« 74% des entreprises disent vouloir être « axées sur les données », mais seulement 29% disent qu’elles sont bonnes pour relier les analyses à l’action. » – Forrester
Générer, traiter et partager des statistiques et des données – ces actions font-elles de vous une entreprise » pilotée par les données » ?
Certes, mais si les données et les statistiques qui motivent vos décisions sont inexactes, ou complètement fausses, les résultats négatifs qui en découlent peuvent susciter la confusion et de mauvaises performances.
Les données crédibles éliminent la perspective effrayante de se fier à des suppositions fantaisistes et à des » intuitions « . Elles combinent l’expérience et l’intuition humaines avec des chiffres concrets et des analyses pour faire naître des décisions capables de faire bouger l’aiguille.
Mais les tableaux de bord, les diagrammes, les statistiques et les graphiques intuitifs masquent souvent une réalité fallacieuse :
Des statistiques et des données trompeuses.
Avec la technologie qui progresse rapidement et les utilisateurs qui s’adaptent à un rythme égal, les entreprises sont devenues dépendantes des données et des statistiques pour naviguer dans un environnement commercial compétitif.
Mais il est facile d’être aveuglé par le caractère absolu des chiffres, surtout lorsqu’ils donnent de la crédibilité à des hypothèses ou des points favorables.
Ne pas reconnaître les statistiques et les données fausses est une menace pour la prise de décision basée sur les données.
Cela vous encourage à appuyer sur les mauvais boutons proverbiaux en toute confiance, et c’est là que réside le danger.
Dans ce billet, vous apprendrez à repérer les statistiques et les données trompeuses. Nous examinerons les façons courantes dont elles induisent en erreur, et comment déterminer quand les données peuvent supporter le poids de décisions critiques.
- Qu’est-ce qu’une statistique trompeuse ?
- Biais sélectif pour créer de fausses statistiques
- Taille d’échantillon négligée entraînant une fausse précision
- Corrélations et causalités erronées pour créer de fausses statistiques
- Graphes et visuels trompeurs
- Conclusion : Se prémunir contre les données et les statistiques trompeuses
- À propos de l’auteur
Qu’est-ce qu’une statistique trompeuse ?
Source
Les statistiques trompeuses sont créées lorsqu’une faute – délibérée ou non – est présente dans l’un des 3 aspects clés de la recherche :
-
Collecte : Utiliser des échantillons de petite taille qui projettent de gros chiffres mais qui ont peu de signification statistique.
-
Organiser : Omettre les résultats qui contredisent le point que le chercheur essaie de prouver.
-
Présenter : Manipuler des données visuelles/numériques pour influencer la perception.
Les mauvaises statistiques se glissent dans les organes d’information, les campagnes publicitaires et même la littérature scientifique. Un choquant 33,7% des scientifiques – les superlatifs d’être neutres en matière de données – ont admis une mauvaise utilisation des statistiques pour soutenir la recherche. Oui, même certains des gardiens de l’information de confiance des sociétés sont coupables.
Pour vous aider à prendre des décisions critiques basées sur les bonnes données, nous avons listé les façons courantes dont les statistiques induisent en erreur et désinforment.
Biais sélectif pour créer de fausses statistiques
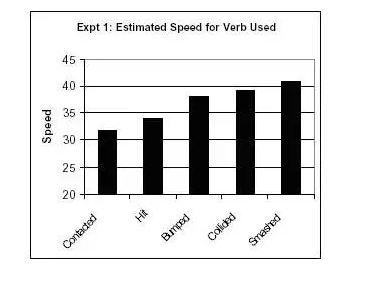
Une étude d’Elizabeth Loftus a testé l’influence du langage sur les témoignages oculaires. On a montré à des sujets un film décrivant de multiples accidents de voiture. Après le visionnage, on leur a demandé : » à peu près à quelle vitesse allaient les voitures lorsqu’elles se sont percutées ? »
On a ensuite posé la même question à d’autres sujets, mais en remplaçant le mot « fracassé » par des verbes suggestifs tels que :
-
Contacté
-
Chez
-
Bossé
-
Collé
Les résultats ?
Plus le verbe « chargé » utilisé était fort, plus l’estimation de la vitesse par les témoins était élevée.
Source
En outre, l’étude a révélé que lorsqu’on utilisait un verbe plus fort, les sujets étaient plus susceptibles de signaler la présence de verre brisé lors de l’accident, même si le verre brisé n’était pas montré dans la vidéo.
L’utilisation du langage pour influencer les réponses et les résultats d’une enquête n’est qu’un exemple de biais de sélection. En 2007, l’Advertising Standards Authority (ASA) a obligé Colgate à abandonner son affirmation selon laquelle « plus de 80% des dentistes recommandent l’utilisation de Colgate », car cette affirmation impliquait de manière trompeuse « 80% des dentistes recommandent le dentifrice Colgate de préférence à toutes les autres marques ».
