egrepコマンドは、Linuxでパターン検索に使われるgrepコマンドの系列に属するコマンドです。 grepコマンドを使ったことがあれば、egrepはgrep -E (grep Extended regex’)と同じように動作します。 Egrepは、特定のファイルを一行ずつスキャンして、検索文字列/正規表現を含む行を表示します。 この記事では、Linux で意味のある検索を行うために、初心者や専門家にさえ役立つ egrep コマンドの 15 の有用な例を説明します。これらの例は Debian 10 Buster システムで実行しましたが、ほとんどの Linux ディストリビューターで容易に再現できます。 何をするかというと、検索したい文字列と、その文字列を検索するファイル名を指定するのです。
Example:
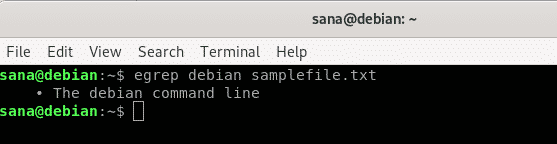
この例では、指定したテキストファイルで “debian” を検索しています。 その結果、「debian」という単語を含む行全体が表示されます。
- 例 2: 複数のファイルから特定の文字列を検索する
- 例 3: ディレクトリ全体の文字列を再帰的に検索する
- 例 4: 大文字小文字を区別しない検索を行う
- 例 5: サブストリングとしてではなく、完全な単語として文字列を検索する
- 例 6: 文字列を含むファイル名のみを表示する
- 例 7: ファイルから検索文字列のみを表示する
- 例 8: 検索文字列の前後または周辺の n 行を表示する
- 例9:ファイル内の正規表現にマッチする
- 例 10: 検索文字列をハイライトする
- 例 11: ファイルで反転検索を行う
- 例 12: 複数の条件/検索パターンに基づく反転検索の実行
- 例 13: 検索文字列に一致する行数を表示する
- 例 14: 文字列にマッチした行番号を表示する
- 例15:検索文字列が一致するファイル内の位置を表示する
例 2: 複数のファイルから特定の文字列を検索する
egrepコマンドでは、同じディレクトリにある複数のファイルから文字列を検索することができます。 ただし、検索するファイルの「パターン」をもう少し具体的に指定する必要があります。
構文:
例:
ここで、すべての .debian という単語を検索してみます。
コマンドは、現在のディレクトリ内のすべての .txt ファイルから “debian” という単語を含むファイル名とともにすべてのラインを出力しました。
例 3: ディレクトリ全体の文字列を再帰的に検索する
あるディレクトリとそのサブディレクトリのすべてのファイルから文字列を検索したい場合、egrepコマンドで-rフラグを使用することで行えます。
構文:
例:
この例では、現在の (Downloads) ディレクトリ全体のファイルから “sample” という単語を検索しています。

結果は、Downloads ディレクトリとそのサブディレクトリのすべてのファイルから “sample” を含むすべての行と、ファイル名を含んでいます。
例 4: 大文字小文字を区別しない検索を行う
-iフラグを使用すると、egrepコマンドを使用して、大文字小文字を気にせずに検索文字列に基づく結果を表示することができます。
構文:
例:
ここで、私は “debian” という言葉を検索していて、結果は “debian” または “Debian” を含むファイルからのすべてのラインを、そのケースとは関係なく表示したいのですが。
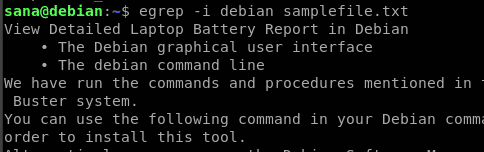
-i フラグは、大文字小文字を区別しない検索で、検索文字を含むすべての行を取得するのに役立つことがおわかりいただけると思います。
例 5: サブストリングとしてではなく、完全な単語として文字列を検索する
egrep によって通常文字列を検索すると、サブストリングとして文字列を含むすべての単語が出力されます。 例えば、「on」という文字列を探すと、「on」、「only」、「monitor」、「clone」など、「on」という文字列を含むすべての単語が表示されます。 もし、”on “という単語だけを表示させたい場合は、-wフラグをegrepと一緒に使用することができます。
構文:
例:
ここではサンプルファイルから文字列 “on” を検索します:
サンプルファイルから検索する場合、”on” という文字列を検索します。txt
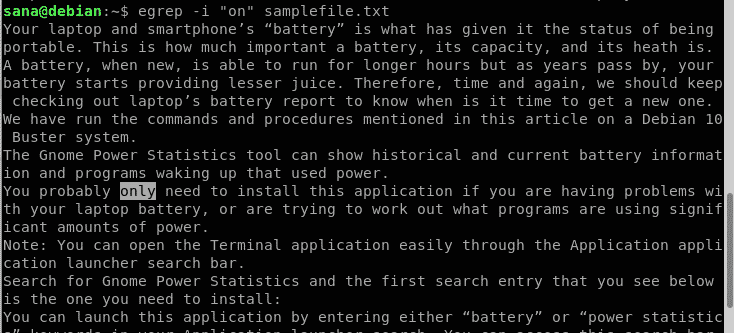
上の出力で、「only」という単語も含まれていることがわかります。 しかし、私は “on “という単語だけを探しているので、これは私が望むものではありません。
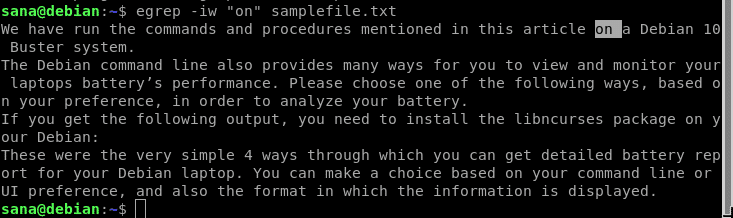
これで、検索結果には単語全体として “on” を含む行のみが含まれるようになりました。
例 6: 文字列を含むファイル名のみを表示する
特定の文字列を含む行を表示するのではなく、それを含むファイル名のみを取得したいことがあります。
構文:
例:
ここで、現在のディレクトリのすべての .txt ファイルで文字列 “sample” を探しています:

