Il locking è essenziale per il successo delle transazioni di SQL Server ed è progettato per permettere a SQL Server di lavorare senza problemi in un ambiente multi-utente. Il lock è il modo in cui SQL Server gestisce la concorrenza delle transazioni. Essenzialmente, i lock sono strutture in-memoria che hanno proprietari, tipi e l’hash della risorsa che dovrebbero proteggere. Un lock come struttura in-memoria ha una dimensione di 96 byte.
Per capire meglio il locking in SQL Server, è importante capire che il locking è progettato per garantire l’integrità dei dati nel database, in quanto costringe ogni transazione di SQL Server a passare il test ACID.
Il test ACID consiste in 4 requisiti che ogni transazione deve superare con successo:
- Atomicità – richiede che una transazione che coinvolge due o più parti discrete di informazioni deve impegnare tutte le parti o nessuna
- Consistenza – richiede che una transazione deve creare uno stato valido di nuovi dati, o deve riportare tutti i dati allo stato che esisteva prima che la transazione fosse eseguita
- Isolamento – richiede che una transazione che è ancora in esecuzione e non ha ancora impegnato tutti i dati, deve rimanere isolata da tutte le altre transazioni
- Durabilità – richiede che i dati impegnati devono essere memorizzati utilizzando un metodo che conservi tutti i dati nello stato corretto e disponibile per un utente, anche in caso di fallimento
Il locking di SQL Server è la parte essenziale del requisito di isolamento e serve a bloccare gli oggetti interessati da una transazione. Mentre gli oggetti sono bloccati, SQL Server impedirà alle altre transazioni di effettuare qualsiasi modifica dei dati memorizzati negli oggetti interessati dal blocco imposto. Una volta che il blocco viene rilasciato commettendo le modifiche o riportando le modifiche allo stato iniziale, le altre transazioni saranno autorizzate ad apportare le modifiche ai dati richieste.
Tradotto nel linguaggio di SQL Server, questo significa che quando una transazione impone il lock su un oggetto, tutte le altre transazioni che richiedono l’accesso a quell’oggetto saranno costrette ad aspettare fino al rilascio del lock e tale attesa sarà registrata con il tipo di attesa adeguato
I lock di SQL Server possono essere specificati attraverso i modi di lock e la granularità del lock
Modi di lock
Il modo di lock considera vari tipi di lock che possono essere applicati a una risorsa che deve essere bloccata:
- Esclusivo (X)
- Condiviso (S)
- Aggiornamento (U)
- Intento (I)
- Schema (Sch)
- Aggiornamento in blocco (BU)
Lock esclusivo (X) – Questo tipo di blocco, quando imposto, assicura che una pagina o una riga sarà riservata esclusivamente alla transazione che ha imposto il blocco esclusivo, fino a quando la transazione detiene il blocco.
Il blocco esclusivo viene imposto dalla transazione quando vuole modificare i dati della pagina o della riga, il che avviene nel caso delle istruzioni DML DELETE, INSERT e UPDATE. Un blocco esclusivo può essere imposto a una pagina o a una riga solo se non c’è un altro blocco condiviso o esclusivo già imposto sulla destinazione. Questo significa praticamente che solo un blocco esclusivo può essere imposto su una pagina o una riga, e una volta imposto nessun altro blocco può essere imposto sulle risorse bloccate
Lock condiviso (S) – questo tipo di blocco, quando imposto, riserva una pagina o una riga per essere disponibile solo per la lettura, il che significa che a qualsiasi altra transazione sarà impedito di modificare il record bloccato finché il blocco è attivo. Tuttavia, un blocco condiviso può essere imposto da diverse transazioni allo stesso tempo sulla stessa pagina o riga e in questo modo diverse transazioni possono condividere la capacità di lettura dei dati, poiché il processo di lettura stesso non influenzerà in alcun modo i dati attuali della pagina o della riga. Inoltre, un blocco condiviso permetterà operazioni di scrittura, ma non saranno permesse modifiche DDL
Lock di aggiornamento (U) – questo blocco è simile a un blocco esclusivo ma è progettato per essere più flessibile in un certo senso. Un lock di aggiornamento può essere imposto su un record che ha già un lock condiviso. In tal caso, il lock di aggiornamento imporrà un altro lock condiviso sulla riga di destinazione. Una volta che la transazione che detiene il lock di aggiornamento è pronta a cambiare i dati, il lock di aggiornamento (U) sarà trasformato in un lock esclusivo (X). È importante capire che l’update lock è asimmetrico rispetto ai lock condivisi. Mentre il lock di aggiornamento può essere imposto su un record che ha il lock condiviso, il lock condiviso non può essere imposto sul record che ha già il lock di aggiornamento
Intent lock (I) – questo lock è un mezzo usato da una transazione per informare un’altra transazione della sua intenzione di acquisire un lock. Lo scopo di tale blocco è di assicurare che la modifica dei dati sia eseguita correttamente impedendo ad un’altra transazione di acquisire un blocco sull’oggetto successivo nella gerarchia. In pratica, quando una transazione vuole acquisire un lock sulla riga, acquisirà un intent lock su una tabella, che è un oggetto di gerarchia superiore. Acquisendo l’intent lock, la transazione non permetterà ad altre transazioni di acquisire il lock esclusivo su quella tabella (altrimenti, il lock esclusivo imposto da qualche altra transazione annullerebbe il lock della riga).
