Dans ce blog, nous allons discuter des concepts de base de la régression logistique et de quel type de problèmes elle peut nous aider à résoudre.

La régression logistique est un algorithme de classification utilisé pour affecter des observations à un ensemble discret de classes. Certains des exemples de problèmes de classification sont les suivants : spam ou non spam, transactions en ligne frauduleuses ou non frauduleuses, tumeur maligne ou bénigne. La régression logistique transforme sa sortie en utilisant la fonction sigmoïde logistique pour renvoyer une valeur de probabilité.
Quels sont les types de régression logistique
- Binaire (ex. Tumeur Maligne ou Bénigne)
- Fonctions multi-linéaires failsClass (ex. Chats, chiens ou moutons)
Régression logistique
La régression logistique est un algorithme de Machine Learning qui est utilisé pour les problèmes de classification, c’est un algorithme d’analyse prédictive et basé sur le concept de probabilité.

Nous pouvons appeler une régression logistique un modèle de régression linéaire mais la régression logistique utilise une fonction de coût plus complexe, cette fonction de coût peut être définie comme la ‘fonction Sigmoïde’ ou aussi connue comme la ‘fonction logistique’ au lieu d’une fonction linéaire.
L’hypothèse de la régression logistique tend elle à limiter la fonction de coût entre 0 et 1. Les fonctions linéaires ne parviennent donc pas à la représenter car elle peut avoir une valeur supérieure à 1 ou inférieure à 0, ce qui n’est pas possible selon l’hypothèse de la régression logistique.
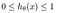
Qu’est-ce que la fonction sigmoïde?
Pour faire correspondre des valeurs prédites à des probabilités, nous utilisons la fonction sigmoïde. Cette fonction fait correspondre toute valeur réelle à une autre valeur comprise entre 0 et 1. En apprentissage automatique, nous utilisons la fonction sigmoïde pour faire correspondre les prédictions aux probabilités.


Représentation de l’hypothèse
Lorsque nous avons utilisé une formule de l’hypothèse c’est-à-dire
hΘ(x) = β₀ + β₁X
Pour la régression logistique, nous allons la modifier un peu c’est-à-dire.e.
σ(Z) = σ(β₀ + β₁X)
Nous avons prévu que notre hypothèse donnera des valeurs entre 0 et 1.
Z = β₀ + β₁X
hΘ(x) = sigmoïde(Z)
c’est-à-dire. hΘ(x) = 1/(1 + e^-(β₀ + β₁X)

La limite de décision
.
Nous attendons de notre classificateur qu’il nous donne un ensemble de sorties ou de classes basées sur la probabilité lorsque nous passons les entrées à travers une fonction de prédiction et renvoie un score de probabilité entre 0 et 1.
Par exemple, nous avons 2 classes, prenons-les comme les chats et les chiens(1 – chien , 0 – chats). Nous décidons essentiellement avec une valeur seuil au-dessus de laquelle nous classons les valeurs dans la classe 1 et de la valeur va en dessous du seuil alors nous le classons dans la classe 2.
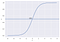
Comme le montre le graphique ci-dessus, nous avons choisi le seuil de 0,5, si la fonction de prédiction a retourné une valeur de 0,7 alors nous classerions cette observation dans la classe 1(CHIEN). Si notre prédiction a retourné une valeur de 0,2 alors nous classerions l’observation comme classe 2(CAT).
Fonction de coût
Nous avons appris la fonction de coût J(θ) dans la régression linéaire, la fonction de coût représente l’objectif d’optimisation c’est-à-dire que nous créons une fonction de coût et la minimisons afin de pouvoir développer un modèle précis avec une erreur minimale.
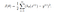
Si nous essayons d’utiliser la fonction de coût de la régression linéaire dans la ‘Régression logistique’, alors elle ne serait d’aucune utilité car elle finirait par être une fonction non convexe avec de nombreux minimums locaux, dans laquelle il serait très difficile de minimiser la valeur du coût et de trouver le minimum global.

Pour la régression logistique, la fonction Coût est définie comme :
-log(hθ(x)) si y = 1
-log(1-hθ(x)) si y = 0

.