“74% van de bedrijven zegt “datagestuurd” te willen zijn, maar slechts 29% zegt goed te zijn in het koppelen van analyses aan actie.” – Forrester
Het genereren, verwerken en delen van statistieken en gegevens – maken deze acties u tot een “datagestuurd” bedrijf?
Zeker wel, maar als de gegevens en statistieken die uw beslissingen aansturen onnauwkeurig zijn, of helemaal niet kloppen, kunnen de daaruit voortvloeiende negatieve resultaten verwarring en slechte prestaties in de hand werken.
Credible data elimineert het enge vooruitzicht te moeten vertrouwen op grillige gissingen en “buikgevoelens”. Het combineert menselijke ervaring en intuïtie met concrete cijfers en analyses om beslissingen te nemen die de naald kunnen bewegen.
Maar intuïtieve dashboards, grafieken, statistieken en grafieken maskeren vaak een valse realiteit:
misleidende statistieken en gegevens.
Met technologie die snel vooruitgaat en gebruikers die zich in een gelijk tempo aanpassen, zijn bedrijven afhankelijk geworden van gegevens en statistieken om door een concurrerende bedrijfsomgeving te navigeren.
Maar het is gemakkelijk om verblind te raken door de absoluutheid van getallen, vooral wanneer ze geloofwaardigheid verlenen aan gunstige hypotheses of punten.
Het niet herkennen van onjuiste statistieken en gegevens is een bedreiging voor gegevensgestuurde besluitvorming.
Het moedigt je aan om vol vertrouwen op de spreekwoordelijke verkeerde knoppen te drukken, en daar schuilt het gevaar.
In deze post leer je hoe je misleidende statistieken en gegevens kunt spotten. We zullen kijken naar de veelvoorkomende manieren waarop ze misleiden, en hoe u kunt bepalen wanneer gegevens het gewicht van cruciale beslissingen kunnen dragen.
- Wat is een misleidende statistiek?
- Selectieve vooringenomenheid om valse statistieken te creëren
- Verwaarloosde steekproefgrootte resulteert in valse precisie
- Foutieve correlaties en oorzakelijke verbanden om onjuiste statistieken te creëren
- misleidende grafieken en visuals
- Conclusie: Bescherming tegen misleidende gegevens en statistieken
- Over de auteur
Wat is een misleidende statistiek?
Bron
misleidende statistieken ontstaan wanneer er sprake is van een – al dan niet opzettelijke – fout in een van de 3 belangrijkste aspecten van onderzoek:
-
Verzameling: Het gebruik van kleine steekproeven die grote aantallen laten zien, maar weinig statistische significantie hebben.
-
Organiseren: Weglaten van bevindingen die in tegenspraak zijn met het punt dat de onderzoeker probeert te bewijzen.
-
Presenteren: Manipuleren van visuele/numerieke gegevens om de perceptie te beïnvloeden.
Slechte statistieken sluipen in nieuwsberichten, advertentiecampagnes en zelfs wetenschappelijke literatuur. Een schokkende 33,7% van de wetenschappers – de overtreffende trap van gegevensneutraliteit – heeft toegegeven misbruik te hebben gemaakt van statistieken ter ondersteuning van onderzoek. Ja, zelfs sommige van de samenlevingen vertrouwde poortwachters van informatie zijn schuldig.
Om u te helpen kritieke beslissingen te nemen op basis van de juiste gegevens, hebben we de veel voorkomende manieren opgesomd waarop statistieken misleiden en verkeerd informeren.
Selectieve vooringenomenheid om valse statistieken te creëren
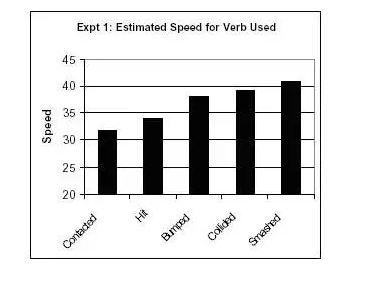
Een studie van Elizabeth Loftus testte de invloed van taal op ooggetuigenverklaringen. Proefpersonen kregen een film te zien met meerdere auto-ongelukken. Na het kijken werd hen gevraagd: “Hoe snel reden de auto’s toen ze op elkaar botsten?”