検索結果は、指定した文字列を含むファイルの名前のみを表示します。
例 7: ファイルから検索文字列のみを表示する
検索文字列を含む行全体を表示する代わりに、egrep コマンドを使って文字列自体を印刷することができます。 文字列は、指定されたファイルに現れる回数だけ印刷されます。
Syntax:
例:
この例では、ファイルの中で “This” という単語について検索しています。

注意:このコマンドの使用法は、正規表現パターンに基づいて文字列を検索するときに便利です。
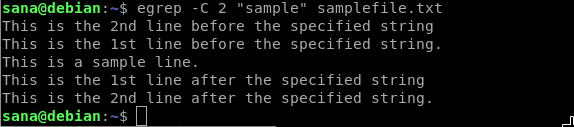
例 8: 検索文字列の前後または周辺の n 行を表示する
特定の文字列が使用されているファイル内のコンテキストを知ることが非常に重要な場合があります。 egrep は、検索文字列を含む行と、その前後や周囲の特定の行数を表示するために使用できるという意味で便利である。
これは、これからの例を説明するために使用するサンプルテキストファイルです:

N 行目 検索文字列の後。
以下のようにAフラグを使用すると、検索文字列を含む行とその次のN行が表示されます:
例:

検索文字列の前のN行数:
以下のようにBフラグを使用すると、検索文字列を含む行とその前のN行が表示されるようになります。
例:

検索文字列の前のN行数:
以下のようにCフラグを使用すると、検索文字列を含む行とその前後のN行が表示されます。
例:
例9:ファイル内の正規表現にマッチする
egrepコマンドは、ファイル内の固体検索文字列ではなく、正規表現を検索するとより強力になる。
構文:
egrep検索で正規表現を使用する方法を説明します:
| Repetition operator | Use |
| ? | 前項目の? はオプションで、最大1回マッチ |
| * | *の前の項目は0回以上マッチ |
| + | +の前の項目が1回以上マッチする |
| {n} | 前の項目がちょうどn回マッチする。 |
| {n,} | 前項目がn回以上マッチ |
| {,m} | 前項目が最大m回 |
| {n,m} | 先行する項目がn回以上m回以下マッチする |
例:
次の例では、次の式を含む行がマッチします。
“Gnome” で始まり ” programs” で終わる

例 10: 検索文字列をハイライトする
環境変数 GREP_OPTIONS を以下のように設定すると、検索文字列/パターンをハイライトして出力されます。
その後、この記事の例で説明した任意の方法で、文字列を検索することができます。
例 11: ファイルで反転検索を行う
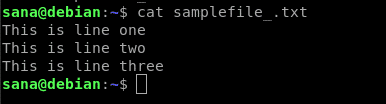
反転検索とは、egrep コマンドが検索文字列を含む行を除いて、ファイル内のすべてを表示することを意味します。 以下のサンプルファイルを用いて、egrepによる反転検索を説明します。 catコマンドでファイルの内容を出力しました:
構文:
例:。
先ほどのサンプルファイルから、「two」という単語を含む行を省略して出力したいので、次のコマンドを使用します:
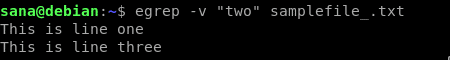
出力には、検索文字列 “two” を含む 2 行目以外のサンプル ファイルからのすべてが含まれていることがわかります。
例 12: 複数の条件/検索パターンに基づく反転検索の実行
また、-v フラッグを使用して、egrep コマンドに複数の検索文字列/パターンに基づく反転検索を実行させることも可能です。
このシナリオを説明するために、例 11 で述べたのと同じサンプルファイルを使用します。
構文:
……….
例 11 で述べたサンプルファイルを使用し、このシナリオを説明するために、例 11 で述べたのと同じサンプルファイルを使用します。 filename
例:
先ほどのサンプルファイルから、「one」「two」という単語を含む行を省略して出力したいので、次のコマンドを使ってみます:
eフラグで省略する単語を2つ指定したので、出力は次のようになります:

例 13: 検索文字列に一致する行数を表示する
ファイルから検索した文字列またはそれを含む行を表示する代わりに、egrepコマンドを使ってその文字列に一致する行数を数え表示することができます。 このカウントは、egrepコマンドの-cフラグを使用して取得できます。
構文:
例:
この例では、-c フラグを使ってサンプルファイル中の “This” を含む行数を数えます。

ここで反転検索機能を使って、検索文字列を含まない行数をカウントして表示することも可能です。
![]()
例 14: 文字列にマッチした行番号を表示する
-n フラッグを使うと、egrep コマンドにマッチした行と検索文字列を含む行番号を一緒に印刷するようにすることができます。
構文:
例:

サーチ結果に対して行番号がどう表示されるかは、見ていただければわかると思いますが、行番号が表示されるのは、検索した行が、その行に一致した場合です。
例15:検索文字列が一致するファイル内の位置を表示する
検索文字列が存在するファイル内の位置を知りたい場合は、egrepコマンドで-bフラグを使用することができます。
例:

検索結果には検索ワードがあるファイルのバイトオフセットを出力します今回はegrepコマンドの詳しい使用方法についてでした。 今回説明したフラグを組み合わせて使うことで、より意味のある複雑な検索をファイルに対して行うことができます
。