- Estrategias populares para imputar estadísticamente los valores perdidos en un conjunto de datos.
- 2- Imputación utilizando valores (media/mediana):
- 3- Imputación usando valores (más frecuentes) o (cero/constantes):
- 4- Imputación mediante k-NN:
- ¿Cómo funciona?
- 5- Imputación mediante imputación multivariante por ecuación encadenada (MICE)
- 6- Imputation Using Deep Learning (Datawig):
- Imputación por regresión estocástica:
- Extrapolación e interpolación:
- Imputación Hot-Deck:
Estrategias populares para imputar estadísticamente los valores perdidos en un conjunto de datos.
Muchos conjuntos de datos del mundo real pueden contener valores perdidos por diversas razones. A menudo se codifican como NaNs, espacios en blanco o cualquier otro marcador de posición. Entrenar un modelo con un conjunto de datos que tiene muchos valores perdidos puede afectar drásticamente a la calidad del modelo de aprendizaje automático. Algunos algoritmos como los estimadores de scikit-learn asumen que todos los valores son numéricos y tienen y mantienen un valor significativo.
Una forma de manejar este problema es deshacerse de las observaciones que tienen datos perdidos. Sin embargo, se corre el riesgo de perder puntos de datos con información valiosa. Una estrategia mejor sería imputar los valores que faltan. En otras palabras, tenemos que inferir esos valores que faltan a partir de la parte existente de los datos. Hay tres tipos principales de datos perdidos:
- Se pierden completamente al azar (MCAR)
- Se pierden al azar (MAR)
- No se pierden al azar (NMAR)
Sin embargo, en este artículo, me centraré en 6 formas populares para la imputación de datos para conjuntos de datos transversales ( El conjunto de datos de series temporales es una historia diferente ).
Esto es fácil. Sólo hay que dejar que el algoritmo maneje los datos que faltan. Algunos algoritmos pueden tener en cuenta los valores perdidos y aprender los mejores valores de imputación para los datos perdidos basados en la reducción de pérdidas de entrenamiento (por ejemplo, XGBoost). Otros tienen la opción de ignorarlos (por ejemplo, LightGBM – use_missing=false). Sin embargo, otros algoritmos entrarán en pánico y lanzarán un error quejándose de los valores que faltan (por ejemplo, Scikit learn – LinearRegression). En ese caso, tendrá que manejar los datos que faltan y limpiarlos antes de alimentar al algoritmo.
Veamos otras formas de imputar los valores que faltan antes del entrenamiento:
Nota: Todos los ejemplos siguientes utilizan el conjunto de datos de viviendas de California de Scikit-learn.
2- Imputación utilizando valores (media/mediana):
Esto funciona calculando la media/mediana de los valores no perdidos en una columna y luego reemplazando los valores perdidos dentro de cada columna por separado e independientemente de los demás. Sólo puede utilizarse con datos numéricos.

Pros:
- Fácil y rápido.
- Funciona bien con pequeños conjuntos de datos numéricos.
Cons:
- No factoriza las correlaciones entre características. Sólo funciona a nivel de columna.
- Dará malos resultados en características categóricas codificadas (NO lo use en características categóricas).
- No es muy preciso.
- No tiene en cuenta la incertidumbre en las imputaciones.
3- Imputación usando valores (más frecuentes) o (cero/constantes):
La más frecuente es otra estrategia estadística para imputar valores perdidos y ¡¡SÍ! Funciona con características categóricas (cadenas o representaciones numéricas) sustituyendo los datos perdidos por los valores más frecuentes dentro de cada columna.
Pros:
- Funciona bien con características categóricas.
Cons:
- Tampoco factoriza las correlaciones entre características.
- Puede introducir sesgos en los datos.
