„74 % firem tvrdí, že chtějí být „data-driven“, ale pouze 29 % tvrdí, že umí dobře propojit analytiku s činností.“ – Forrester
Generování, zpracování a sdílení statistik a dat – dělají z vás tyto činnosti „data-driven“ firmu?“
Jistě ano, ale pokud jsou data a statistiky, na jejichž základě se rozhodujete, nepřesné nebo zcela nepravdivé, mohou následné negativní výsledky vyvolat zmatek a špatnou výkonnost.
Důvěryhodná data eliminují děsivou perspektivu spoléhání se na vrtošivé odhady a „instinkt“. Kombinuje lidské zkušenosti a intuici s konkrétními čísly a analytickými údaji, aby se zrodila rozhodnutí schopná pohnout jehlou.
Intuitivní informační panely, tabulky, statistiky a grafy však často maskují falešnou realitu:
Zavádějící statistiky a data.
S rychlým rozvojem technologií a stejným tempem se přizpůsobujícími uživateli se společnosti staly závislými na datech a statistikách, aby se orientovaly v konkurenčním prostředí firem.
Je však snadné nechat se zaslepit absolutností čísel, zvláště když dodávají důvěryhodnost příznivým hypotézám nebo bodům.
Nerozeznání falešných statistik a dat je hrozbou pro rozhodování založené na datech.
Podněcuje vás to k tomu, abyste s plnou důvěrou mačkali pověstná nesprávná tlačítka, a právě v tom spočívá nebezpečí.
V tomto příspěvku se dozvíte, jak rozpoznat zavádějící statistiky a data. Podíváme se na běžné způsoby, kterými klamou, a na to, jak určit, kdy mohou data nést váhu kritických rozhodnutí.
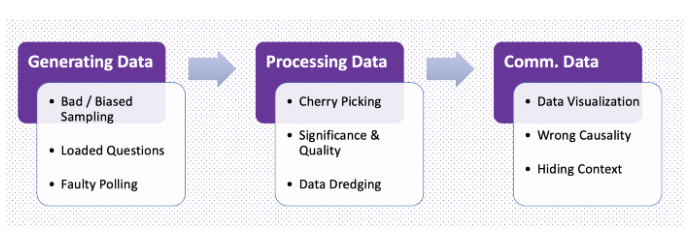
Co je to zavádějící statistika?
Zdroj
Zavádějící statistika vzniká, když je chyba – ať už záměrná, nebo ne – přítomna v jednom ze 3 klíčových aspektů výzkumu:
-
Sběr:
-
Organizování:
-
Prezentace: Vynechání zjištění, která jsou v rozporu s tím, co se výzkumník snaží dokázat: Manipulace s vizuálními/číselnými údaji s cílem ovlivnit vnímání.
Špatné statistiky se vkrádají do zpravodajství, reklamních kampaní a dokonce i do vědecké literatury. Šokujících 33,7 % vědců – superlativů, kteří jsou datově neutrální – přiznalo zneužití statistik k podpoře výzkumu. Ano, dokonce i někteří důvěryhodní strážci informačních bran společnosti jsou vinni.
Abyste mohli činit kritická rozhodnutí na základě správných dat, uvedli jsme seznam běžných způsobů, jak statistika klame a dezinformuje.
Selektivní předpojatost k vytváření falešných statistik
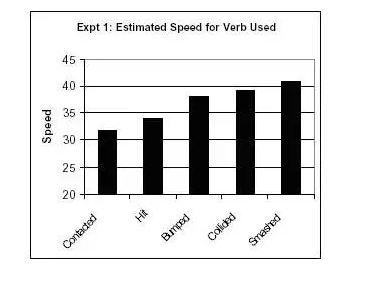
Studie Elizabeth Loftusové testovala vliv jazyka na výpovědi očitých svědků. Pokusným osobám byl promítnut film zachycující několik autonehod. Po zhlédnutí byli dotázáni: „Jakou rychlostí jela auta, když do sebe narazila?“
Dalším subjektům pak byla položena stejná otázka, ovšem se slovem „narazila“ nahrazeným sugestivními slovesy typu:
-
Narazila
-
Narazila
-
Narazila
-
Srazila se
Výsledky?
Čím silnější bylo použité „nabité“ sloveso, tím vyšší byl odhad rychlosti od svědků.
Zdroj
Studie navíc zjistila, že při použití silnějšího slovesa subjekty častěji uváděly rozbité sklo u nehody, i když rozbité sklo nebylo na videu vidět.
Využití jazyka k ovlivnění odpovědí a výsledků průzkumu je jen jedním z příkladů výběrového zkreslení. V roce 2007 donutil Úřad pro reklamní standardy (ASA) společnost Colgate, aby upustila od svého tvrzení, že „více než 80 % zubních lékařů doporučuje používat pastu Colgate“, protože toto tvrzení zavádějícím způsobem naznačovalo, že „80 % zubních lékařů doporučuje zubní pastu Colgate přednostně před všemi ostatními značkami“.
