Příkaz egrep patří do rodiny příkazu grep, který se v Linuxu používá pro vyhledávání vzorů. Pokud jste použili příkaz grep, funguje egrep stejně jako grep -E (grep Extended regex‘). Egrep prohledá určitý soubor od řádku k řádku a vypíše řádek (řádky), které obsahují hledaný řetězec/regulární výraz. V tomto článku si vysvětlíme 15 užitečných příkladů příkazů egrep, které pomohou začátečníkům, ale i odborníkům provádět smysluplné vyhledávání v LinuxuTyto příklady jsme provedli na systému Debian 10 Buster, ale lze je snadno zopakovat na většině linuxových distribucí.
- Příklad 1: Vyhledání konkrétního řetězce v souboru
- Příklad 2: Hledání určitého řetězce ve více souborech
- Příklad 3: Rekurzivní hledání řetězce v celém adresáři
- Příklad 4: Provedení vyhledávání bez ohledu na velikost písmen
- Příklad 5: Vyhledávání řetězce jako celého slova a ne jako podřetězce
- Příklad 6: Vypsání pouze názvů souborů, které obsahují řetězec
- Příklad 7: Výpis pouze hledaného řetězce ze souboru
- Příklad 8: Zobrazení n počtu řádků před,za nebo kolem hledaného řetězce
- Příklad 9: Shoda regulárních výrazů v souborech
- Příklad 10: Zvýraznění hledaného řetězce
- Příklad 11: Provedení inverzního vyhledávání v souboru
- Příklad 12: Provedení inverzního vyhledávání na základě více kritérií/vzorů hledání
- Příklad 13: Výpis počtu řádků, které odpovídají hledanému řetězci
- Příklad 14: Zobrazení čísla řádku, na kterém je hledaný řetězec
- Příklad 15: Zobrazení pozice v souboru, kde hledaný řetězec odpovídá
Příklad 1: Vyhledání konkrétního řetězce v souboru
Jedná se o nejběžnější použití příkazu egrep. Postupujete tak, že zadáte řetězec, který chcete vyhledat, a název souboru, ve kterém chcete tento řetězec vyhledat. Výsledkem je pak zobrazení celého řádku obsahujícího hledaný řetězec.
Syntaxe:
Příklad:
V tomto příkladu jsem hledal slovo „debian“ v zadaném textovém souboru. Můžete vidět, jak se ve výsledcích zobrazí celý řádek, který obsahuje slovo „debian“:
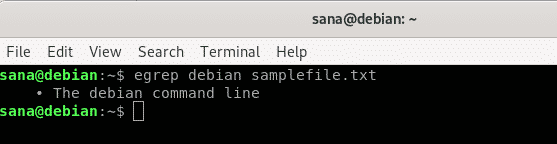
Příklad 2: Hledání určitého řetězce ve více souborech
Příkazem egrep můžete hledat řetězec mezi více soubory nacházejícími se ve stejném adresáři. Jen musíte být trochu konkrétnější při zadávání „vzoru“ pro prohledávané soubory. To bude jasnější na příkladu, který uvedeme.
Syntaxe:
Příklad:
Zde budeme hledat slovo „debian“ ve všech .txt souborech zadáním vzoru názvu souboru takto:

Příkaz vypsal všechny řádky spolu s názvy souborů, které obsahují slovo „debian“, ze všech souborů .txt v aktuálním adresáři.
Příklad 3: Rekurzivní hledání řetězce v celém adresáři
Pokud chcete hledat řetězec ve všech souborech z adresáře a jeho podadresářů, můžete tak učinit pomocí příznaku -r v příkazu egrep.
Syntaxe:
Příklad:
V tomto příkladu hledám slovo „sample“ v souborech celého adresáře current(Downloads).