Imputación nula o constante -como su nombre indica- sustituye los valores perdidos por cero o por cualquier valor constante que se especifique

4- Imputación mediante k-NN:
Los k vecinos más cercanos es un algoritmo que se utiliza para la clasificación simple. El algoritmo utiliza la «similitud de características» para predecir los valores de cualquier punto de datos nuevo. Esto significa que al nuevo punto se le asigna un valor basado en su parecido con los puntos del conjunto de entrenamiento. Esto puede ser muy útil para hacer predicciones sobre los valores que faltan, encontrando los k vecinos más cercanos a la observación con datos perdidos y luego imputándolos en base a los valores no perdidos en la vecindad. Veamos un código de ejemplo utilizando la biblioteca Impyute que proporciona una forma sencilla y fácil de utilizar KNN para la imputación:
¿Cómo funciona?
Crea una imputación media básica y luego utiliza la lista completa resultante para construir un KDTree. A continuación, utiliza el KDTree resultante para calcular los vecinos más cercanos (NN). Después de encontrar los k-NNs, toma la media ponderada de ellos.
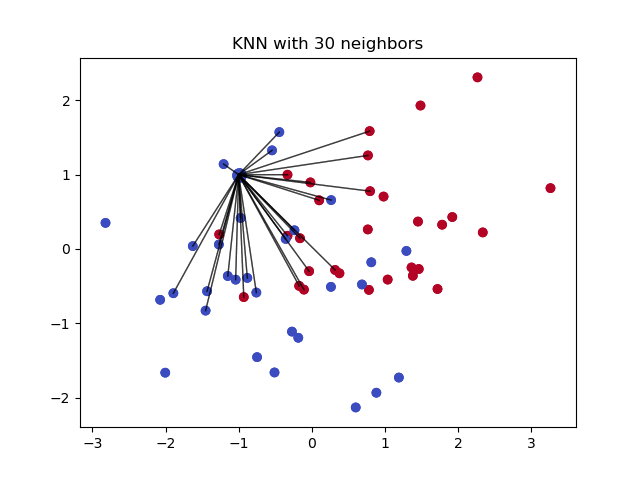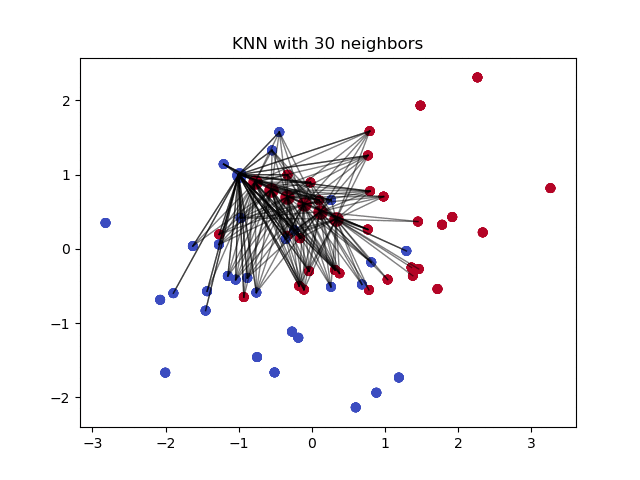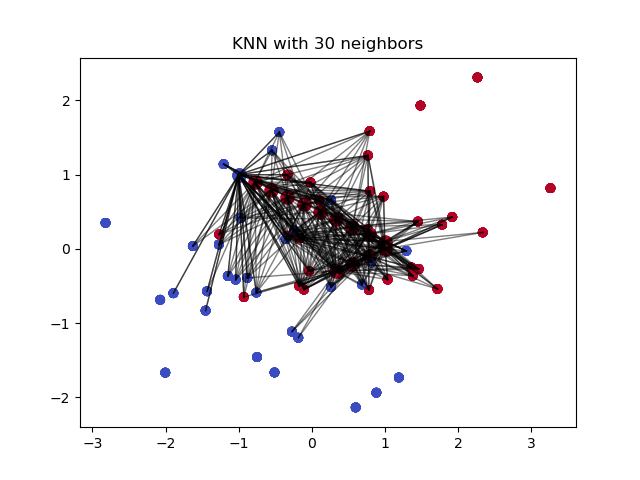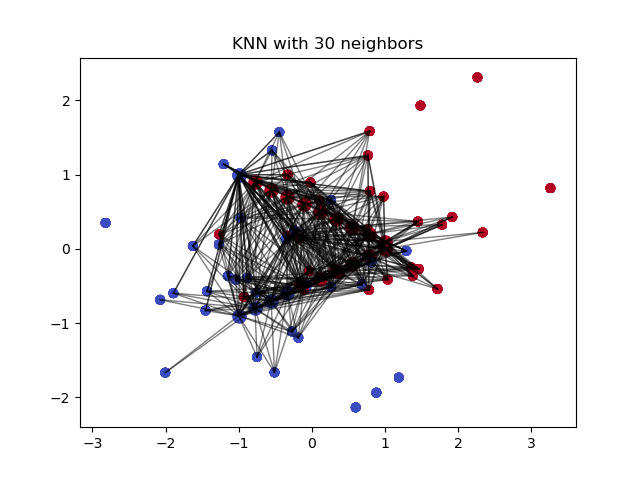
Pros:
- Puede ser mucho más preciso que la media, la mediana o los métodos de imputación más frecuentes (Depende del conjunto de datos).
Contra:
- Caros desde el punto de vista informático. KNN funciona almacenando todo el conjunto de datos de entrenamiento en memoria.
- K-NN es bastante sensible a los valores atípicos en los datos (a diferencia de SVM)
5- Imputación mediante imputación multivariante por ecuación encadenada (MICE)
Este tipo de imputación funciona rellenando los datos que faltan varias veces. Las imputaciones múltiples (IM) son mucho mejores que una imputación única, ya que mide mejor la incertidumbre de los valores perdidos. El enfoque de las ecuaciones encadenadas también es muy flexible y puede manejar diferentes variables de distintos tipos de datos (es decir, continuos o binarios), así como complejidades como los límites o los patrones de omisión de la encuesta. Para más información sobre la mecánica del algoritmo, puede consultar el documento de investigación