Questo è un tipo di blocco importante dal punto di vista delle prestazioni in quanto il motore del database di SQL Server ispezionerà i blocchi di intenti solo a livello di tabella per controllare se è possibile per la transazione acquisire un blocco in modo sicuro in quella tabella, e quindi il blocco di intenti elimina la necessità di ispezionare ogni blocco di riga/pagina in una tabella per assicurarsi che la transazione possa acquisire il blocco sull’intera tabella
Ci sono tre blocchi di intenti regolari e tre cosiddetti blocchi di conversione:
Serrature regolari:
Intent exclusive (IX) – quando viene acquisito un intent exclusive lock (IX) indica a SQL Server che la transazione ha l’intenzione di modificare alcune risorse della gerarchia inferiore acquisendo lock esclusivi (X) individualmente su quelle risorse della gerarchia inferiore
Intent shared (IS) – quando viene acquisito un intent shared lock (IS) indica a SQL Server che la transazione ha l’intenzione di leggere alcune risorse della gerarchia inferiore acquisendo blocchi condivisi (S) individualmente su quelle risorse più in basso nella gerarchia
Intent update (IU) – quando viene acquisito un intent shared lock (IS) indica a SQL Server che la transazione ha l’intenzione di leggere alcune risorse della gerarchia inferiore acquisendo blocchi condivisi (S) individualmente su quelle risorse più in basso nella gerarchia. L’intent update lock (IU) può essere acquisito solo a livello di pagina e non appena avviene l’operazione di aggiornamento, si converte in intent exclusive lock (IX)
Conversion locks:
Shared with intent exclusive (SIX) – quando viene acquisito, questo lock indica che la transazione intende leggere tutte le risorse a una gerarchia inferiore e quindi acquisire il lock condiviso su tutte le risorse che sono più in basso nella gerarchia, e a sua volta, modificare parte di quelle, ma non tutte. Nel fare ciò, acquisirà un lock intenzionalmente esclusivo (IX) su quelle risorse di gerarchia inferiore che dovrebbero essere modificate. In pratica, questo significa che una volta che la transazione acquisisce un lock SIX sulla tabella, acquisirà un intent exclusive lock (IX) sulle pagine modificate e un exclusive lock (X) sulle righe modificate.
