- Populaire strategieën om ontbrekende waarden in een dataset statistisch te imputeren.
- 2- Imputatie met behulp van (gemiddelde/mediane) waarden:
- 3- Imputatie met behulp van (Most Frequent) of (Zero/Constant) waarden:
- 4- Imputatie met behulp van k-NN:
- Hoe werkt het?
- 5- Imputatie met behulp van multivariate Imputation by Chained Equation (MICE)
- 6- Imputation Using Deep Learning (Datawig) raadplegen:
- Stochastische regressie-imputatie:
- Extrapolatie en interpolatie:
- Hot-Deck imputatie:
Populaire strategieën om ontbrekende waarden in een dataset statistisch te imputeren.
Veel real-world datasets kunnen om verschillende redenen ontbrekende waarden bevatten. Ze worden vaak gecodeerd als NaN’s, blanco’s of andere plaatshouders. Het trainen van een model met een dataset met veel ontbrekende waarden kan de kwaliteit van het machine learning model drastisch beïnvloeden. Sommige algoritmen, zoals scikit-learn-schatters, gaan ervan uit dat alle waarden numeriek zijn en een betekenisvolle waarde hebben en houden.
Een manier om met dit probleem om te gaan, is om de waarnemingen met ontbrekende gegevens weg te laten. U loopt echter het risico dat u datapunten met waardevolle informatie verliest. Een betere strategie zou zijn om de ontbrekende waarden toe te schrijven. Met andere woorden, we moeten die ontbrekende waarden afleiden uit het bestaande deel van de gegevens. Er zijn drie hoofdtypen ontbrekende gegevens:
- Missing completely at random (MCAR)
- Missing at random (MAR)
- Not missing at random (NMAR)
Hoewel, in dit artikel, zal ik me concentreren op 6 populaire manieren voor gegevens imputatie voor cross-sectionele datasets ( Time-series dataset is een ander verhaal ).
Dat is een makkelijke. Je laat gewoon het algoritme omgaan met de ontbrekende gegevens. Sommige algoritmen kunnen rekening houden met de ontbrekende waarden en leren de beste imputatiewaarden voor de ontbrekende gegevens op basis van de training verliesreductie (dwz. XGBoost). Sommige andere hebben de optie om ze gewoon te negeren (bv. LightGBM – use_missing=false). Andere algoritmes zullen echter in paniek een foutmelding geven over de ontbrekende waarden (bijv. Scikit learn – LinearRegression). In dat geval moet u de ontbrekende gegevens verwerken en opschonen voordat u deze aan het algoritme toevoegt.
Laten we eens kijken naar enkele andere manieren om de ontbrekende waarden toe te voegen voordat u gaat trainen:
Note: alle onderstaande voorbeelden maken gebruik van de California Housing Dataset van Scikit-learn.
2- Imputatie met behulp van (gemiddelde/mediane) waarden:
Hiermee berekent u het gemiddelde/de mediaan van de niet-ontbrekende waarden in een kolom en vervangt u vervolgens de ontbrekende waarden in elke kolom afzonderlijk en onafhankelijk van de andere. Het kan alleen worden gebruikt voor numerieke gegevens.

Pros:
- Gemakkelijk en snel.
- Werkt goed met kleine numerieke datasets.
Cons:
- Er wordt geen rekening gehouden met de correlaties tussen kenmerken. Het werkt alleen op kolomniveau.
- Geeft slechte resultaten bij gecodeerde categorische kenmerken (NIET gebruiken bij categorische kenmerken).
- Niet erg nauwkeurig.
- Geeft geen rekening met de onzekerheid in de imputaties.
3- Imputatie met behulp van (Most Frequent) of (Zero/Constant) waarden:
Most Frequent is een andere statistische strategie om ontbrekende waarden te imputeren en JA!!! Het werkt met categorische kenmerken (strings of numerieke representaties) door ontbrekende gegevens te vervangen door de meest frequente waarden binnen elke kolom.
Pros:
- Werkt goed met categorische kenmerken.
Cons:
- Het houdt ook geen rekening met de correlaties tussen kenmerken.
- Het kan bias in de gegevens introduceren.
