- Estratégias populares para imputar estatisticamente valores em falta em um conjunto de dados.
- 2- Imputação Usando Valores (Média/Mediana):
- 3- Imputação Usando Valores (Mais Frequentes) ou (Zero/Constante):
- 4- Imputação Usando k-NN:
- Como funciona?
- 5- Imputação Usando Imputação Multivariada por Equação Encadeada (MICE)
- 6- Imputação usando Deep Learning (Datawig):
- Imputação de regressão estocástica:
- Extrapolação e Interpolação:
- AtribuiçãoHot-Deck:
Estratégias populares para imputar estatisticamente valores em falta em um conjunto de dados.
Muitos conjuntos de dados do mundo real podem conter valores em falta por várias razões. Eles são frequentemente codificados como NaNs, espaços em branco ou qualquer outro espaço reservado. Treinar um modelo com um conjunto de dados que tem muitos valores em falta pode impactar drasticamente a qualidade do modelo de aprendizagem da máquina. Alguns algoritmos como os estimadores scikit-learn assumem que todos os valores são numéricos e têm e mantêm valores significativos.
Uma maneira de lidar com este problema é se livrar das observações que têm dados em falta. No entanto, você corre o risco de perder pontos de dados com informações valiosas. Uma estratégia melhor seria imputar os valores que faltam. Em outras palavras, precisamos inferir esses valores faltantes a partir da parte existente dos dados. Existem três tipos principais de dados em falta:
- Missing completamente ao acaso (MCAR)
- Missing at random (MAR)
- Não faltando ao acaso (NMAR)
No entanto, neste artigo, vou focar em 6 formas populares de imputação de dados para conjuntos de dados transversais ( conjunto de dados da série temporal é uma história diferente ).
Essa é fácil. Basta deixar o algoritmo tratar dos dados em falta. Alguns algoritmos podem fatorar os valores em falta e aprender os melhores valores de imputação para os dados em falta com base na redução da perda de treinamento (ou seja, XGBoost). Alguns outros têm a opção de simplesmente ignorá-los (ou seja, LightGBM – use_missing=false). No entanto, outros algoritmos entram em pânico e lançam um erro reclamando dos valores faltantes (ou seja, Scikit learn – LinearRegression). Nesse caso, você precisará lidar com os dados ausentes e limpá-los antes de alimentá-los com o algoritmo.
Vejamos algumas outras formas de imputar os valores ausentes antes do treinamento:
Note: Todos os exemplos abaixo usam o California Housing Dataset do Scikit-learn.
2- Imputação Usando Valores (Média/Mediana):
Isto funciona calculando a média/mediana dos valores não ausentes em uma coluna e depois substituindo os valores ausentes dentro de cada coluna separadamente e independentemente das outras. Só pode ser usado com dados numéricos.

Pros:
- Fácil e rápido.
- Trabalha bem com pequenos conjuntos de dados numéricos.
Cons:
- Não tem em conta as correlações entre as características. Funciona apenas no nível da coluna.
- Dará maus resultados em características categóricas codificadas (NÃO o utilize em características categóricas).
- Não é muito preciso.
- Não leva em conta a incerteza nas imputações.
>
3- Imputação Usando Valores (Mais Frequentes) ou (Zero/Constante):
Mais Frequente é outra estratégia estatística para imputar valores em falta e SIM!! Funciona com características categóricas (strings ou representações numéricas) substituindo os dados ausentes pelos valores mais frequentes dentro de cada coluna.
Pros:
- Trabalha bem com características categóricas.
Cons:
- Também não tem em conta as correlações entre características.
- Pode introduzir enviesamento nos dados.
Zero ou Imputação Constante – como o nome sugere – substitui os valores em falta por zero ou qualquer valor constante especificado