Solo uno shared with intent exclusive lock (SIX) può essere acquisito su una tabella alla volta e bloccherà le altre transazioni dall’effettuare aggiornamenti, ma non impedirà alle altre transazioni di leggere le risorse della gerarchia inferiore che possono acquisire l’intent shared (IS) lock sulla tabella
Shared with intent update (SIU) – questo è un lock un po’ più specifico poiché è una combinazione dei lock shared (S) e intent update (IU). Un tipico esempio di questo blocco è quando una transazione sta usando una query eseguita con il suggerimento PAGELOCK e la query, poi la query di aggiornamento. Dopo che la transazione acquisisce un lock SIU sulla tabella, la query con l’hint PAGELOCK acquisirà il lock condiviso (S) mentre la query di aggiornamento acquisirà il lock intent update (IU)
Update with intent exclusive (UIX) – quando i lock update lock (U) e intent exclusive (IX) sono acquisiti contemporaneamente a risorse di gerarchia inferiore nella tabella, il blocco di aggiornamento con intento esclusivo sarà acquisito a livello di tabella come conseguenza
Schema lock (Sch) – Il motore di database di SQL Server riconosce due tipi di schema lock: Schema modification lock (Sch-M) e Schema stability lock (Sch-S)
- Uno Schema modification lock (Sch-M) viene acquisito quando viene eseguita una istruzione DDL, e impedisce l’accesso ai dati dell’oggetto bloccato mentre la struttura dell’oggetto viene modificata. SQL Server permette un solo blocco di modifica dello schema (Sch-M) su qualsiasi oggetto bloccato. Per modificare una tabella, una transazione deve aspettare di acquisire un blocco Sch-M sull’oggetto di destinazione. Una volta acquisito il blocco di modifica dello schema (Sch-M), la transazione può modificare l’oggetto e al termine della modifica il blocco sarà rilasciato. Un tipico esempio di blocco Sch-M è la ricostruzione di un indice, poiché la ricostruzione di un indice è un processo di modifica della tabella. Una volta che l’ID di ricostruzione dell’indice è emesso, un blocco di modifica dello schema (Sch-M) sarà acquisito su quella tabella e sarà rilasciato solo dopo che il processo di ricostruzione dell’indice sarà completato (quando usato con l’opzione ONLINE, la ricostruzione dell’indice acquisirà il blocco Sch-M poco alla fine del processo)
- Un blocco di stabilità dello schema (Sch-S) sarà acquisito mentre una query dipendente dallo schema viene compilata ed eseguita e il piano di esecuzione viene generato. Questo particolare blocco non bloccherà altre transazioni per accedere ai dati dell’oggetto ed è compatibile con tutti i modi di blocco tranne che con il blocco di modifica dello schema (Sch-M). Essenzialmente, i blocchi di stabilità dello schema saranno acquisiti da ogni query DML e select per garantire l’integrità della struttura della tabella (assicurarsi che la tabella non cambi mentre le query sono in esecuzione).
Bulk Update locks (BU) – questo blocco è progettato per essere usato da operazioni di importazione di massa quando viene emesso con un argomento/intento TABLOCK. Quando viene acquisito un blocco di aggiornamento in blocco, altri processi non saranno in grado di accedere ad una tabella durante l’esecuzione del caricamento in blocco. Tuttavia, un blocco di aggiornamento globale non impedisce che un altro carico globale venga elaborato in parallelo. Ma tenete a mente che l’uso del TABLOCK su una tabella con indice clustered non permetterà l’importazione in parallelo del bulk. Maggiori dettagli su questo sono disponibili in Linee guida per l’ottimizzazione dell’importazione massiva
Gerarchia di blocco
SQL Server ha introdotto la gerarchia di blocco che viene applicata quando viene eseguita la lettura o la modifica dei dati. La gerarchia di blocco inizia con il database al livello più alto della gerarchia e scende attraverso la tabella e la pagina fino alla riga al livello più basso

Essenzialmente, c’è sempre un blocco condiviso a livello di database che viene imposto ogni volta che una transazione è collegata a un database. Il blocco condiviso a livello di database è imposto per impedire l’abbandono del database o il ripristino di un backup del database sul database in uso. Per esempio, quando un’istruzione SELECT è emessa per leggere dei dati, un blocco condiviso (S) sarà imposto a livello di database, un blocco condiviso intenzionale (IS) sarà imposto sulla tabella e sul livello di pagina, e un blocco condiviso (S) sulla riga stessa

Nel caso di un’istruzione DML (cioè insert, update, delete) viene imposto un lock condiviso (S) a livello di database, un intent exclusive lock (IX) o intent update lock (IU) a livello di tabella e di pagina, e un exclusive o update lock (X o U) sulla riga

I lock vengono sempre acquisiti dall’alto verso il basso perché in questo modo SQL Server impedisce il verificarsi di una cosiddetta Race condition.
Ora che i modi di blocco e la gerarchia di blocco sono stati spiegati, elaboriamo ulteriormente i modi di blocco e come questi si traducono in una gerarchia di blocco.
