In deze blog bespreken we de basisconcepten van Logistische regressie en wat voor soort problemen we ermee kunnen oplossen.

Logistische regressie is een classificatiealgoritme dat wordt gebruikt om waarnemingen aan een discrete reeks klassen toe te wijzen. Voorbeelden van classificatieproblemen zijn: spam of geen spam in e-mail, fraude of geen fraude bij onlinetransacties, kwaadaardige of goedaardige tumoren. Logistische regressie transformeert zijn uitvoer met behulp van de logistische sigmoid-functie om een waarschijnlijkheidswaarde terug te geven.
Wat zijn de soorten logistische regressie
- Binaire (bijv. Tumor kwaadaardig of goedaardig)
- Multi-lineaire functies falenClass (bijv. Katten, honden of schapen)
Logistische regressie
Logistische regressie is een Machine Learning algoritme dat wordt gebruikt voor de classificatie problemen, het is een voorspellende analyse algoritme en gebaseerd op het concept van waarschijnlijkheid.

We kunnen een logistische regressie een lineair regressiemodel noemen, maar de logistische regressie maakt gebruik van een complexere kostenfunctie, deze kostenfunctie kan worden gedefinieerd als de ‘Sigmoid-functie’ of ook bekend als de ‘logistische functie’ in plaats van een lineaire functie.
De hypothese van logistische regressie heeft de neiging de kostenfunctie te beperken tussen 0 en 1. Daarom kunnen lineaire functies deze niet weergeven, omdat ze een waarde groter dan 1 of kleiner dan 0 kunnen hebben, wat niet mogelijk is volgens de hypothese van logistische regressie.
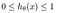
Wat is de Sigmoid-functie?
Om voorspelde waarden in waarschijnlijkheden om te zetten, gebruiken we de Sigmoid-functie. De functie zet elke reële waarde om in een andere waarde tussen 0 en 1. Bij machinaal leren gebruiken we de Sigmoid-functie om voorspellingen om te zetten in waarschijnlijkheden.


Voorstelling van de hypothese
Wanneer we lineaire regressie gebruiken, gebruiken we een formule van de hypothese, nl.
hΘ(x) = β₀ + β₁X
Voor logistische regressie gaan we deze een beetje aanpassen, nl.e.
σ(Z) = σ(β₀ + β₁X)
We hebben verwacht dat onze hypothese waarden tussen 0 en 1 zal opleveren.
Z = β₀ + β₁X
hΘ(x) = sigmoid(Z)
d.w.z. hΘ(x) = 1/(1 + e^-(β₀ + β₁X)

Beslissingsgrens
Wij verwachten dat onze classificator ons een reeks outputs of klassen geeft op basis van waarschijnlijkheid wanneer we de inputs door een voorspellingsfunctie halen en een waarschijnlijkheidsscore tussen 0 en 1 retourneert.
Voorbeeld, we hebben 2 klassen, laten we ze nemen als katten en honden(1 – hond , 0 – katten). In principe bepalen we een drempelwaarde waarboven we de waarden in klasse 1 indelen en als de waarde onder de drempelwaarde komt, delen we deze in klasse 2 in.
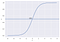
Zoals in de bovenstaande grafiek te zien is, hebben we de drempelwaarde op 0,5 gesteld. Als de voorspellingsfunctie een waarde van 0,7 zou opleveren, zouden we deze waarneming in klasse 1 (HOND) indelen. Als onze voorspelling een waarde van 0,2 oplevert, classificeren we de waarneming als Klasse 2 (CAT).
Kostenfunctie
We hebben geleerd over de kostenfunctie J(θ) in de lineaire regressie, de kostenfunctie vertegenwoordigt optimalisatiedoelstelling, d.w.z. we creëren een kostenfunctie en minimaliseren deze, zodat we een nauwkeurig model met minimale fout kunnen ontwikkelen.
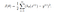
Als we proberen de kostenfunctie van de lineaire regressie te gebruiken in ‘Logistische regressie’, dan zou dat geen nut hebben, omdat het een niet-convexe functie zou worden met veel lokale minima, waarbij het zeer moeilijk zou zijn om de kostenwaarde te minimaliseren en het globale minimum te vinden.

Voor logistische regressie wordt de kostenfunctie gedefinieerd als:
-log(hθ(x)) als y = 1
-log(1-hθ(x)) als y = 0
