En este blog, discutiremos los conceptos básicos de la regresión logística y qué tipo de problemas puede ayudarnos a resolver.

La regresión logística es un algoritmo de clasificación utilizado para asignar observaciones a un conjunto discreto de clases. Algunos de los ejemplos de problemas de clasificación son Correo electrónico spam o no spam, Transacciones en línea fraude o no fraude, Tumor maligno o benigno. La regresión logística transforma su salida utilizando la función sigmoidea logística para devolver un valor de probabilidad.
Cuáles son los tipos de regresión logística
- Binaria (ej. Tumor Maligno o Benigno)
- Funciones multilineales fallaClase (ej. Gatos, perros u ovejas)
Regresión Logística
La Regresión Logística es un algoritmo de Aprendizaje Automático que se utiliza para los problemas de clasificación, es un algoritmo de análisis predictivo y se basa en el concepto de probabilidad.

Podemos llamar Regresión Logística a un modelo de Regresión Lineal pero la Regresión Logística utiliza una función de coste más compleja, esta función de coste puede definirse como la «función sigmoidea» o también conocida como la «función logística» en lugar de una función lineal.
La hipótesis de la regresión logística tiende a limitar la función de coste entre 0 y 1. Por lo tanto las funciones lineales fallan al representarla ya que puede tener un valor mayor que 1 o menor que 0 lo cual no es posible según la hipótesis de la regresión logística.
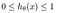
¿Qué es la función sigmoidea?
Para mapear valores predichos a probabilidades, utilizamos la función sigmoidea. La función mapea cualquier valor real en otro valor entre 0 y 1. En el aprendizaje automático, utilizamos la sigmoide para mapear las predicciones a las probabilidades.


Representación de la hipótesis
Al utilizar la regresión lineal utilizamos una fórmula de la hipótesis i.e.
hΘ(x) = β₀ + β₁X
Para la regresión logística vamos a modificarla un poco i.e.
σ(Z) = σ(β₀ + β₁X)
Hemos esperado que nuestra hipótesis dé valores entre 0 y 1.
Z = β₀ + β₁X
hΘ(x) = sigmoide(Z)
es decir hΘ(x) = 1/(1 + e^-(β₀ + β₁X)

Límite de decisión
.
Esperamos que nuestro clasificador nos dé un conjunto de salidas o clases basadas en la probabilidad cuando pasamos las entradas por una función de predicción y devuelve una puntuación de probabilidad entre 0 y 1.
Por ejemplo, tenemos 2 clases, tomémoslas como gatos y perros(1 – perro , 0 – gatos). Básicamente decidimos con un valor de umbral por encima del cual clasificamos los valores en la clase 1 y del valor va por debajo del umbral entonces lo clasificamos en la clase 2.
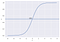
Como se muestra en el gráfico anterior hemos elegido el umbral como 0,5, si la función de predicción devuelve un valor de 0,7 entonces clasificaríamos esta observación como Clase 1(PERRO). Si nuestra predicción devuelve un valor de 0,2 entonces clasificaríamos la observación como Clase 2(GATO).
Función de Coste
Aprendimos sobre la función de coste J(θ) en la Regresión Lineal, la función de coste representa el objetivo de optimización, es decir, creamos una función de coste y la minimizamos para poder desarrollar un modelo preciso con un error mínimo.
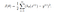
Si intentamos utilizar la función de coste de la regresión lineal en la ‘Regresión Logística’ entonces no serviría de nada ya que acabaría siendo una función no convexa con muchos mínimos locales, en la que sería muy difícil minimizar el valor del coste y encontrar el mínimo global.

Para la regresión logística, la función Coste se define como:
-log(hθ(x)) si y = 1
-log(1-hθ(x)) si y = 0

.