Non tutti i modi di blocco possono essere applicati a tutti i livelli.
A livello di riga, possono essere applicati i seguenti tre modi di blocco:
- Esclusivo (X)
- Condiviso (S)
- Aggiornamento (U)
Per capire la compatibilità di questi modi, consultare la seguente tabella:
| Esclusivo (X) | Condiviso (S) | Aggiornamento (U) | |
| Esclusivo (X) | ✗ | ✗ | ✗ |
| Condiviso (S) | ✗ | ✓ | ✓ |
| Update (U) | ✗ | ✓ | ✗ |
✓ – compatibile ✗ – incompatibile
A livello di tabella, ci sono cinque diversi tipi di blocchi:
- Esclusivo (X)
- Condiviso (S)
- Intento esclusivo (IX)
- Intento condiviso (IS)
- Condiviso con intento esclusivo (SIX)
La compatibilità di questi modi può essere vista nella tabella seguente
| (X) | (S) | (IX) | (IS) | (SEI) | ||
| (X) | ✗ | ✗ | ✗ | ✗ | ✗ | |
| (S) | ✗ | ✓ | ✗ | ✓ | ✗ | |
| (IX) | ✗ | ✗ | ✓ | ✓ | ✗ | |
| (È) | ✗ | ✓ | ✓ | ✓ | ✓ | |
| (SEI) | ✗ | ✗ | ✗ | ✓ | ✓ | ✗ |
✓ – Compatibile ✗ – Incompatibile
Un blocco dello schema (Sch) è anche un blocco a livello di tabella, ma non è un blocco relativo ai dati
Per capire meglio la compatibilità tra questi tipi di blocco, si prega di fare riferimento a questa tabella:
Lock escalation
Per prevenire una situazione in cui il blocco utilizza troppe risorse, SQL Server ha introdotto la funzione di lock escalation.
Senza escalation, i lock potrebbero richiedere una quantità significativa di risorse di memoria. Prendiamo un esempio in cui un lock dovrebbe essere imposto sulle 30.000 righe di dati, dove ogni riga è di 500 byte di dimensione, per eseguire l’operazione di cancellazione. Senza escalation, verrà imposto un blocco condiviso (S) sul database, 1 blocco esclusivo intenzionale (IX) sulla tabella, 1.875 blocchi esclusivi intenzionali (IX) sulle pagine (una pagina da 8KB contiene 16 righe da 500 byte, il che fa 1.875 pagine che contengono 30.000 righe) e 30.000 blocchi esclusivi (X) sulle righe stesse. Poiché ogni blocco è di 96 byte, 31.877 blocchi richiederanno circa 3 MB di memoria per una singola operazione di cancellazione. L’esecuzione di un gran numero di operazioni in parallelo potrebbe richiedere alcune risorse significative solo per garantire che il locking manager possa eseguire l’operazione senza problemi

Per prevenire una tale situazione, SQL Server utilizza l’escalation dei lock. Questo significa che in una situazione in cui vengono acquisiti più di 5.000 lock su un singolo livello, SQL Server farà l’escalation di questi lock ad un singolo lock a livello di tabella. Per impostazione predefinita, SQL Server farà sempre l’escalation al livello di tabella direttamente, il che significa che l’escalation al livello di pagina non si verifica mai. Invece di acquisire numerose righe e pagine di blocco, SQL Server farà l’escalation al blocco esclusivo (X) a livello di tabella

Mentre questo ridurrà la necessità di risorse, i blocchi esclusivi (X) in una tabella significano che nessun’altra transazione sarà in grado di accedere alla tabella bloccata e tutte le query che cercano di accedere a quella tabella saranno bloccate. Pertanto, questo ridurrà l’overhead del sistema ma aumenterà la probabilità di contesa di concorrenza
Per fornire un controllo sull’escalation, a partire da SQL Server 2008 R2, l’opzione LOCK_EXCALATION è introdotta come parte dell’istruzione ALTER TABLE
Ognuna di queste opzioni è definita per consentire un controllo specifico sul processo di escalation del lock:
Tabella – Questa è l’opzione predefinita per qualsiasi tabella appena creata, poiché per default SQL Server eseguirà sempre l’escalation dei lock a livello di tabella, che include anche le tabelle partizionate
Auto – Questa opzione permette l’escalation dei lock a livello di partizione quando una tabella è partizionata. Quando vengono acquisiti 5.000 lock in una singola partizione, l’escalation dei lock acquisirà un lock esclusivo (X) su quella partizione mentre la tabella acquisirà un lock esclusivo intenzionale (IX). Nel caso in cui la tabella non sia partizionata, la lock escalation acquisirà il lock a livello di tabella (uguale all’opzione Table).
