Ebben a blogban a logisztikus regresszió alapfogalmairól lesz szó és arról, hogy milyen problémák megoldásában segíthet nekünk.

A logisztikus regresszió egy osztályozási algoritmus, amelyet arra használnak, hogy a megfigyeléseket diszkrét osztályok halmazába sorolják. Néhány példa az osztályozási problémákra: Email spam vagy nem spam, Online tranzakciók csalás vagy nem csalás, Tumor rosszindulatú vagy jóindulatú. A logisztikus regresszió a kimenetét a logisztikus szigmoid függvény segítségével alakítja át, hogy valószínűségi értéket adjon vissza.
Melyek a logisztikus regresszió típusai
- Bináris (pl. Tumor rosszindulatú vagy jóindulatú)
- Multi-lineáris függvényekFüggvényekClass (Pl. Macskák, kutyák vagy juhok)
Logisztikus regresszió
A logisztikus regresszió egy gépi tanulási algoritmus, amelyet osztályozási problémákra használnak, ez egy prediktív elemző algoritmus és a valószínűség fogalmán alapul.

A logisztikus regressziót nevezhetjük lineáris regressziós modellnek, de a logisztikus regresszió egy összetettebb költségfüggvényt használ, ezt a költségfüggvényt lineáris függvény helyett “szimmoid függvényként” vagy más néven “logisztikus függvényként” is definiálhatjuk.
A logisztikus regresszió hipotézise arra hajlamos, hogy a költségfüggvényt 0 és 1 közé korlátozza. Ezért a lineáris függvények nem képesek reprezentálni, mivel 1-nél nagyobb vagy 0-nál kisebb értéket vehet fel, ami a logisztikus regresszió hipotézise szerint nem lehetséges.
Mi a szimmoidfüggvény?
Az előrejelzett értékek valószínűségekre való leképezéséhez a szimmoidfüggvényt használjuk. A függvény bármely valós értéket leképez egy másik 0 és 1 közötti értékre. A gépi tanulásban a sigmoidot arra használjuk, hogy az előrejelzéseket valószínűségekre képezzük le.


hΘ(x) = β₀ + β₁X
A logisztikus regresszió esetében ezt egy kicsit módosítjuk i.Pl.
σ(Z) = σ(β₀ + β₁X)
Azt vártuk, hogy a hipotézisünk 0 és 1 közötti értékeket fog adni.
Z = β₀ + β₁X
hΘ(x) = sigmoid(Z)
azaz. hΘ(x) = 1/(1 + e^-(β₀ + β₁X)

Döntési határ
.
Az osztályozónktól azt várjuk, hogy a kimenetek vagy osztályok egy halmazát adja meg a valószínűség alapján, amikor a bemeneteket átadjuk egy előrejelző függvényen, és egy 0 és 1 közötti valószínűségi pontszámot ad vissza.
Példa: Van 2 osztályunk, vegyük őket macskáknak és kutyáknak (1 – kutya , 0 – macskák). Alapvetően egy küszöbértékkel döntünk, amely felett az értékeket az 1. osztályba soroljuk, és ha az érték a küszöbérték alá megy, akkor a 2. osztályba soroljuk.
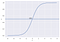
A fenti grafikonon látható módon a küszöbértéket 0,5-re választottuk, ha a predikciós függvény 0,7-es értéket adna vissza, akkor ezt a megfigyelést az 1. osztályba(KUTYA) sorolnánk. Ha az előrejelzésünk 0,2 értéket adna vissza, akkor a megfigyelést a 2. osztályba (CAT) sorolnánk.
Költségfüggvény
A lineáris regresszióban megismertük a J(θ) költségfüggvényt, a költségfüggvény optimalizálási célt képvisel, azaz létrehozunk egy költségfüggvényt és minimalizáljuk azt, hogy egy pontos modellt tudjunk kialakítani minimális hibával.
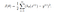
Ha a lineáris regresszió költségfüggvényét megpróbálnánk használni a “logisztikus regresszióban”, akkor az nem lenne hasznos, mivel a végén egy nem konvex függvény lenne sok helyi minimummal, amelyben nagyon nehéz lenne minimalizálni a költségértéket és megtalálni a globális minimumot.

A logisztikus regresszió esetében a költségfüggvényt a következőképpen határozzuk meg:
-log(hθ(x)) ha y = 1
-log(1-hθ(x)) ha y = 0
