I denne blog vil vi diskutere de grundlæggende begreber i logistisk regression, og hvilke problemer den kan hjælpe os med at løse.

Logistisk regression er en klassifikationsalgoritme, der anvendes til at tildele observationer til et diskret sæt af klasser. Nogle af eksemplerne på klassifikationsproblemer er e-mail-spam eller ikke-spam, online-transaktioner svindel eller ikke-svindel, tumor ondartet eller godartet. Logistisk regression transformerer sit output ved hjælp af den logistiske sigmoidfunktion for at returnere en sandsynlighedsværdi.
Hvad er typerne af logistisk regression
- Binær (f.eks. Tumor Malign eller Benign)
- Multi-lineære funktioner fejlerKlasse (f.eks. Katte, hunde eller får)
Logistisk regression
Logistisk regression er en maskinlæringsalgoritme, der bruges til klassifikationsproblemer, det er en algoritme til forudsigelsesanalyse og er baseret på begrebet sandsynlighed.

Vi kan kalde en logistisk regression for en lineær regressionsmodel, men den logistiske regression anvender en mere kompleks omkostningsfunktion, denne omkostningsfunktion kan defineres som “sigmoidfunktion” eller også kendt som “logistisk funktion” i stedet for en lineær funktion.
Hypotesen for logistisk regression går ud på at begrænse omkostningsfunktionen mellem 0 og 1. Derfor kan lineære funktioner ikke repræsentere den, da den kan have en værdi større end 1 eller mindre end 0, hvilket ikke er muligt i henhold til hypotesen for logistisk regression.
Hvad er den sigmoide funktion?
For at afbilde forudsagte værdier til sandsynligheder bruger vi den sigmoide funktion. Funktionen kortlægger enhver reel værdi til en anden værdi mellem 0 og 1. I maskinlæring bruger vi sigmoidfunktionen til at kortlægge forudsigelser til sandsynligheder.


Hypoteserepræsentation
Ved lineær regression brugte vi en formel for hypotesen, dvs.
hΘ(x) = β₀ + β₁X
For logistisk regression vil vi ændre den en lille smule i.e.
σ(Z) = σ(β₀ + β₁X)
Vi har forventet, at vores hypotese vil give værdier mellem 0 og 1.
Z = β₀ + β₁X
hΘ(x) = sigmoid(Z)
dvs. hΘ(x) = 1/(1 + e^-(β₀ + β₁X)

Beslutningsgrænsen
Vi forventer, at vores klassifikator giver os et sæt outputs eller klasser baseret på sandsynlighed, når vi sender input gennem en forudsigelsesfunktion og returnerer en sandsynlighedsscore mellem 0 og 1.
For eksempel, Vi har 2 klasser, lad os tage dem som katte og hunde(1 – hund , 0 – katte). Vi beslutter grundlæggende med en tærskelværdi, over hvilken vi klassificerer værdier i klasse 1, og hvis værdien går under tærsklen, så klassificerer vi den i klasse 2.
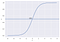
Som vist i ovenstående graf har vi valgt tærskelværdien som 0,5, hvis forudsigelsesfunktionen returnerede en værdi på 0,7, ville vi klassificere denne observation som klasse 1 (HUND). Hvis vores forudsigelse returnerede en værdi på 0,2, ville vi klassificere observationen som klasse 2(CAT).
Kostfunktion
Vi lærte om omkostningsfunktionen J(θ) i den lineære regression, omkostningsfunktionen repræsenterer optimeringsmålet, dvs. vi opretter en omkostningsfunktion og minimerer den, så vi kan udvikle en præcis model med minimal fejl.
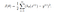
Hvis vi forsøger at bruge omkostningsfunktionen for den lineære regression i ‘logistisk regression’, så ville den ikke være til nogen nytte, da den ville ende med at blive en ikke-konveks funktion med mange lokale minima, hvor det ville være meget vanskeligt at minimere omkostningsværdien og finde det globale minimum.

For logistisk regression er omkostningsfunktionen defineret som:
-log(hθ(x)) hvis y = 1
-log(1-hθ(x)) hvis y = 0