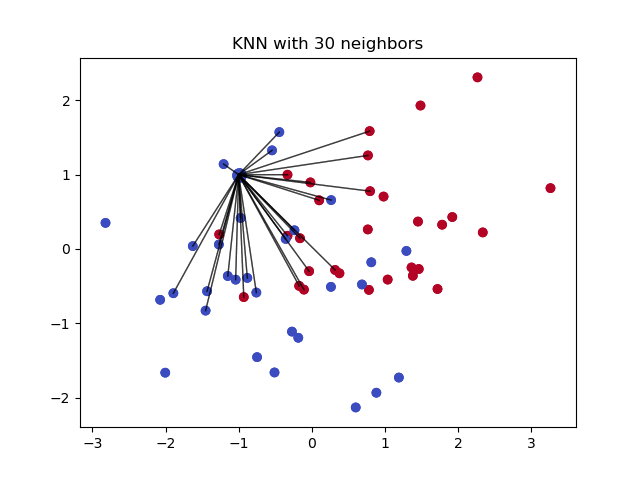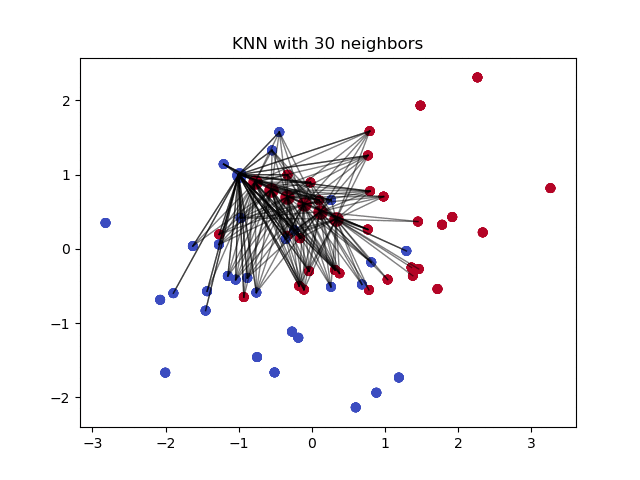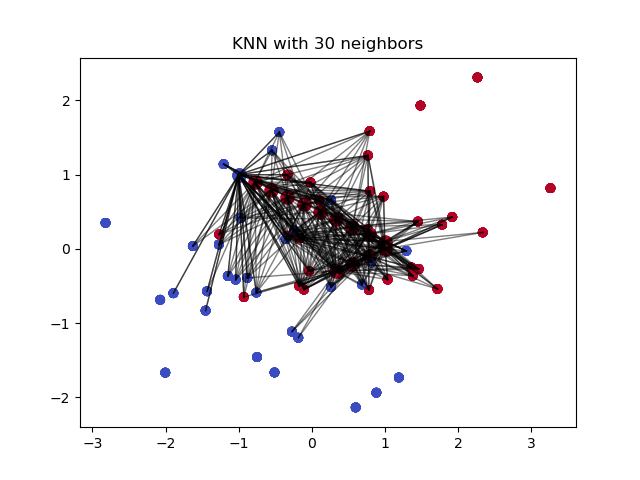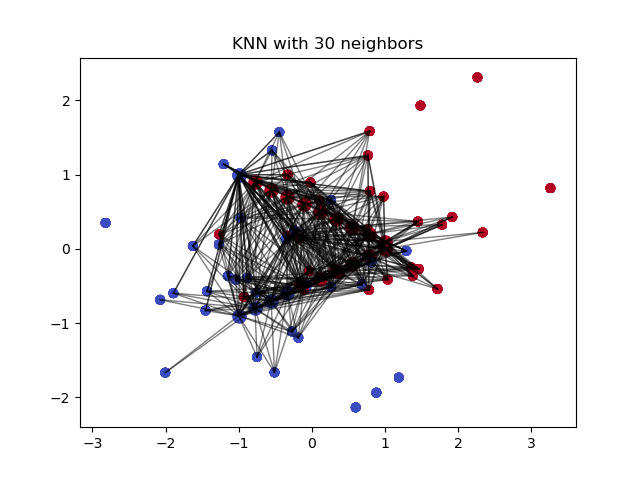
4- Imputação Usando k-NN:
O k vizinhos mais próximos é um algoritmo que é usado para classificação simples. O algoritmo usa ‘similaridade de características’ para prever os valores de quaisquer novos pontos de dados. Isto significa que ao novo ponto é atribuído um valor com base na sua semelhança com os pontos do conjunto de treino. Isto pode ser muito útil para fazer previsões sobre os valores em falta, encontrando os vizinhos mais próximos da observação com dados em falta e depois imputindo-os com base nos valores não omissos na vizinhança. Vamos ver alguns exemplos de código usando Impyute biblioteca que fornece uma maneira simples e fácil de usar KNN para imputação:
Como funciona?
Cria um imputo médio básico e depois usa a lista completa resultante para construir uma árvore KDT. Depois, usa o KDTree resultante para calcular os vizinhos mais próximos (NN). Depois de encontrar os k-NNs, ele toma a média ponderada deles.
Pros:
- Pode ser muito mais preciso do que a média, mediana ou métodos de imputação mais frequentes (Depende do conjunto de dados).
Cons:
- Custo computacional. O KNN funciona armazenando todo o conjunto de dados de treinamento na memória.
- K-NN é bastante sensível a aberrações nos dados (ao contrário do SVM)
5- Imputação Usando Imputação Multivariada por Equação Encadeada (MICE)
Este tipo de imputação funciona preenchendo os dados em falta várias vezes. Imputações múltiplas (MIs) são muito melhores que uma única imputação, pois mede a incerteza dos valores em falta de uma forma melhor. A abordagem de equações encadeadas também é muito flexível e pode lidar com diferentes variáveis de diferentes tipos de dados (ou seja, contínuos ou binários), bem como com complexidades como limites ou padrões de salto de questionário. Para mais informações sobre a mecânica do algoritmo, você pode consultar o Research Paper
>

6- Imputação usando Deep Learning (Datawig):
Este método funciona muito bem com características categóricas e não-numéricas. É uma biblioteca que aprende modelos de Machine Learning usando Redes Neurais Profundas para imputar valores faltantes em um dataframe. Também suporta tanto CPU quanto GPU para treinamento.
Pros:
- Bastante preciso em comparação com outros métodos.
- Tem algumas funções que podem lidar com dados categóricos (Codificador de Característica).
- Suporta CPUs e GPUs.
Cons:
- Atribuição de coluna única.
- Pode ser bastante lento com grandes conjuntos de dados.
- Tem de ser especificadas as colunas que contêm informação sobre a coluna de destino que será imputada.
Imputação de regressão estocástica:
É bastante semelhante à imputação de regressão que tenta prever os valores em falta através da regressão a partir de outras variáveis relacionadas no mesmo conjunto de dados mais algum valor residual aleatório.
Extrapolação e Interpolação:
Tenta estimar valores de outras observações dentro do intervalo de um conjunto discreto de pontos de dados conhecidos.
AtribuiçãoHot-Deck:
Trabalha escolhendo aleatoriamente o valor em falta de um conjunto de variáveis relacionadas e similares.
Em conclusão, não existe uma forma perfeita de compensar os valores em falta num conjunto de dados. Cada estratégia pode ter um melhor desempenho para certos conjuntos de dados e tipos de dados ausentes, mas pode ter um desempenho muito pior em outros tipos de conjuntos de dados. Há algumas regras definidas para decidir qual estratégia usar para determinados tipos de valores em falta, mas além disso, você deve experimentar e verificar qual modelo funciona melhor para o seu conjunto de dados.