La question réelle de l’enquête était « étant donné le choix entre le brossage seul et l’utilisation d’un dentifrice – comme Colgate – lequel recommanderaient-ils ? »
En reprenant la réponse de leur enquête, Colgate a donné l’impression que les dentistes les recommandaient plutôt que les marques concurrentes ; la recommandation réelle était que l’utilisation de n’importe quel dentifrice est supérieure au brossage seul.
Le biais sélectif se produit souvent lorsque des échantillons ou des données choisis sont incomplets ou cueillis à la cerise pour influencer la perception des statistiques et des données – et même les fausser.
Taille d’échantillon négligée entraînant une fausse précision

(source)
90 personnes répondant « oui » sur 100 personnes ( 90%), contre 900 personnes répondant « oui » sur 1000 personnes (également 90%) ; les pourcentages sont similaires, mais la différence de valeur et de validité des données est statistiquement significative.
Des tailles d’échantillon plus petites garantissent presque des résultats significatifs alarmants. Il faut toujours se méfier des résultats extrêmes et ne jamais accepter les pourcentages pour argent comptant. Selon la chercheuse en biochimie Ana-maria Sundic :
« Pour garantir que l’échantillon est représentatif d’une population, l’échantillonnage doit être aléatoire, c’est-à-dire que chaque sujet doit avoir la même probabilité d’être inclus dans l’étude. Il faut noter qu’un biais d’échantillonnage peut également se produire si l’échantillon est trop petit pour représenter la population cible »
Corrélations et causalités erronées pour créer de fausses statistiques
« Corrélation ne signifie pas causalité ».
Nul doute que vous avez déjà entendu cette phrase, mais pour cause, elle est vraie.
Lorsque deux variables sont corrélées, ce qui suit s’applique généralement :
-
Y cause X.
-
X cause Y.
-
Un troisième facteur déclenche X + Y.
-
La corrélation est due au hasard.
La corrélation et la causalité justifient beaucoup de suspicion car les chercheurs – et les consommateurs desdites recherches – sont la proie de :
-Fétichisme du chiffre
-Chasse à la corrélation
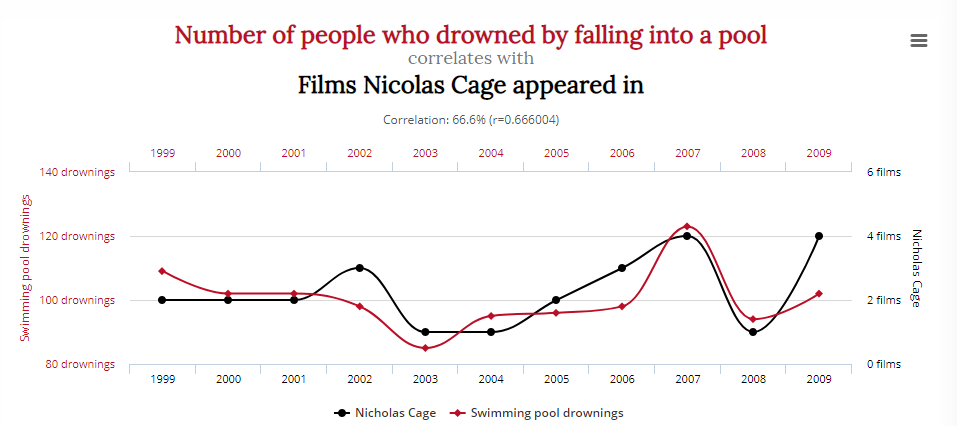
Tyler Vegihn a compilé quelques exemples amusants de statistiques trompeuses pour prouver ce point exact :
Ce graphique dépeint une corrélation convaincante entre le nombre de personnes qui se sont noyées en tombant dans une piscine et le nombre de films dans lesquels Nicolas Cage est apparu :
Un autre montre une corrélation entre le nombre de personnes qui sont mortes en s’empêtrant dans des draps de lit, avec la consommation de fromage :
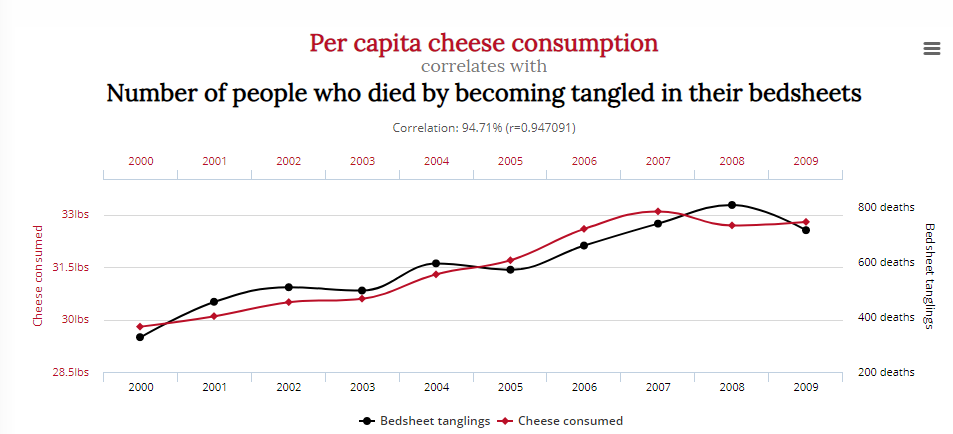
Cela signifie-t-il que la réduction de la consommation de fromage et des rôles d’acteur de Nicolas Cage sauvera des vies ? Probablement pas.
