“74% af virksomhederne siger, at de ønsker at være “datadrevne”, men kun 29% siger, at de er gode til at forbinde analyser med handling.” – Forrester
Generering, behandling og deling af statistikker og data – gør disse handlinger dig til en “datadrevet” virksomhed?
Sikkert, men hvis de data og statistikker, der ligger til grund for dine beslutninger, er unøjagtige eller helt forkerte, kan de deraf følgende negative resultater skabe forvirring og dårlige resultater.
Credible data eliminerer den skræmmende udsigt til at stole på lunefulde gæt og “mavefornemmelser”. Det kombinerer menneskelig erfaring og intuition med konkrete tal og analyser for at skabe beslutninger, der kan flytte nålen.
Men intuitive dashboards, diagrammer, statistikker og grafer dækker ofte over en falsk virkelighed:
Misvisende statistikker og data.
Med teknologien, der udvikler sig hurtigt, og brugerne tilpasser sig i samme tempo, er virksomhederne blevet afhængige af data og statistikker for at kunne navigere i et konkurrencedygtigt forretningsmiljø.
Men det er let at blive forblændet af tals absoluthed, især når de giver troværdighed til gunstige hypoteser eller pointer.
Det er en trussel mod datadrevet beslutningstagning, hvis man ikke kan genkende falske statistikker og data.
Det opmuntrer dig til at trykke på de ordsprogligt forkerte knapper med fuld tillid, og det er der, faren ligger.
I dette indlæg lærer du, hvordan du kan opdage vildledende statistikker og data. Vi ser på de almindelige måder, de vildleder på, og hvordan du kan afgøre, hvornår data kan bære vægten af kritiske beslutninger.
- Hvad er en vildledende statistik?
- Selektiv bias for at skabe falske statistikker
- Underladt stikprøvestørrelse resulterer i falsk præcision
- Fejlfulde korrelationer og årsagssammenhænge til at skabe falsk statistik
- Misvisende grafer og visualiseringer
- Konklusion: Beskyttelse mod vildledende data og statistikker
- Om forfatteren
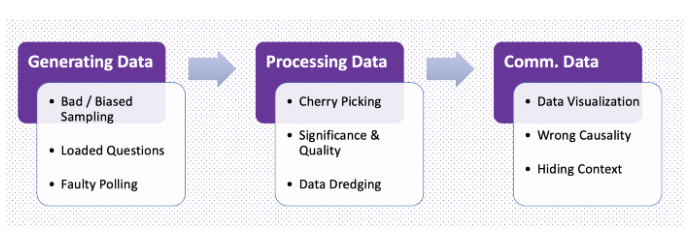
Hvad er en vildledende statistik?
Kilde
Kilde
Vildledende statistik skabes, når der er en fejl – bevidst eller ubevidst – i et af de 3 centrale aspekter af forskning:
-
Indsamling:
-
Organisering: Der anvendes små stikprøver, der projicerer store tal, men som har ringe statistisk signifikans.
-
Organisering: Udelade resultater, der modsiger den pointe, som forskeren forsøger at bevise.
-
Præsentation: Manipulation af visuelle/numeriske data for at påvirke opfattelsen.
Dårlige statistikker sniger sig ind i nyheder, reklamekampagner og endda i videnskabelig litteratur. En chokerende 33,7 % af videnskabsfolk – superlativerne for at være dataneutrale – har indrømmet, at de har misbrugt statistik til at understøtte forskning. Ja, selv nogle af samfundets betroede portvagter af information er skyldige.
For at hjælpe dig med at træffe kritiske beslutninger baseret på de rigtige data, har vi listet de almindelige måder, hvorpå statistikker vildleder og misinformerer.
Selektiv bias for at skabe falske statistikker
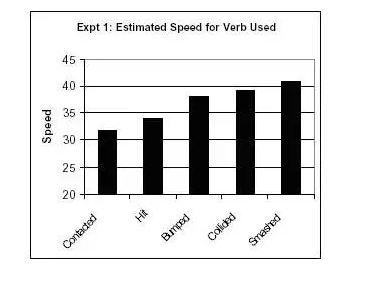
En undersøgelse af Elizabeth Loftus testede sprogets indflydelse på øjenvidneudsagn. Forsøgspersoner fik vist en film, der skildrede flere bilulykker. Efter at have set dem, blev de spurgt: “Hvor hurtigt kørte bilerne ca., da de kørte ind i hinanden?”
Andre forsøgspersoner blev derefter stillet det samme spørgsmål, dog med ordet “smadrede” erstattet af suggestive verber som:
-
Kontakterede
-
Hit
-
Bumped
-
Collided
-
Collided
Resultaterne?
Jo stærkere det anvendte “belastede” verbum var, desto højere var vidnernes hastighedsvurdering.
Kilde
Derudover viste undersøgelsen, at når der blev brugt et stærkere verbum, var forsøgspersoner mere tilbøjelige til at rapportere glasskår ved ulykken, selv om der ikke blev vist glasskår i videoen.