Zero or Constant imputation – zoals de naam al aangeeft – vervangt deze methode de ontbrekende waarden door ofwel nul ofwel een door u opgegeven constante waarde

4- Imputatie met behulp van k-NN:
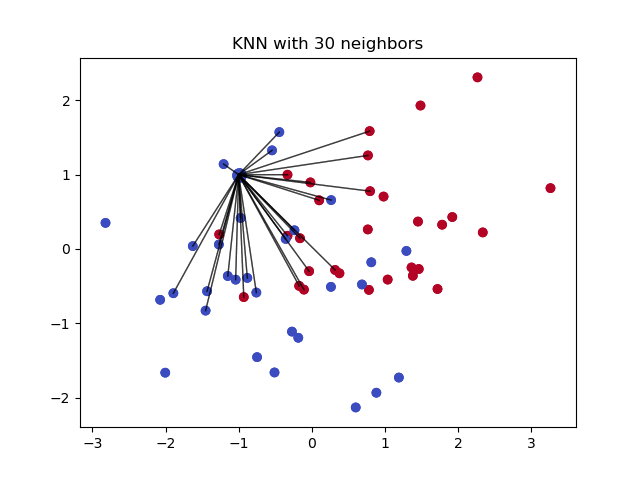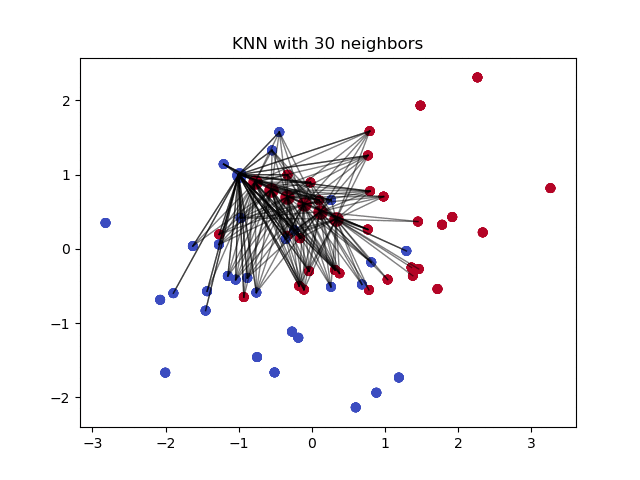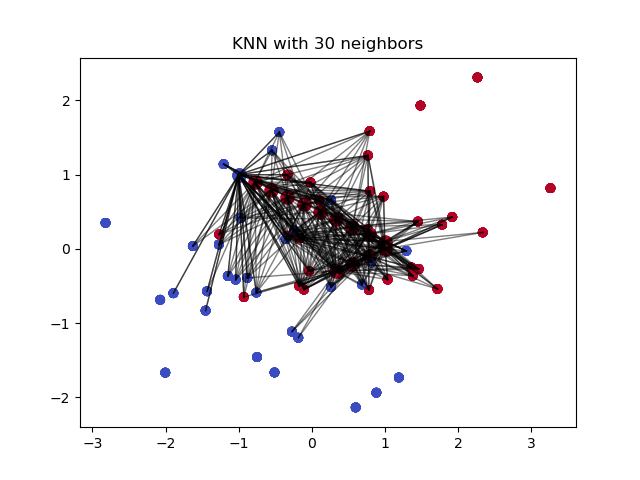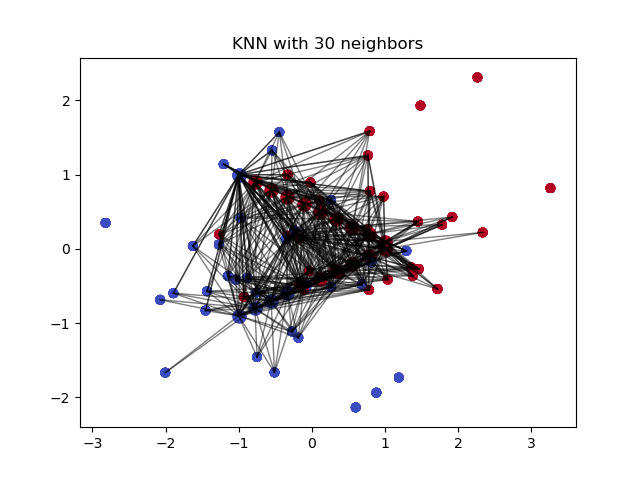
De k nearest neighbours is een algoritme dat wordt gebruikt voor eenvoudige classificatie. Het algoritme gebruikt ‘feature similarity’ om de waarden van nieuwe gegevenspunten te voorspellen. Dit betekent dat aan het nieuwe punt een waarde wordt toegekend op basis van hoe sterk het lijkt op de punten in de trainingsverzameling. Dit kan zeer nuttig zijn bij het maken van voorspellingen over ontbrekende waarden door de k’s naaste buren van de waarneming met ontbrekende gegevens te vinden en deze dan toe te rekenen op basis van de niet-ontbrekende waarden in de buurt. Laten we eens wat voorbeeldcode bekijken met behulp van de Impyute-bibliotheek, die een eenvoudige en gemakkelijke manier biedt om KNN voor imputatie te gebruiken:
Hoe werkt het?