Andere proefpersonen werd vervolgens dezelfde vraag gesteld, zij het dat het woord “smashed” werd vervangen door suggestieve werkwoorden als:
-
Contacted
-
Hit
-
Bumped
-
Collided
De resultaten?
Hoe sterker het gebruikte “beladen” werkwoord, hoe hoger de snelheidsschatting van getuigen.
Bron
Verder bleek uit de studie dat wanneer een sterker werkwoord werd gebruikt, de proefpersonen eerder gebroken glas bij het ongeval meldden, ook al werd gebroken glas niet in de video getoond.
Het gebruik van taal om antwoorden op enquêtes en resultaten te beïnvloeden, is slechts één voorbeeld van selectievooringenomenheid. In 2007 dwong de Advertising Standards Authority (ASA) Colgate af te zien van hun claim dat “meer dan 80% van de tandartsen het gebruik van Colgate aanbeveelt”, omdat de claim misleidend impliceerde dat “80% van de tandartsen Colgate-tandpasta aanbeveelt in voorkeur boven alle andere merken”.
De eigenlijke enquêtevraag was “als ze de keuze kregen tussen alleen poetsen en het gebruik van een tandpasta – zoals Colgate – welke zouden ze aanbevelen?”
Door hun antwoorden op de enquête te kersenplukken, wekte Colgate de indruk dat tandartsen hen aanraadden boven merken van concurrenten; de werkelijke aanbeveling was dat het gebruik van een tandpasta superieur is aan alleen poetsen.
Selectieve vooringenomenheid doet zich vaak voor wanneer gekozen steekproeven of gegevens onvolledig zijn of met een kersje worden geplukt om de perceptie van – en zelfs scheefgetrokken – statistieken en gegevens te beïnvloeden.
Verwaarloosde steekproefgrootte resulteert in valse precisie

(bron)
90 mensen die “ja” antwoorden op 100 mensen (90%), tegenover 900 mensen die “ja” antwoorden op 1000 mensen (ook 90%); de percentages zijn vergelijkbaar, maar het verschil in waarde en geldigheid van de gegevens is statistisch significant.
Kleinere steekproefgroottes garanderen bijna alarmerend significante resultaten. Pas altijd op voor extreme resultaten, en accepteer percentages nooit zonder meer. In de woorden van biochemisch onderzoeker Ana-maria Sundic:
“Om ervoor te zorgen dat de steekproef representatief is voor een populatie, moet de steekproeftrekking willekeurig zijn, d.w.z. dat iedere proefpersoon evenveel kans moet hebben om in het onderzoek te worden opgenomen. Er zij op gewezen dat steekproefvertekening ook kan optreden als de steekproef te klein is om de doelpopulatie te vertegenwoordigen”
Foutieve correlaties en oorzakelijke verbanden om onjuiste statistieken te creëren
“Correlatie betekent niet causatie”.
Ongetwijfeld hebt u deze zin al eens eerder gehoord, maar hij is niet voor niets waar.
Wanneer twee variabelen correleren, geldt meestal het volgende:
-
Y veroorzaakt X.
-
X veroorzaakt Y.
-
Een derde factor brengt X + Y teweeg.
-
De correlatie is te wijten aan toeval.