Anvendelse af sprog til at påvirke undersøgelsessvar og resultater er blot et eksempel på selektionsbias. I 2007 tvang Advertising Standards Authority (ASA) Colgate til at opgive deres påstand om, at “over 80 % af tandlægerne anbefaler at bruge Colgate”, fordi påstanden på vildledende vis antydede, at “80 % af tandlægerne anbefaler Colgate-tandpasta frem for alle andre mærker”.
Det egentlige spørgsmål i undersøgelsen lød: “Hvis de kunne vælge mellem at børste alene og bruge en tandpasta – som Colgate – hvilken ville de så anbefale?”
Ved at udvælge deres svar på undersøgelsen gav Colgate det indtryk, at tandlægerne anbefalede dem frem for konkurrenternes mærker; den egentlige anbefaling var, at det er bedre at bruge en hvilken som helst tandpasta end at børste alene.
Selektiv skævhed opstår ofte, når udvalgte stikprøver eller data er ufuldstændige eller cherrypicked for at påvirke opfattelsen af – og endda skævvride – statistik og data.
Underladt stikprøvestørrelse resulterer i falsk præcision

(kilde)
90 personer, der svarer “ja” ud af 100 personer ( 90 %), mod 900 personer, der svarer “ja” ud af 1000 personer (også 90 %); procenterne er ens, men forskellen i værdi og validitet af data er statistisk signifikant.
Mindre stikprøvestørrelser garanterer næsten alarmerende signifikante resultater. Pas altid på med ekstreme resultater, og accepter aldrig procenter for pålydende værdi. Med biokemiforsker Ana-maria Sundics ord:
“For at sikre, at stikprøven er repræsentativ for en population, skal stikprøveudtagningen være tilfældig, dvs. at alle forsøgspersoner skal have lige stor sandsynlighed for at indgå i undersøgelsen. Det skal bemærkes, at der også kan opstå stikprøveforvridning, hvis stikprøven er for lille til at repræsentere målpopulationen.”
Fejlfulde korrelationer og årsagssammenhænge til at skabe falsk statistik
“Korrelation betyder ikke årsagssammenhæng”.
Denne sætning har du uden tvivl hørt før, men den er af gode grunde sand.
Når to variabler korrelerer, gælder som regel følgende:
-
Y forårsager X.
-
X forårsager Y.
-
En tredje faktor udløser X + Y.
-
Korrelationen skyldes tilfældigheder.
Korrelation og årsagssammenhæng berettiger til masser af mistanke, fordi forskere – og forbrugere af den nævnte forskning – falder for:
-Talfetichisme
-Korrelationsjagt
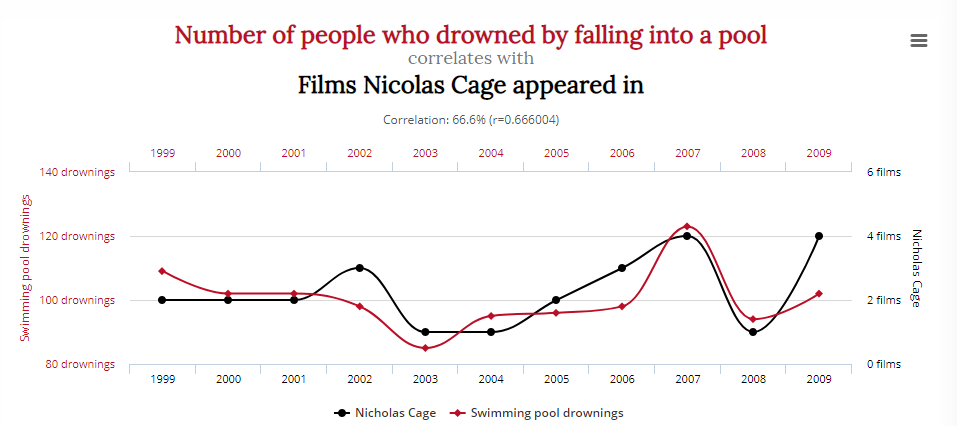
Tyler Vegihn har samlet nogle sjove misvisende statistikeksempler for at bevise netop dette:
Denne graf viser en overbevisende korrelation mellem antallet af mennesker, der drukner ved at falde i en pool, og antallet af film, som Nicolas Cage har medvirket i:
En anden viser en sammenhæng mellem antallet af mennesker, der døde ved at blive viklet ind i sengetøj, og forbruget af ost:
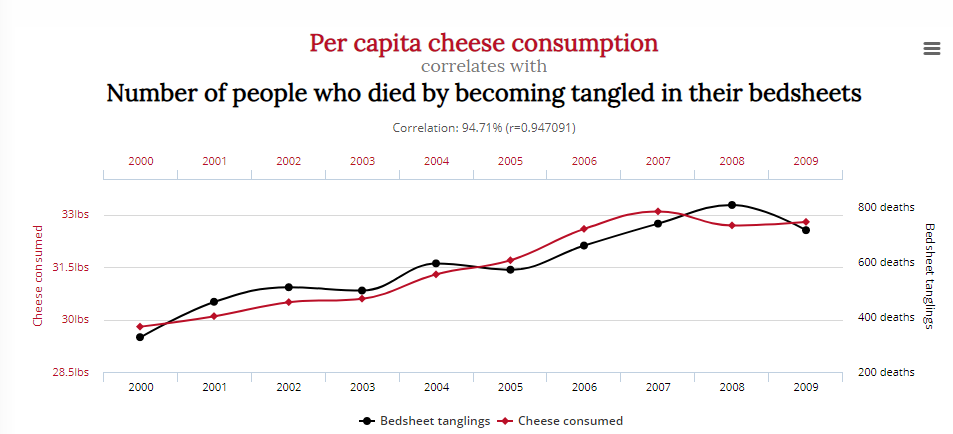
Betyder det, at en reduktion af forbruget af ost og Nicolas Cages skuespillerroller vil redde liv? Sandsynligvis ikke.
