Neste blog, discutiremos os conceitos básicos da Regressão Logística e que tipo de problemas pode nos ajudar a resolver.

>
Regressão logística é um algoritmo de classificação usado para atribuir observações a um conjunto discreto de classes. Alguns dos exemplos de problemas de classificação são Email spam ou não spam, Transações online Fraude ou não Fraude, Tumor Maligno ou Benigno. A regressão logística transforma sua saída usando a função sigmóide logística para retornar um valor de probabilidade.
Quais são os tipos de regressão logística
- Binário (ex. Tumor Maligno ou Benigno)
- Falhas nas funções multi-linearesClass (ex. Gatos, cães ou ovelhas)
Regressão Lógica
Regressão Lógica é um algoritmo de Machine Learning que é usado para os problemas de classificação, é um algoritmo de análise preditiva e baseado no conceito de probabilidade.

Podemos chamar um modelo de Regressão Logística de Regressão Linear mas a Regressão Logística utiliza uma função de custo mais complexa, esta função de custo pode ser definida como a ‘função Sigmoid’ ou também conhecida como a ‘função logística’ em vez de uma função linear.
A hipótese de regressão logística tende a limitar a função de custo entre 0 e 1. Portanto, funções lineares não a representam, pois pode ter um valor maior que 1 ou menor que 0, o que não é possível de acordo com a hipótese de regressão logística.
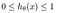
>
Qual é a função Sigmoid?
Para mapear os valores previstos para as probabilidades, usamos a função Sigmoid. A função mapeia qualquer valor real em outro valor entre 0 e 1. Na aprendizagem da máquina, usamos sigmoid para mapear as previsões para as probabilidades.


Representação da Tipotese
>
Quando usamos a regressão linear usamos uma fórmula da hipótese i.e.
hΘ(x) = β₀ + β₁X
Para a regressão logística vamos modificá-la um pouco i.e.
σ(Z) = σ(β₀ + β₁X)
Espera-se que a nossa hipótese dê valores entre 0 e 1.
Z = β₀ + β₁X
hΘ(x) = sigmoid(Z)
i.e. hΘ(x) = 1/(1 + e^-(β₀ + β₁X)

O limite de decisão
Esperamos que nosso classificador nos dê um conjunto de outputs ou classes baseadas em probabilidade quando passamos as entradas através de uma função de previsão e retornamos uma pontuação de probabilidade entre 0 e 1.
Por exemplo, temos 2 classes, vamos tomá-las como gatos e cães(1 – cão , 0 – gatos). Basicamente decidimos com um valor limite acima do qual classificamos os valores na Classe 1 e do valor vai abaixo do limite depois classificamo-lo na Classe 2.
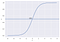
>
Como mostrado no gráfico acima escolhemos o valor limite como 0,5, se a função de predição retornasse um valor de 0,7 então classificaríamos esta observação como Classe 1(DOG). Se a nossa previsão retornasse um valor de 0,2 então classificaríamos a observação como Classe 2(CAT).
Cost Function
Aprendemos sobre a função custo J(θ) na regressão Linear, a função custo representa um objetivo de otimização, ou seja, criamos uma função custo e a minimizamos para que possamos desenvolver um modelo preciso com o mínimo de erro.
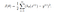
>
Se tentarmos usar a função de custo da regressão linear em ‘Regressão logística’, então ela não teria utilidade, pois acabaria sendo uma função não convexa com muitos mínimos locais, em que seria muito difícil minimizar o valor do custo e encontrar o mínimo global.

>
Para a regressão logística, a função Custo é definida como:
-log(hθ(x)) if y = 1
-log(1-hθ(x)) if y = 0

>
>
>