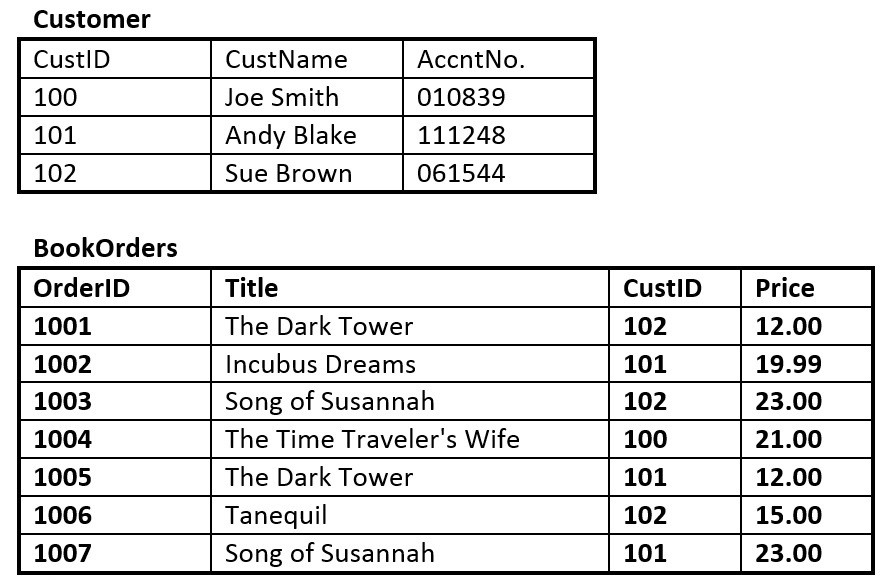
Rysunek 8.13. Tabele Customer i BookOrders dla pytania 5, autorstwa A. Watt.
- Załóżmy, że korzystasz z bazy danych przedstawionej na rysunku 8.13, składającej się z tych dwóch tabel. Użyj rysunku 8.13, aby odpowiedzieć na pytania od 5.1 do 5.6.
- Zidentyfikuj klucz główny w każdej tabeli.
- Zidentyfikuj klucz obcy w tabeli BookOrders.
- Czy w którejś z tabel istnieją klucze kandydujące?
- Narysuj model ER.
- Czy tabela BookOrders wykazuje integralność referencyjną? Dlaczego lub dlaczego nie?
- Czy tabele zawierają nadmiarowe dane? Jeśli tak, to które tabele i jakie są to nadmiarowe dane?
- Patrząc na tabelę Student na rysunku 8.14, wymień wszystkie możliwe klucze kandydujące. Dlaczego je wybrałeś?
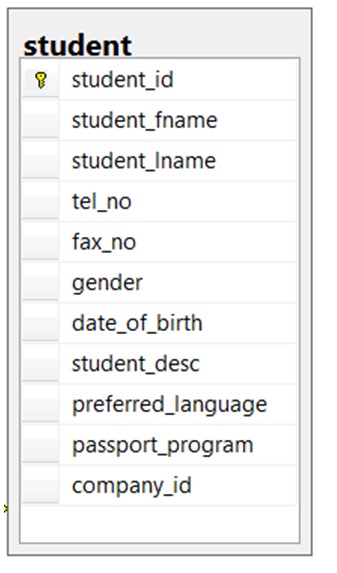
Rysunek 8.14. Tabela uczniów dla pytania 6, autorstwa A. Watt. 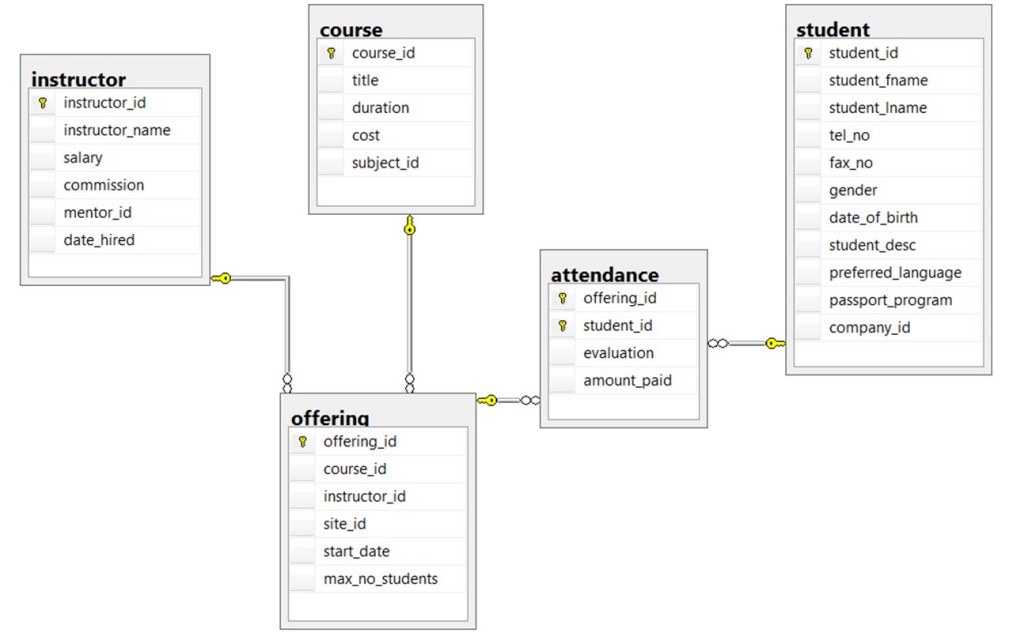
Rysunek 8.15. ERD szkolnej bazy danych dla pytań 7-10, autorstwa A. Watta. Użyj ERD szkolnej bazy danych z rysunku 8.15, aby odpowiedzieć na pytania od 7 do 10.
- Zidentyfikuj wszystkie jądra oraz encje zależne i charakterystyczne w ERD.
- Które z tabel przyczyniają się do powstawania słabych relacji? Silne związki?
- Patrząc na każdą z tabel w szkolnej bazie danych na rysunku 8.15, który atrybut może mieć wartość NULL? Dlaczego?
- Które z tabel powstały w wyniku działania relacji wiele do wielu?
Zobacz także Dodatek B: Przykładowe ćwiczenia ERD
Attribution
Ten rozdział Database Design (w tym obrazy, z wyjątkiem przypadków, gdy zaznaczono inaczej) jest pochodną kopią Data Modeling Using Entity-Relationship Model autorstwa Nguyen Kim Anh na licencji Creative Commons Attribution License 3.0 license
The following material was written by Adrienne Watt:
- Nulls section and example
- Key Terms
- Exercises
.