- Popular strategies to statistically impute missing values in a dataset.
- 2- (Mean/Median) Values を使用したインピュテーション:
- 3- (Most Frequent) or (Zero/Constant) Values を使ったインプット:
- 4-k-NN によるインピュテーションを使用します。
- How does it work?
- 5-. MICE(Multivariate Imputation by Chained Equation)を用いたインピュテーション
- 6- Imputation Using Deep Learning (Datawig) が参照可能です。
- 確率的回帰インピュテーション:
- 外挿と内挿:
- ホットデッキの帰属:
Popular strategies to statistically impute missing values in a dataset.
Many real world datasets may include missing values for various reasons.Why did? それらはしばしばNaN、空白、あるいは他のプレースホルダーとして符号化されます。 多くの欠損値を持つデータセットでモデルを訓練すると、機械学習モデルの品質に劇的な影響を与える可能性があります。 scikit-learn の推定値などの一部のアルゴリズムでは、すべての値が数値であり、意味のある値を持ち、保持すると仮定します。
この問題を処理する 1 つの方法は、欠損データを持つオブザベーションを削除することです。 しかし、貴重な情報を持つデータ・ポイントを失う危険性があります。 より良い戦略は、欠損値をインプットすることであろう。 言い換えると、データの既存の部分からそれらの欠損値を推測する必要がある。 欠測には主に3種類あります。
- Missing completely at random (MCAR)
- Missing at random (MAR)
- Not missing at random (NMAR)
しかし今回はクロスセクションデータセット(時系列データは別物)のデータインピュテーションによく用いられる6種類の方法に焦点を当てて説明します。
それは簡単なことです。 アルゴリズムに欠損データを処理させればいいだけです。 いくつかのアルゴリズムは、欠損値を考慮し、トレーニングの損失削減に基づいて欠損データに対する最適なインピュテーション値を学習することができます(XGBoostなど)。 また、欠損値を無視するオプションもあります(例:LightGBM – use_missing=false)。 しかし、他のアルゴリズムはパニックになり、欠損値について文句を言うエラーを投げます (例: Scikit learn – LinearRegression)。
学習前に欠損値をインプットする他の方法をいくつか見てみましょう。
Note: 以下のすべての例は、Scikit-learn の California Housing Dataset を使用しています。
2- (Mean/Median) Values を使用したインピュテーション:
これは、列内の非欠測値の平均/中央値を計算し、各列内の欠測値を他から個別に独立して置き換えることで動作します。 5437>

Pros:
- 簡単で高速です。
- 小さな数値データセットでうまく機能する。
Cons:
- 特徴間の相関を考慮しない。 列レベルでのみ動作します。
- エンコードされたカテゴリ特徴では良い結果は得られません(カテゴリ特徴では使用しないでください)。
3- (Most Frequent) or (Zero/Constant) Values を使ったインプット:
Most Frequent は欠損値をインプットするもうひとつの統計的戦略で、イエス!を意味します。 5437>
Pros:
- Works well with categorical features.
Cons:
- 特徴間の相関を考慮しない。
Zero or Constant imputation – その名の通り、欠損値をゼロまたは指定した任意の定値に置き換える