Skutečná otázka v průzkumu zněla: „Kdyby měli na výběr mezi samotným čištěním zubů a používáním zubní pasty – jako je Colgate – kterou by doporučili.“
Výběrem odpovědi z průzkumu vyvolala společnost Colgate dojem, že ji zubaři doporučují před konkurenčními značkami; skutečné doporučení znělo, že používání jakékoli zubní pasty je lepší než samotné čištění zubů.
K selektivnímu zkreslení často dochází, když jsou vybrané vzorky nebo údaje neúplné nebo jsou vybírány cherrypticky, aby ovlivnily vnímání – a dokonce zkreslily – statistiky a údaje.
Zanedbaná velikost vzorku vedoucí k falešné přesnosti

(zdroj)
90 lidí, kteří odpověděli „ano“ ze 100 lidí ( 90 %), oproti 900 lidem, kteří odpověděli „ano“ z 1000 lidí (také 90 %); procenta jsou podobná, ale rozdíl v hodnotě a validitě dat je statisticky významný.
Menší velikost vzorku téměř zaručuje znepokojivě významné výsledky. Vždy si dávejte pozor na extrémní výsledky a nikdy nepřijímejte procenta za bernou minci. Slovy biochemičky Any-Marii Sundic:
„Aby bylo zajištěno, že vzorek je reprezentativní pro populaci, měl by být výběr vzorku náhodný, tj. každý subjekt musí mít stejnou pravděpodobnost, že bude do studie zařazen. Je třeba poznamenat, že ke zkreslení výběru může dojít také v případě, že vzorek je příliš malý na to, aby reprezentoval cílovou populaci.“
Chybné korelace a příčiny k vytvoření falešných statistik
„Korelace neznamená příčinu.“
Nepochybně jste tuto větu již někdy slyšeli, ale má to svůj důvod, je to pravda.
Při korelaci dvou proměnných obvykle platí následující:
-
Y způsobuje X.
-
X způsobuje Y.
-
Třetí faktor vyvolává X + Y.
-
Korelace je způsobena náhodou.
Korelace a kauzalita vzbuzují spoustu podezření, protože výzkumníci – a konzumenti zmíněného výzkumu – propadají:
-číselnému fetišismu
-lovu na korelace
Tyler Vegihn sestavil několik vtipných zavádějících statistických příkladů, které přesně toto dokazují:
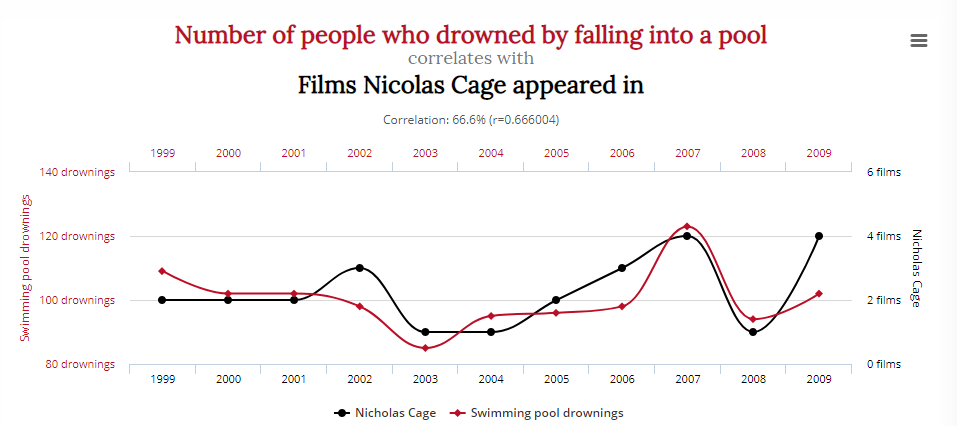
Tento graf zobrazuje přesvědčivou korelaci mezi počtem lidí, kteří se utopili při pádu do bazénu, a počtem filmů, v nichž se objevil Nicolas Cage:
Další ukazuje korelaci mezi počtem lidí, kteří zemřeli zamotáním se do prostěradla, a spotřebou sýra:
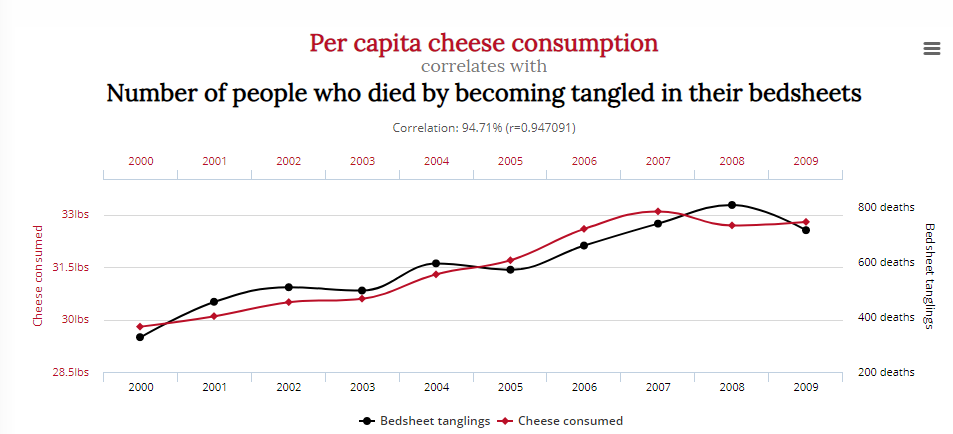
Znamená to, že snížení spotřeby sýra a hereckých rolí Nicolase Cage zachrání životy? Pravděpodobně ne.