6- Imputation Using Deep Learning (Datawig):
Este método funciona muy bien con características categóricas y no numéricas. Es una biblioteca que aprende modelos de aprendizaje automático utilizando redes neuronales profundas para imputar valores perdidos en un marco de datos. También soporta tanto la CPU como la GPU para el entrenamiento.
Pros:
- Muy preciso en comparación con otros métodos.
- Tiene algunas funciones que pueden manejar datos categóricos (Feature Encoder).
- Soporta CPUs y GPUs.
Cons:
- Imputación de una sola columna.
- Puede ser bastante lento con grandes conjuntos de datos.
- Tiene que especificar las columnas que contienen información sobre la columna objetivo que será imputada.
Imputación por regresión estocástica:
Es bastante similar a la imputación por regresión que trata de predecir los valores perdidos haciendo una regresión a partir de otras variables relacionadas en el mismo conjunto de datos más algún valor residual aleatorio.
Extrapolación e interpolación:
Intenta estimar los valores a partir de otras observaciones dentro del rango de un conjunto discreto de puntos de datos conocidos.
Imputación Hot-Deck:
Trabaja eligiendo aleatoriamente el valor que falta de un conjunto de variables relacionadas y similares.
En conclusión, no hay una forma perfecta de compensar los valores que faltan en un conjunto de datos. Cada estrategia puede funcionar mejor para ciertos conjuntos de datos y tipos de datos perdidos, pero puede funcionar mucho peor en otros tipos de conjuntos de datos. Hay algunas reglas establecidas para decidir qué estrategia utilizar para determinados tipos de valores perdidos, pero más allá de eso, debe experimentar y comprobar qué modelo funciona mejor para su conjunto de datos.