Het creëert een basis gemiddelde imputatie en gebruikt vervolgens de resulterende volledige lijst om een KDTree te construeren. Vervolgens wordt de resulterende KDTree gebruikt om de dichtstbijzijnde buren (NN) te berekenen. Nadat de k-NN’s zijn gevonden, wordt het gewogen gemiddelde genomen.
Pro’s:
- Kan veel nauwkeuriger zijn dan de gemiddelde, mediane of meest frequente imputatiemethoden (dit hangt af van de dataset).
Cons:
- Computationeel duur. KNN werkt door de hele trainingsdataset in het geheugen op te slaan.
- K-NN is nogal gevoelig voor uitschieters in de gegevens (in tegenstelling tot SVM)
5- Imputatie met behulp van multivariate Imputation by Chained Equation (MICE)
Dit type imputatie werkt door de ontbrekende gegevens meerdere keren aan te vullen. Meervoudige imputaties (MI’s) zijn veel beter dan een enkelvoudige imputatie, omdat de onzekerheid van de ontbrekende waarden op een betere manier wordt gemeten. De aanpak met geketende vergelijkingen is ook zeer flexibel en kan verschillende variabelen van verschillende gegevenstypen (d.w.z. continu of binair) en complexiteiten zoals grenzen of patronen voor het overslaan van enquêtes verwerken. Voor meer informatie over de algoritmemechanica kunt u de Research Paper

6- Imputation Using Deep Learning (Datawig) raadplegen:
Deze methode werkt heel goed met categorische en niet-numerieke kenmerken. Het is een bibliotheek die Machine Learning modellen leert met behulp van Deep Neural Networks om ontbrekende waarden in een dataframe toe te voegen. Het ondersteunt ook zowel CPU als GPU voor training.
Pro’s:
- Nauwkeurig in vergelijking met andere methoden.
- Het heeft enkele functies die categorische gegevens aankunnen (Feature Encoder).
- Het ondersteunt CPU’s en GPU’s.
Cons:
- Single Column imputation.
- Kan vrij traag zijn met grote datasets.
- U moet de kolommen specificeren die informatie bevatten over de doelkolom die zal worden geïmputeerd.
Stochastische regressie-imputatie:
Het lijkt veel op regressie-imputatie, waarbij wordt geprobeerd de ontbrekende waarden te voorspellen door deze te regresseren op andere verwante variabelen in dezelfde dataset plus een willekeurige restwaarde.
Extrapolatie en interpolatie:
Probeert waarden te schatten uit andere waarnemingen binnen het bereik van een discrete reeks bekende gegevenspunten.
Hot-Deck imputatie:
Werkt door de ontbrekende waarde willekeurig te kiezen uit een reeks verwante en soortgelijke variabelen.
Tot besluit: er is geen perfecte manier om de ontbrekende waarden in een dataset te compenseren. Elke strategie kan beter presteren voor bepaalde datasets en ontbrekende gegevenstypen, maar kan veel slechter presteren bij andere soorten datasets. Er zijn enkele vaste regels om te beslissen welke strategie voor bepaalde soorten ontbrekende waarden moet worden gebruikt, maar verder moet u experimenteren en nagaan welk model het beste werkt voor uw dataset.