Vzhledem k tomu, že vědci jsou tlačeni k tomu, aby objevili užitečné údaje nebo prokázali hypotézu, je pokušení předčasně vyhlásit „aha“ nebo „heuréka“ moment vysoké.
To představuje problém pro zdravé analýzy a statistiky; přihoďte dostatek proměnných a téměř zaručeně najdete korelaci, a to s čímkoli.
Zavádějící grafy a vizualizace
Vizualizace dat mění surová čísla na vizuální znázornění klíčových vztahů, trendů a vzorců. Přestože dokáží data oživit, jsou také oblíbeným prostředkem pro zavádějící statistiky a data.
Datový novinář Alberto Cairo ve své knize „Grafiky, lži, zavádějící vizualizace“ odhaluje zavádějící statistické příklady z marketingových reklam, politických kampaní a zpravodajství.
Jedním z populárních příkladů ze zpravodajství je případ Terri Schiavo, právní případ práva na smrt v USA.
V průběhu případu byl televizí CNN použit graf podobný tomu, který je uveden níže, aby znázornil, jak se různé politické skupiny stavěly k odpojení Terri od přístrojů podporujících život:
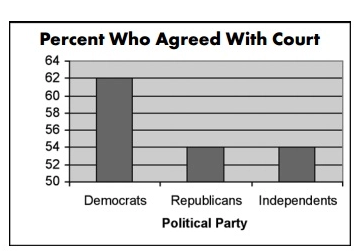
Zdroj
Pohled na tento graf naznačuje, že ve srovnání s republikány a nezávislými souhlasilo se soudem 3krát více demokratů
Při bližším pohledu však zjistíme malý 14% rozdíl v hlasování.
Zkrácený graf a zmanipulovaná osa Y (začíná na 50 místo na 0) zkreslují data a vedou k tomu, že uvěříte přehnané představě o určité skupině.
Při prohlížení grafů a vizualizací se vyhněte klamání tím, že si dáte pozor na:
-
Vynechání základní nebo zkrácené osy v grafu.
-
Intervaly a stupnice. Kontrola nerovnoměrných přírůstků a lichých měření (použití čísel místo procent apod.).
-
Úplný kontext a další srovnávací grafy, abyste zjistili, jak jsou podobná data měřena a znázorněna.
Závěr:
Zavádějící statistiky a data se chlubí grandiózním zlepšením konverzního poměru pomocí „vylepšení CTA“ a „jednoduchých změn barev“.
Vytvářejí šokující titulky, které přitahují houfy návštěvníků, ale poskytují přinejlepším chybné poznatky.
Špatné statistiky a data jsou nebezpečné.
Namísto toho, aby vám pomohly proplout objížďkami, výmoly a nástrahami, vědomě – nebo nevědomě – vás do nich nasměrují. Vy jste však dost chytří na to, abyste je rozpoznali.
Příště, až se setkáte s přesvědčivými daty, projděte si tyto jednoduché, ale účinné otázky:
Kdo provádí výzkum?
Výzkum je drahý a časově náročný. Zjistěte, kdo jej sponzoruje, zvažte jeho zaujatost k tématu a jak by mohl z výsledků těžit. Jedná se o společnost B2C s nějakým produktem? Poradenskou službou? Nezávislá studie financovaná univerzitou?“
Můžeme brát vážně velikost vzorku a délku studie?“
Kontrola podpůrných nebo zastřených čísel odhalí slabou statistickou sílu.
Jsou vizualizace dat zobrazeny spravedlivě?“
Jsou stupnice a intervaly rovnoměrně rozmístěné a neutrální? Prosazuje statistika určitou myšlenku nebo agendu? Není na panelu příliš mnoho metrik?
Je výzkum reprezentován poctivě a nestranně?
Přezkoumejte použitý jazyk, způsob, jakým je formulována otázka, a osoby, které jsou dotazovány.
Abyste předešli znečištění svých informačních panelů, reportů a analýz zavádějícími statistikami a daty, vítejte nové informace se zvídavým a skeptickým postojem.
O autorovi
Hassan Uddeen je britský autor na volné noze, který píše pro společnosti z oblasti B2B, SaaS a Fintech. Miluje vše, co se týká obsahového marketingu. Když se může odtrhnout od klávesnice, rád poskakuje v domácí posilovně (a přitom hraje roleplaying jako Goku) a zahloubá se do dobrého románu Jamese Pattersona.