Výsledek obsahuje všechny řádky spolu s názvy souborů, které obsahují slovo „sample“ ze všech souborů v adresáři Downloads a jeho podadresářích.
Příklad 4: Provedení vyhledávání bez ohledu na velikost písmen
Pomocí příznaku -i můžete pomocí příkazu egrep vypsat výsledky na základě vyhledávacího řetězce, aniž byste se museli starat o jeho velikost.
Syntaxe:
Příklad:
Tady hledám slovo „debian“ a chci, aby se ve výsledcích zobrazily všechny řádky ze souboru, které obsahují slovo „debian“ nebo „Debian, bez ohledu na jeho velikost.
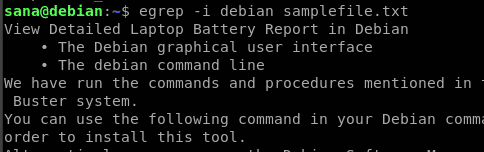
Vidíte, jak mi příznak -i pomohl při získání všech řádků, které obsahují hledaný řetězec, prostřednictvím vyhledávání „bez ohledu na velikost písmen“.
Příklad 5: Vyhledávání řetězce jako celého slova a ne jako podřetězce
Když normálně vyhledáváte řetězec pomocí egrepu, vypíše všechna slova, která obsahují řetězec jako podřetězec. Například vyhledání řetězce „on“ vypíše všechna slova obsahující řetězec „on“ jako “ on“, „pouze“, „monitor“, „klon“ atd. Pokud chcete, aby se ve výsledcích zobrazilo pouze slovo „on“ jako celé slovo, a ne jako podřetězec, můžete u příkazu egrep použít příznak -w.
Syntaxe:
Příklad:
Tady hledám řetězec „on“ v ukázkovém souboru:
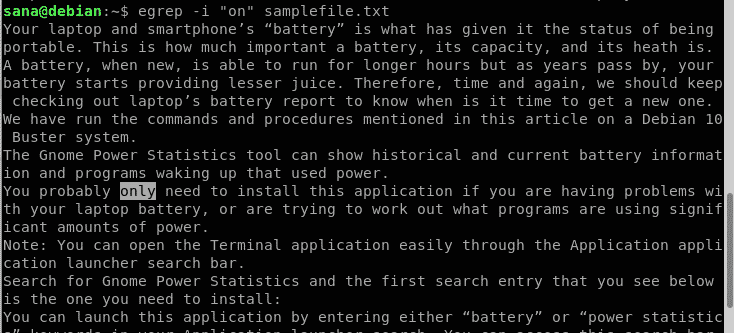
Ve výše uvedeném výstupu vidíte, že obsahuje i slovo „pouze“. To však není to, co chci, protože hledám výhradně slovo „on“. Místo toho tedy použiji tento příkaz:
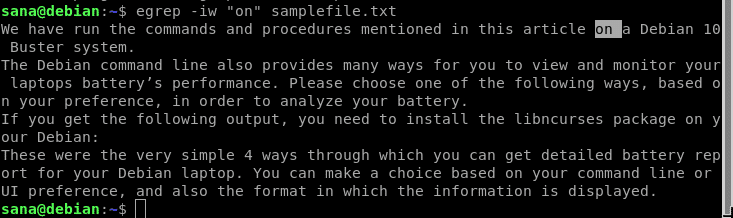
Nyní budou výsledky mého hledání obsahovat pouze řádky, které obsahují slovo „on“ jako celé slovo.
Příklad 6: Vypsání pouze názvů souborů, které obsahují řetězec
Někdy chceme načíst pouze názvy souborů, které obsahují určitý řetězec, a ne vypsat řádky, které ho obsahují. To lze provést pomocí příznaku -l (malé písmeno L) v příkazu egrep.
Syntaxe:
Příklad:
Tady hledám řetězec „sample“ ve všech souborech .txt v aktuálním adresáři:

Výsledek hledání vypíše pouze názvy souborů, které obsahují zadaný řetězec.
Příklad 7: Výpis pouze hledaného řetězce ze souboru
Místo vypisování celého řádku, který obsahuje hledaný řetězec, můžete pomocí příkazu egrep vypsat samotný řetězec. Řetězec se vypíše tolikrát, kolikrát se v zadaném souboru vyskytuje.
Syntaxe:
Příklad:
V tomto příkladu hledám v souboru slovo „This“.

Poznámka: Toto použití příkazu se hodí, když hledáte řetězec na základě vzoru regulárního výrazu. Regulární výrazy si podrobně vysvětlíme v některém z příštích příkladů.
Příklad 8: Zobrazení n počtu řádků před,za nebo kolem hledaného řetězce
Někdy je velmi důležité znát kontext v souboru, kde je konkrétní řetězec použit. Egrep se hodí v tom smyslu, že pomocí něj lze zobrazit řádek obsahující hledaný řetězec a také určitý počet řádků před, za a kolem něj.
Toto je ukázkový textový soubor, který budu používat pro vysvětlení následujících příkladů:

N počet řádků Za hledaným řetězcem:
Při použití příznaku A následujícím způsobem se zobrazí řádek obsahující hledaný řetězec a N počet řádků za ním:
Příklad:

N počet řádků Před hledaným řetězcem:
Při použití příznaku B následujícím způsobem se zobrazí řádek obsahující hledaný řetězec a N počet řádků před ním:
Příklad:

N počet řádků Před hledaným řetězcem:
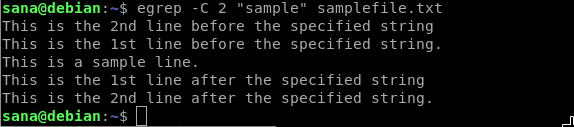
Při použití příznaku C následujícím způsobem se zobrazí řádek obsahující hledaný řetězec a N počet řádků před a za ním:
Příklad:
Příklad 9: Shoda regulárních výrazů v souborech
Příkaz egrep se stává výkonnějším, když v souboru hledáte regulární výrazy místo pevných hledaných řetězců.
Syntaxe:
Vysvětlíme si, jak můžete použít regulární výrazy při vyhledávání pomocí příkazu egrep:
| Operátor opakování | Použití |
| ? | Předchozí položka před ? je nepovinný a porovnává se maximálně jednou |
| * | Předcházející položka před * se porovnává nulakrát nebo vícekrát |
| + | Předchozí položka před + bude přiřazena jedenkrát nebo vícekrát |
| {n} | Předchozí položka je přesně přiřazena n-krát. |
| {n,} | Předchozí položka je přiřazena n nebo vícekrát |
| {,m} | Předchozí položka je přiřazena maximálně mkrát |
| {n,m} | Předchozí položka je přiřazena nejméně n-krát, ale nejvýše m-krát |
Příklad:
V následujícím příkladu se porovnávají řádky obsahující následující výraz:
začínající na „Gnome“ a končící na “ programy“

Příklad 10: Zvýraznění hledaného řetězce
Pokud nastavíte proměnnou prostředí GREP_OPTIONS, jak je uvedeno níže, dostanete výstup se zvýrazněným hledaným řetězcem/vzorem ve výsledcích:
Poté můžete vyhledávat řetězec libovolným způsobem, který jsme popsali v příkladech tohoto článku.
Příklad 11: Provedení inverzního vyhledávání v souboru
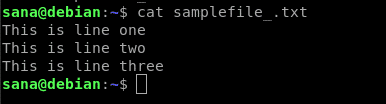
Inverzním vyhledáváním rozumíme, že příkaz egrep vypíše vše v souboru kromě řádků, které obsahují hledaný řetězec. K vysvětlení inverzního vyhledávání pomocí příkazu egrep použijeme následující ukázkový soubor. Obsah souboru jsme vypsali pomocí příkazu cat:
Syntaxe:
Příklad:
Z uvedeného ukázkového souboru chceme ve výstupu vynechat řádek obsahující slovo „dva“, proto použijeme následující příkaz:
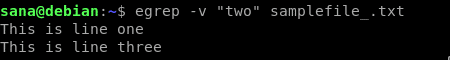
Vidíte, jak výstup obsahuje vše z ukázkového souboru kromě druhého řádku, který obsahoval hledaný řetězec „dva“.
Příklad 12: Provedení inverzního vyhledávání na základě více kritérií/vzorů hledání
Příkazem -v můžete také přimět příkaz egrep, aby provedl inverzní vyhledávání na základě více než jednoho hledaného řetězce/vzoru.
Pro vysvětlení tohoto scénáře použijeme stejný ukázkový soubor, který jsme uvedli v příkladu 11.
Syntaxe:
…. filename
Příklad:
Z uvedeného vzorového souboru chceme ve výstupu vynechat řádek(y) obsahující slova „one“ a „two“, proto použijeme následující příkaz:
Příkazem -e jsme zadali dvě slova, která chceme vynechat, proto bude výstup vypadat takto:

Příklad 13: Výpis počtu řádků, které odpovídají hledanému řetězci
Místo vypisování hledaného řetězce ze souboru nebo řádků, které ho obsahují, můžete pomocí příkazu egrep spočítat a vypsat počet řádků, které odpovídají hledanému řetězci. Tento počet lze získat pomocí příznaku -c u příkazu egrep.
Syntaxe:
Příklad:
V tomto příkladu použijeme příznak -c pro spočítání počtu řádků, které obsahují slovo „Tento“ v našem ukázkovém souboru:

Můžete zde také použít funkci inverzního vyhledávání a spočítat a vypsat počet řádků, které neobsahují hledaný řetězec:
![]()
Příklad 14: Zobrazení čísla řádku, na kterém je hledaný řetězec
Pomocí příznaku -n můžete přimět příkaz egrep, aby vypsal hledaný řádek spolu s číslem řádku, který obsahuje hledaný řetězec.
Syntaxe:
Příklad:

Můžete vidět, jak se čísla řádků zobrazují proti výsledkům hledání.
Příklad 15: Zobrazení pozice v souboru, kde hledaný řetězec odpovídá
Pokud chcete znát pozici v souboru, kde hledaný řetězec existuje, můžete použít příznak -b u příkazu egrep.
Příklad:

Výsledek hledání vypíše offset v bytech souboru, kde hledané slovo existuje. to bylo podrobné použití příkazu egrep. Pomocí kombinace příznaků vysvětlených v tomto článku můžete provádět smysluplnější a složitější vyhledávání v souborech.