4-k-NN によるインピュテーションを使用します。
k-最近傍は、単純な分類に使用されるアルゴリズムである。 このアルゴリズムは、新しいデータポイントの値を予測するために「特徴の類似性」を使用します。 これは、新しいポイントが、学習セット内のポイントにどれだけ似ているかに基づいて値が割り当てられることを意味します。 これは、データが欠損しているオブザベーションに最も近いkの近傍を見つけ、近傍の欠損していない値に基づいてそれらを代入することにより、欠損値についての予測を行う際に非常に有用である。
How does it work?
Basic mean impute を作成して、結果の完全リストを KDTree を構築するために使用します。 次に、結果の KDTree を使用して最近傍 (NN) を計算します。
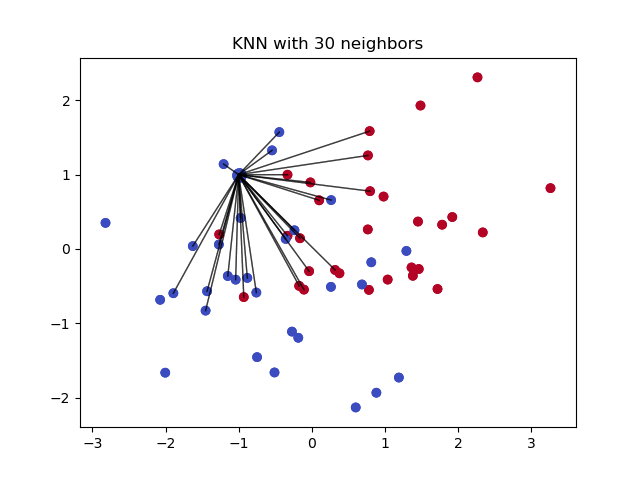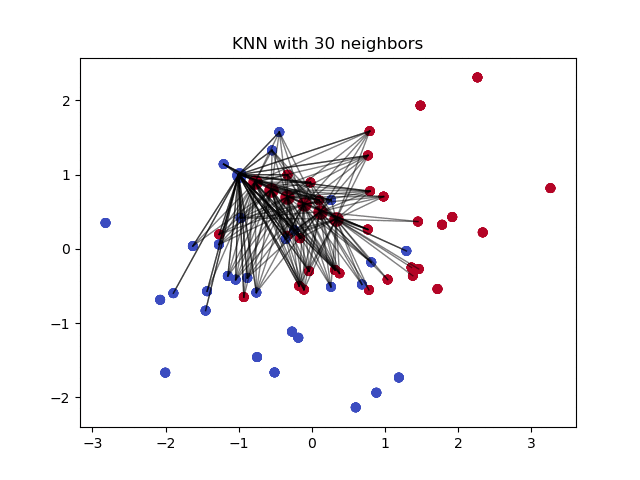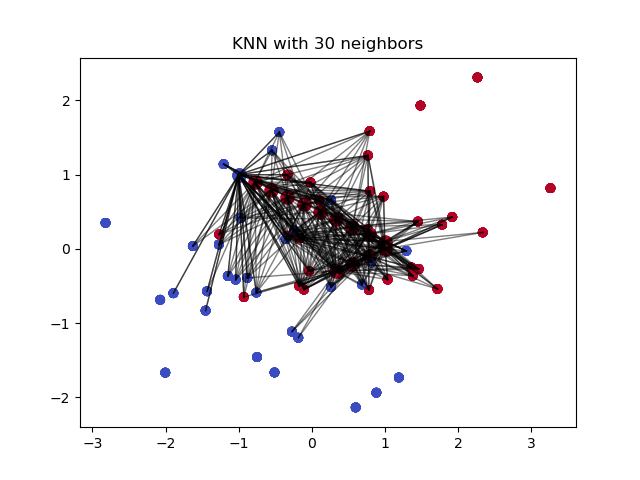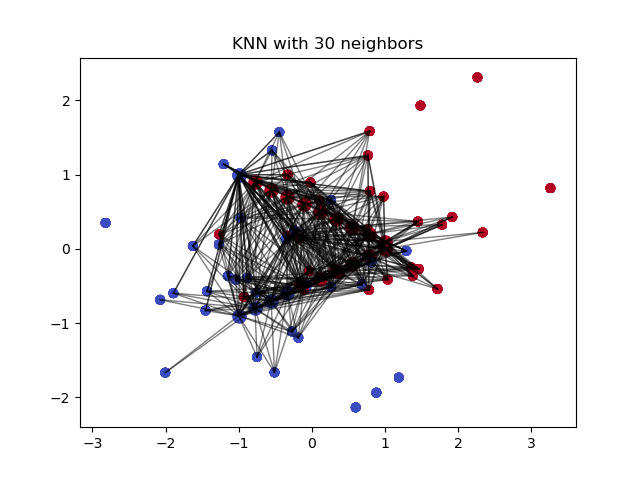
長所:
- mean, median または most frequent imputation method よりはるかに正確です(データセットに依存します)。
Cons:
- 計算が高い。 KNNは学習データセット全体をメモリに保存することで動作する。
- K-NNはデータの異常値に対してかなり敏感である(SVMとは異なる)
5-. MICE(Multivariate Imputation by Chained Equation)を用いたインピュテーション
このタイプのインピュテーションは欠損データを複数回埋めることによって動作します。 Multiple Imputations (MIs) は、より良い方法で欠損値の不確実性を測定するため、単一のインピュテーションよりもはるかに優れています。 連鎖式アプローチはまた、非常に柔軟で、異なるデータ型(すなわち、連続またはバイナリ)の異なる変数だけでなく、境界や調査のスキップパターンのような複雑なものを扱うことができます。 アルゴリズムの仕組みの詳細については、研究論文

6- Imputation Using Deep Learning (Datawig) が参照可能です。
この方法は、カテゴリカルおよび非数値的な特徴で非常によく機能します。 これは、Deep Neural Networks を使用して機械学習モデルを学習し、データフレーム内の欠損値をインプットするライブラリです。
Pros:
- 他の方法と比較してかなり正確。
- カテゴリデータを扱えるいくつかの関数(Feature Encoder)を持っています。
- CPUとGPUをサポートしています。
Cons:
- 単一列のインピュテーション。
- 大きなデータセットでかなり遅くなることがあります。
- インプットされるターゲット列に関する情報を含む列を指定する必要があります。
確率的回帰インピュテーション:
同じデータセット内の他の関連変数といくつかのランダムな残差値から回帰して欠損値を予測しようとする回帰インピュテーションとよく似ている。
外挿と内挿:
既知のデータポイントの離散セットの範囲内で他の観測から値を推定しようとします。
ホットデッキの帰属:
関連と同様の変数のセットからランダムに欠損値を選択することによって動作します。 各戦略は、特定のデータセットや欠損データの種類に対してより良いパフォーマンスを発揮することができますが、他の種類のデータセットでははるかに悪いパフォーマンスを発揮する可能性があります。 特定のタイプの欠損値にどの戦略を使用するかを決定するためのいくつかのセットルールがありますが、それ以上に、あなたのデータセットに最適なモデルを実験して確認する必要があります
。