W tym blogu omówimy podstawowe pojęcia regresji logistycznej i jakie problemy może nam ona pomóc rozwiązać.

Regresja logistyczna jest algorytmem klasyfikacyjnym używanym do przypisywania obserwacji do dyskretnego zbioru klas. Niektóre z przykładów problemów klasyfikacyjnych to e-mail spam lub nie spam, transakcje online oszustwo lub nie oszustwo, guz złośliwy lub łagodny. Regresja logistyczna przekształca swoje dane wyjściowe za pomocą logistycznej funkcji sigmoidalnej, aby zwrócić wartość prawdopodobieństwa.
Jakie są typy regresji logistycznej
- Binarna (np. Nowotwór złośliwy lub łagodny)
- Funkcje wielolinioweKlasa (np. Koty, psy lub owce)
Regresja logistyczna
Regresja logistyczna jest algorytmem uczenia maszynowego, który jest używany do problemów klasyfikacji, jest to algorytm analizy predykcyjnej i opiera się na koncepcji prawdopodobieństwa.

Regresję logistyczną możemy nazwać modelem regresji liniowej, ale regresja logistyczna wykorzystuje bardziej złożoną funkcję kosztu, ta funkcja kosztu może być określona jako „funkcja sigmoidalna” lub znana również jako „funkcja logistyczna” zamiast funkcji liniowej.
Hipoteza regresji logistycznej skłania ją do ograniczenia funkcji kosztu między 0 a 1. Therefore linear functions fail to represent it as it can have a value greater than 1 or less than 0 which is not possible as per the hypothesis of logistic regression.
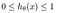
Co to jest funkcja sigmoidalna?
Aby odwzorować przewidywane wartości na prawdopodobieństwa, używamy funkcji sigmoidalnej. Funkcja ta mapuje dowolną wartość rzeczywistą na inną wartość z przedziału od 0 do 1. W uczeniu maszynowym używamy sigmoidy do mapowania przewidywań na prawdopodobieństwa.


Odwzorowanie hipotezy
Przy regresji liniowej stosowaliśmy wzór hipotezy tj.
hΘ(x) = β₀ + β₁X
Dla regresji logistycznej będziemy go nieco modyfikować tj.e.
σ(Z) = σ(β₀ + β₁X)
Oczekiwaliśmy, że nasza hipoteza da wartości pomiędzy 0 a 1.
Z = β₀ + β₁X
hΘ(x) = sigmoida(Z)
tj. hΘ(x) = 1/(1 + e^-(β₀ + β₁X)

Granica decyzji
.
Oczekujemy, że nasz klasyfikator da nam zestaw wyjść lub klas opartych na prawdopodobieństwie, gdy przepuścimy dane wejściowe przez funkcję predykcji i zwróci wynik prawdopodobieństwa pomiędzy 0 a 1.
Na przykład, mamy 2 klasy, weźmy je jak koty i psy (1 – pies , 0 – koty). W zasadzie decydujemy z wartością progową, powyżej której klasyfikujemy wartości do klasy 1 i jeśli wartość spada poniżej progu, wtedy klasyfikujemy ją do klasy 2.
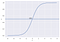
Jak widać na powyższym wykresie wybraliśmy próg 0.5, jeśli funkcja predykcji zwróciła wartość 0.7 wtedy zaklasyfikowalibyśmy tę obserwację do klasy 1(DOG). Jeśli nasza prognoza zwróciła wartość 0.2 wtedy sklasyfikowalibyśmy obserwację jako klasę 2 (CAT).
Funkcja kosztu
Poznaliśmy funkcję kosztu J(θ) w regresji liniowej, funkcja kosztu reprezentuje cel optymalizacji tzn. tworzymy funkcję kosztu i minimalizujemy ją tak, że możemy opracować dokładny model z minimalnym błędem.
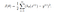
Jeśli spróbujemy użyć funkcji kosztu regresji liniowej w „regresji logistycznej”, wówczas nie byłaby ona użyteczna, ponieważ skończyłaby jako funkcja niewypukła z wieloma lokalnymi minimami, w którym byłoby bardzo trudno zminimalizować wartość kosztu i znaleźć globalne minimum.

Dla regresji logistycznej funkcja kosztu jest zdefiniowana jako:
-log(hθ(x)) jeśli y = 1
-log(1-hθ(x)) jeśli y = 0

.