Da forskere er presset til at finde nyttige data eller bevise en hypotese, er fristelsen til for tidligt at erklære et “aha”- eller “eureka”-øjeblik stor.
Det er et problem for sunde analyser og statistikker; hvis du inddrager nok variabler, er du næsten garanteret at finde en sammenhæng, med hvad som helst.
Misvisende grafer og visualiseringer
Datavisualiseringer omdanner rå tal til visuelle repræsentationer af vigtige relationer, tendenser og mønstre. Selv om de er i stand til at bringe dine data til live, er de også et populært medie for vildledende statistikker og data.
I sin bog “Graphics, Lies, Misleading Visuals” afslører datajournalist Alberto Cairo eksempler på vildledende statistikker fra markedsføringsannoncer, politiske kampagner og nyhedsdækning.
Et populært eksempel fra nyhederne er Terri Schiavo-sagen, en ret til at dø retssag i USA.
Under sagen blev en graf som nedenstående anvendt af CNN til at skildre, hvordan forskellige politiske grupper mente om fjernelsen af Terris livsstøtte:
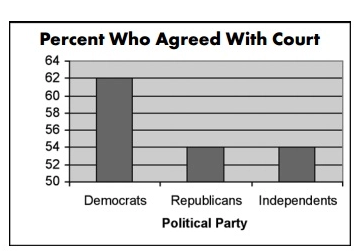
Kilde
Et blik på denne graf antyder, at sammenlignet med republikanere og uafhængige personer var tre gange så mange demokrater enige med retten
Et nærmere kig afslører dog en lille forskel på 14 % i stemmer.
Den afkortede graf og den manipulerede Y-akse (der starter ved 50 i stedet for 0) forvrænger dataene og får dig til at tro på en overdreven idé om en bestemt gruppe.
Undgå at blive vildledt, når du ser på grafer og visuals, ved at holde øje med:
-
Udeladelsen af basislinjen eller den afkortede akse på en graf.
-
Intervallerne og skalaerne. Kontroller for ujævne intervaller og mærkelige målinger (brug af tal i stedet for procenter osv.).
-
Den komplette kontekst og andre sammenlignende grafer for at se, hvordan lignende data er målt og repræsenteret.
Konklusion: Beskyttelse mod vildledende data og statistikker
Vildledende statistikker og data praler af storslåede forbedringer af konverteringsraten med “CTA tweaks” og “simple farveændringer”.
De skaber chokerende overskrifter, der tiltrækker sværme af trafik, men som i bedste fald giver mangelfuld indsigt.
Dårlige statistikker og data er farlige.
I stedet for at hjælpe dig med at navigere gennem omveje, huller og faldgruber, styrer de dig bevidst – eller ubevidst – lige ind i dem. Men du er klog nok til at opdage dem.
Næste gang du støder på overbevisende data, så kør efter disse enkle, men effektive spørgsmål:
Hvem laver forskningen?
Forskning er dyrt og tidskrævende. Undersøg, hvem der sponsorerer den, afvej deres fordomme om emnet, og hvordan de kan drage fordel af resultaterne. Er de en B2C-virksomhed med et produkt? En konsulenttjeneste? En uafhængig universitetsfinansieret undersøgelse?
Kan stikprøvestørrelsen og undersøgelsens længde tages alvorligt?
Inspektion af de understøttende eller tilslørede tal vil afsløre svag statistisk styrke.
Er data visuelt repræsenteret retfærdigt?
Er skalaer og intervaller jævnt fordelt og neutrale? Skubber en statistik til en bestemt idé eller dagsorden? Er der for mange målinger i dit dashboard?
Er forskningen repræsenteret ærligt og upartisk?
Gennemgå det anvendte sprog, den måde, spørgsmålet er formuleret på, og de personer, der er blevet adspurgt.
For at forhindre, at misvisende statistikker og data forurener dine dashboards, rapporter og analyser, skal du hilse på nye oplysninger med en nysgerrig og skeptisk holdning.
Om forfatteren
Hassan Uddeen er en britisk baseret freelance-skribent for B2B-, SaaS- og Fintech-virksomheder. Han elsker alt, hvad der har med content marketing at gøre. Når han kan løsrive sig fra tastaturet, kan han lide at hoppe rundt i sit hjemmegymnastikcenter (mens han spiller rollespil som Goku) og grave sig ned i en god James Patterson-roman.