Comme les chercheurs sont pressés de découvrir des données utiles ou de prouver une hypothèse, la tentation de déclarer prématurément un moment « aha » ou « eurêka » est grande.
Cela pose un problème aux analyses et aux statistiques saines ; jetez suffisamment de variables, et vous êtes presque sûr de trouver une corrélation, avec n’importe quoi.
Graphes et visuels trompeurs
Les visualisations de données transforment les chiffres bruts en représentations visuelles des relations, tendances et modèles clés. Bien qu’ils soient capables de donner vie à vos données, ils sont également un support populaire pour les statistiques et les données trompeuses.
Dans son livre « Graphiques, mensonges, visuels trompeurs », le journaliste de données Alberto Cairo expose des exemples de statistiques trompeuses provenant de publicités marketing, de campagnes politiques et de couverture de l’actualité.
Un exemple populaire tiré de l’actualité est l’affaire Terri Schiavo, un cas juridique de droit à mourir aux États-Unis.
Pendant l’affaire, un graphique comme celui ci-dessous a été utilisé par CNN pour décrire comment les différents groupes politiques se sentaient par rapport au retrait du maintien en vie de Terri :
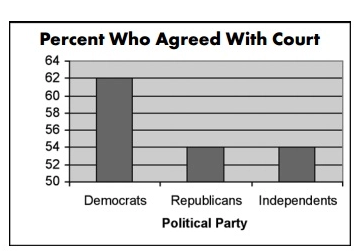
Source
Un coup d’œil à ce graphique suggère que par rapport aux républicains et aux indépendants, 3 fois plus de démocrates étaient d’accord avec le tribunal
Un regard plus attentif, cependant, révèle une petite différence de 14% dans les votes.
Le graphique tronqué et l’axe Y trafiqué (commençant à 50 au lieu de 0) déforment les données et vous amènent à croire une idée exagérée sur un certain groupe.
Évitez d’être induit en erreur lorsque vous consultez des graphiques et des visuels en faisant attention à :
-
L’omission de la ligne de base ou de l’axe tronqué sur un graphique.
-
Les intervalles et les échelles. Vérifiez les incréments inégaux et les mesures impaires (utilisation de chiffres au lieu de pourcentages, etc.).
-
Le contexte complet et d’autres graphiques comparatifs pour voir comment des données similaires sont mesurées et représentées.
Conclusion : Se prémunir contre les données et les statistiques trompeuses
Les statistiques et les données trompeuses vantent des améliorations grandioses du taux de conversion avec des « tweaks CTA » et de « simples changements de couleur ».
Elles créent des titres choquants qui attirent des essaims de trafic mais fournissent au mieux des aperçus imparfaits.
Les mauvaises statistiques et données sont dangereuses.
Au lieu de vous aider à naviguer à travers les détours, les nids de poule et les pièges, elles vous dirigent sciemment – ou non – droit dedans. Mais vous êtes assez intelligent pour les repérer.
La prochaine fois que vous rencontrerez des données convaincantes, courez par ces questions simples mais puissantes :
Qui fait la recherche ?
La recherche est coûteuse et prend du temps. Vérifiez qui la sponsorise, pesez leur parti pris sur le sujet et comment ils pourraient bénéficier des résultats. S’agit-il d’une entreprise B2C avec un produit ? Un service de conseil ? Une étude indépendante financée par une université ?
La taille de l’échantillon et la durée de l’étude peuvent-elles être prises au sérieux ?
L’inspection des chiffres justificatifs ou voilés exposera la faiblesse de la force statistique.
Les visuels de données sont-ils représentés équitablement ?
Les échelles et les intervalles sont-ils uniformément espacés et neutres ? Une statistique pousse-t-elle une idée ou un programme spécifique ? Y a-t-il trop de métriques dans votre tableau de bord ?
La recherche est-elle représentée honnêtement et de manière impartiale ?
Revoir le langage utilisé, la façon dont la question est formulée et les personnes interrogées.
Pour éviter que des statistiques et des données trompeuses ne polluent vos tableaux de bord, rapports et analyses, accueillez les nouvelles informations avec une attitude curieuse et sceptique.
À propos de l’auteur
Hassan Uddeen est un rédacteur indépendant basé au Royaume-Uni pour des entreprises B2B, SaaS et Fintech. Il aime tout ce qui touche au marketing de contenu. Quand il peut s’éloigner du clavier, il aime rebondir dans sa salle de sport personnelle (tout en jouant le rôle de Goku) et se plonger dans un bon roman de James Patterson.