Correlatie en causaliteit zijn zeer verdacht omdat onderzoekers – en consumenten van genoemd onderzoek – ten prooi vallen aan:
-Correlatiefetisjisme
-Correlatiejacht
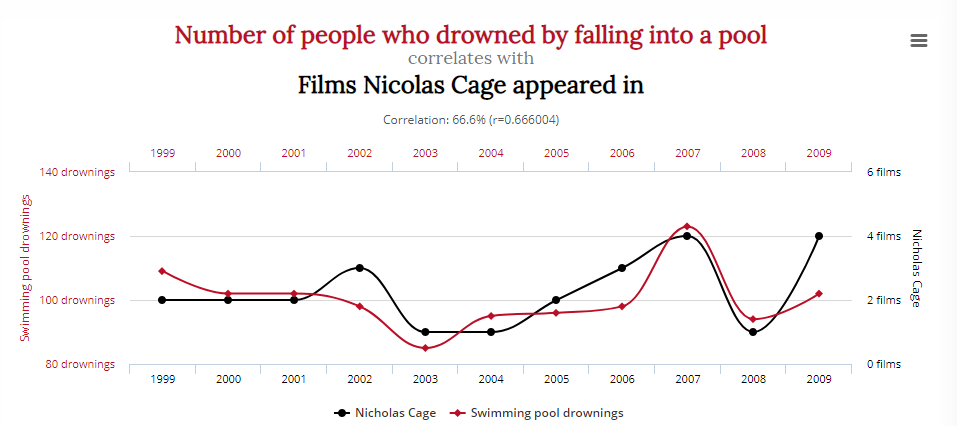
Tyler Vegihn heeft een aantal grappige voorbeelden van misleidende statistieken verzameld om precies dit punt te bewijzen:
Deze grafiek toont een overtuigende correlatie tussen het aantal mensen dat verdronk toen ze in een zwembad vielen en het aantal films waarin Nicolas Cage verscheen:
Een andere toont een correlatie tussen het aantal mensen dat stierf door verstrikt te raken in beddenlakens, en de kaasconsumptie:
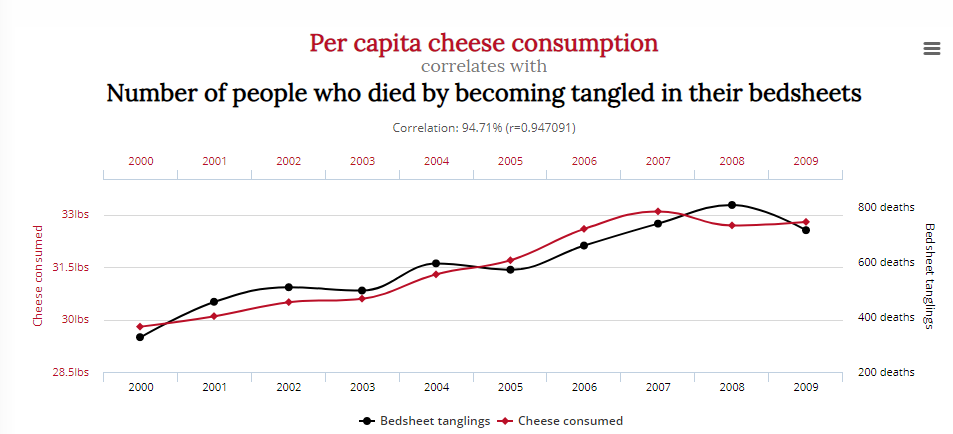
Betekent dit dat het verminderen van de kaasconsumptie en de acteerrollen van Nicolas Cage levens zal redden? Waarschijnlijk niet.
Gezien het feit dat onderzoekers onder druk staan om bruikbare gegevens te ontdekken of een hypothese te bewijzen, is de verleiding groot om voorbarig een “aha”- of “eureka”-moment uit te roepen.
Dit vormt een probleem voor gezonde analyses en statistieken; gooi er genoeg variabelen in, en je vindt bijna gegarandeerd een correlatie, met wat dan ook.
misleidende grafieken en visuals
Data visualisaties zetten ruwe getallen om in visuele representaties van belangrijke relaties, trends en patronen. Hoewel ze in staat zijn om uw gegevens tot leven te brengen, zijn ze ook een populair medium voor misleidende statistieken en gegevens.
In zijn boek “Graphics, Lies, Misleading Visuals,” legt data journalist Alberto Cairo misleidende statistische voorbeelden uit marketing advertenties, politieke campagnes en nieuwsberichtgeving bloot.