Anche se questa sembra un’opzione molto utile, deve essere usata con molta attenzione perché può facilmente causare un deadlock. In una situazione in cui abbiamo due transazioni su due partizioni in cui viene acquisito il blocco esclusivo (X), e le transazioni cercano di accedere alla data dalla partizione usata dall’altra transazione, si verificherà un deadlock
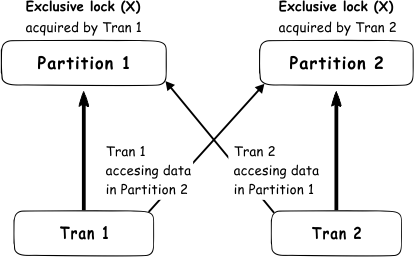
Quindi, è molto importante controllare attentamente il modello di accesso ai dati, se questa opzione è abilitata, che non è facile da ottenere, e questo è il motivo per cui questa opzione non è l’impostazione predefinita in SQL Server
Disable – Questa opzione disabilita completamente l’escalation di blocco per una tabella. Ancora una volta, questa opzione deve essere usata con attenzione per evitare che il lock manager di SQL Server sia costretto a utilizzare una quantità eccessiva di memoria
Come si può vedere, l’escalation dei lock potrebbe essere una sfida per i DBA. Se il progetto dell’applicazione richiede la cancellazione o l’aggiornamento di più di 5.000 righe in una sola volta, una soluzione per evitare l’escalation dei lock, e gli effetti che ne derivano, è dividere la singola transazione in due o più transazioni dove ognuna gestirà meno di 5.000 righe, poiché in questo modo l’escalation dei lock potrebbe essere evitata
ottenere informazioni sui lock attivi di SQL Server
SQL Server fornisce la Dynamics Management View (DMV) sys.dm_tran_locks che restituisce informazioni sulle risorse del lock manager che sono attualmente in uso, il che significa che mostrerà tutti i lock “live” acquisiti dalle transazioni. Maggiori dettagli su questo DMV possono essere trovati nell’articolo sys.dm_tran_locks (Transact-SQL).
Le colonne più importanti usate per l’identificazione del lock sono resource_type, request_mode, e resource_description. Se necessario, altre colonne come risorsa aggiuntiva per informazioni possono essere incluse durante la risoluzione dei problemi
Ecco l’esempio della query
La clausola where in questa query è usata come filtro sul resource_type da eliminare. dai risultati, quelli generalmente condivisi dei lock acquisiti sul database poiché questi sono sempre presenti a livello di database

Una breve spiegazione delle tre colonne qui presentate:
resource_type – Visualizza una risorsa di database dove i lock sono stati acquisiti. La colonna può visualizzare uno dei seguenti valori: ALLOCATION_UNIT, APPLICATION, DATABASE, EXTENT, FILE, HOBT, METADATA, OBJECT, PAGE, KEY, RID
request_mode – visualizza la modalità di blocco che viene acquisita sulla risorsa
resource_description – visualizza una breve descrizione della risorsa e non è popolata per tutte le modalità di blocco. Il più delle volte la colonna contiene l’id della riga, pagina, oggetto, file, ecc
- Autore
- Post recenti
Devoto dell’aviazione militare e appassionato di modellismo aereo in scala. Appassionato di sport estremi; paracadutista e istruttore di bungee jumping. Una volta serio, ora solo un fotografo per il tempo libero
Vedi tutti i post di Nikola Dimitrijevic
- Guida ai flag di tracciamento SQL Server; da -1 a 840 – 4 marzo 2019
- Come gestire il tipo di attesa WRITELOG di SQL Server – 13 giugno 2018
- Contatori di prestazioni di SQL Server (Batch Requests/sec o Transactions/sec): cosa monitorare e perché – 5 giugno 2018