Een populair voorbeeld uit het nieuws is de zaak Terri Schiavo, een recht-op-dood rechtszaak in de VS.
Tijdens de rechtszaak werd een grafiek als de onderstaande door CNN gebruikt om weer te geven hoe de verschillende politieke groeperingen dachten over het verwijderen van Terri’s life support:
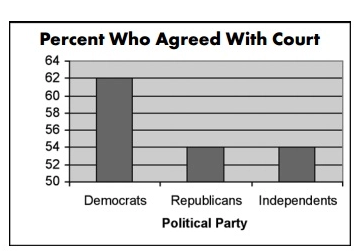
Bron
Een blik op deze grafiek suggereert dat in vergelijking met Republikeinen en Onafhankelijken, 3 keer meer Democraten het eens waren met de rechtbank
Bij nadere beschouwing blijkt er echter een klein verschil van 14% in stemmen te zijn.
De afgeknotte grafiek en geknoeide Y-as (beginnend bij 50 in plaats van 0) vertekenen de gegevens, en leiden ertoe dat je een overdreven idee over een bepaalde groep gelooft.
Voorkom dat je wordt misleid bij het bekijken van grafieken en visuals door uit te kijken naar:
-
Het weglaten van de basislijn of afgeknotte as op een grafiek.
-
De intervallen en schalen. Controleer op ongelijke toenames en vreemde metingen (gebruik van getallen in plaats van percentages enz.).
-
De volledige context en andere vergelijkende grafieken om te zien hoe soortgelijke gegevens worden gemeten en weergegeven.
Conclusie: Bescherming tegen misleidende gegevens en statistieken
Misleidende statistieken en gegevens gaan prat op grandioze verbeteringen van het conversiepercentage met “CTA-tweaks” en “eenvoudige kleurwijzigingen”.
Ze creëren schokkende koppen die massa’s verkeer aantrekken, maar op zijn best gebrekkige inzichten bieden.
Slechte statistieken en gegevens zijn gevaarlijk.
In plaats van u te helpen navigeren door omwegen, kuilen en valkuilen, sturen ze u bewust – of onbewust – recht in hen. Maar jij bent slim genoeg om ze te herkennen.
De volgende keer dat je overtuigende gegevens tegenkomt, loop dan deze eenvoudige maar krachtige vragen langs:
Wie doet het onderzoek?
Onderzoek is duur en tijdrovend. Ga na wie het sponsort, weeg hun vooringenomenheid over het onderwerp af en hoe zij zouden kunnen profiteren van de resultaten. Is het een B2C-bedrijf met een product? Een adviesbureau? Een onafhankelijke, door een universiteit gefinancierde studie?
Kunnen de steekproefgrootte en de lengte van de studie serieus worden genomen?
Inspectie van de ondersteunende of versluierde cijfers zal zwakke statistische kracht blootleggen.
Worden de gegevens visueel eerlijk weergegeven?
Zijn de schalen en intervallen gelijkmatig verdeeld en neutraal? Drukt een statistiek een specifiek idee of agenda uit? Zijn er te veel statistieken in uw dashboard?
Wordt het onderzoek eerlijk en onpartijdig weergegeven?
Bekijk de gebruikte taal, de manier waarop de vraag is geformuleerd, en de mensen die worden ondervraagd.
Om te voorkomen dat misleidende statistieken en gegevens uw dashboards, rapporten en analyses vervuilen, begroet u nieuwe informatie met een nieuwsgierige en sceptische houding.
Over de auteur
Hassan Uddeen is een in het Verenigd Koninkrijk gevestigde freelance schrijver voor B2B, SaaS, en Fintech-bedrijven. Hij houdt van alles wat met content marketing te maken heeft. Wanneer hij zich los kan maken van het toetsenbord, houdt hij ervan om te stuiteren in zijn huis sportschool (terwijl hij een rollenspel speelt als Goku) en zich te verdiepen in een goede James Patterson roman.