„74% firm mówi, że chce być „data-driven”, tylko 29% twierdzi, że jest dobrych w łączeniu analityki z działaniem.” – Forrester
Generowanie, przetwarzanie i udostępnianie statystyk i danych – czy te działania czynią Cię firmą „sterowaną danymi”?
Z pewnością tak, ale jeśli dane i statystyki napędzające Twoje decyzje są niedokładne, lub całkowicie fałszywe, wynikające z tego negatywne rezultaty mogą wywołać zamieszanie i słabą wydajność.
Ważne dane eliminują przerażającą perspektywę polegania na kapryśnych domysłach i „przeczuciach”. Łączą one ludzkie doświadczenie i intuicję z konkretnymi liczbami i analizami, aby rodzić decyzje zdolne do poruszenia igły.
Ale intuicyjne pulpity, wykresy, statystyki i grafy często maskują fałszywą rzeczywistość:
Wprowadzające w błąd statystyki i dane.
Przy szybko rozwijającej się technologii i dostosowujących się w równym tempie użytkownikach, firmy zaczęły polegać na danych i statystykach, aby poruszać się w konkurencyjnym środowisku biznesowym.
Ale łatwo jest dać się zaślepić absolutności liczb, zwłaszcza gdy uwiarygodniają one korzystne hipotezy lub punkty.
Nierozpoznanie fałszywych statystyk i danych stanowi zagrożenie dla podejmowania decyzji opartych na danych.
Zachęca Cię to do naciskania przysłowiowych niewłaściwych przycisków z pełnym zaufaniem, i w tym właśnie tkwi niebezpieczeństwo.
W tym wpisie dowiesz się, jak rozpoznać wprowadzające w błąd statystyki i dane. Przyjrzymy się powszechnym sposobom wprowadzania w błąd oraz temu, jak określić, kiedy dane mogą mieć wpływ na podejmowanie krytycznych decyzji.
- Co to jest wprowadzająca w błąd statystyka?
- Selective Bias To Create False Statistics
- Neglected Sample Size Resulting In False Precision
- Wadliwe korelacje i związki przyczynowe do tworzenia fałszywych statystyk
- Wprowadzające w błąd wykresy i wizualizacje
- Zakończenie: Ochrona przed wprowadzającymi w błąd danymi i statystykami
- O autorze
Co to jest wprowadzająca w błąd statystyka?
Źródło
Wprowadzające w błąd statystyki powstają, gdy błąd – zamierzony lub nie – jest obecny w jednym z 3 kluczowych aspektów badań:
-
Zbieranie: Używanie małych wielkości próbek, które projektują duże liczby, ale mają niewielkie znaczenie statystyczne.
-
Organizowanie: Pomijanie wyników, które są sprzeczne z punktem, który badacz stara się udowodnić.
-
Prezentowanie: Manipulowanie danymi wizualnymi/numerycznymi w celu wpłynięcia na percepcję.
Złe statystyki wkradają się do serwisów informacyjnych, kampanii reklamowych, a nawet literatury naukowej. Szokujące 33,7% naukowców – superlatywy bycia neutralnym wobec danych – przyznało się do niewłaściwego wykorzystania statystyk w celu wsparcia badań. Tak, nawet niektórzy z zaufanych strażników informacji są winni.
Aby pomóc Ci w podejmowaniu krytycznych decyzji w oparciu o właściwe dane, wymieniliśmy powszechne sposoby, w jakie statystyki wprowadzają w błąd i dezinformują.
Selective Bias To Create False Statistics
Badanie przeprowadzone przez Elizabeth Loftus przetestowało wpływ języka na zeznania naocznych świadków. Osobom badanym pokazywano film przedstawiający wiele wypadków samochodowych. Po obejrzeniu zapytano ich: „Z jaką prędkością jechały te samochody, kiedy się o siebie rozbiły?”
Innym badanym zadano następnie to samo pytanie, aczkolwiek słowo „roztrzaskały się” zastąpiono sugestywnymi czasownikami, takimi jak:
-
Zderzyły się
-
Zderzyły się
-
Zderzyły się
Wyniki?
Im silniejszy był użyty „załadowany” czasownik, tym wyższa była szacunkowa prędkość podana przez świadków.
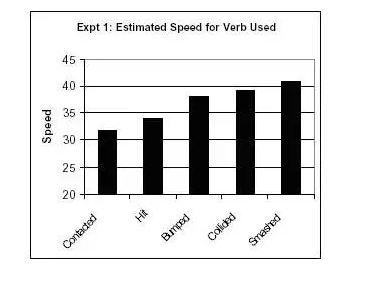
Źródło
Co więcej, badanie wykazało, że przy użyciu silniejszego czasownika badani częściej zgłaszali rozbite szkło podczas wypadku, nawet jeśli rozbite szkło nie zostało pokazane na filmie.
Używanie języka do wpływania na odpowiedzi i wyniki ankiety jest tylko jednym z przykładów stronniczości selekcji. W 2007 roku Urząd Standardów Reklamy (ASA) zmusił firmę Colgate do porzucenia twierdzenia, że „ponad 80% dentystów zaleca stosowanie pasty Colgate”, ponieważ twierdzenie to wprowadzało w błąd, sugerując, że „80% dentystów zaleca pastę do zębów Colgate przed wszystkimi innymi markami”.
Prawdziwe pytanie ankiety brzmiało: „mając wybór pomiędzy samodzielnym szczotkowaniem zębów a używaniem pasty do zębów – takiej jak Colgate – którą by polecili.”
Poprzez wyłuskanie odpowiedzi z ankiety Colgate sprawiło wrażenie, że dentyści polecali ich w porównaniu z markami konkurentów; rzeczywiste zalecenie brzmiało: używanie jakiejkolwiek pasty do zębów jest lepsze niż samodzielne szczotkowanie.
Selective bias często występuje, gdy wybrane próbki lub dane są niekompletne lub cherrypicked, aby wpłynąć na percepcję – a nawet przekłamać – statystyki i dane.
Neglected Sample Size Resulting In False Precision

(źródło)
90 osób odpowiadających „tak” na 100 osób (90%), versus 900 osób odpowiadających „tak” na 1000 osób (również 90%); procenty są podobne, ale różnica w wartości i ważności danych jest statystycznie znacząca.
Mniejsze wielkości próbek prawie gwarantują niepokojąco znaczące wyniki. Zawsze uważaj na skrajne wyniki i nigdy nie akceptuj procentów w wartości nominalnej. W słowach badacza biochemii Ana-maria Sundic:
„Aby zapewnić, że próba jest reprezentatywna dla populacji, dobór próby powinien być losowy, tzn. każdy podmiot musi mieć równe prawdopodobieństwo włączenia do badania. Należy zauważyć, że tendencyjność próbkowania może również wystąpić, jeśli próba jest zbyt mała, aby reprezentować populację docelową”
Wadliwe korelacje i związki przyczynowe do tworzenia fałszywych statystyk
„Korelacja nie oznacza związku przyczynowego”.
Nie ma wątpliwości, że słyszałeś to zdanie wcześniej, ale nie bez powodu jest ono prawdziwe.
Kiedy dwie zmienne korelują ze sobą, zwykle stosuje się następujące zasady:
-
Y powoduje X.
-
X powoduje Y.
-
Trzeci czynnik wywołuje X + Y.
-
Korelacja jest dziełem przypadku.
Korelacja i związek przyczynowy uzasadniają wiele podejrzeń, ponieważ badacze – i konsumenci wspomnianych badań – padają ofiarą:
-fetyszyzmu liczb
-polowania na korelację
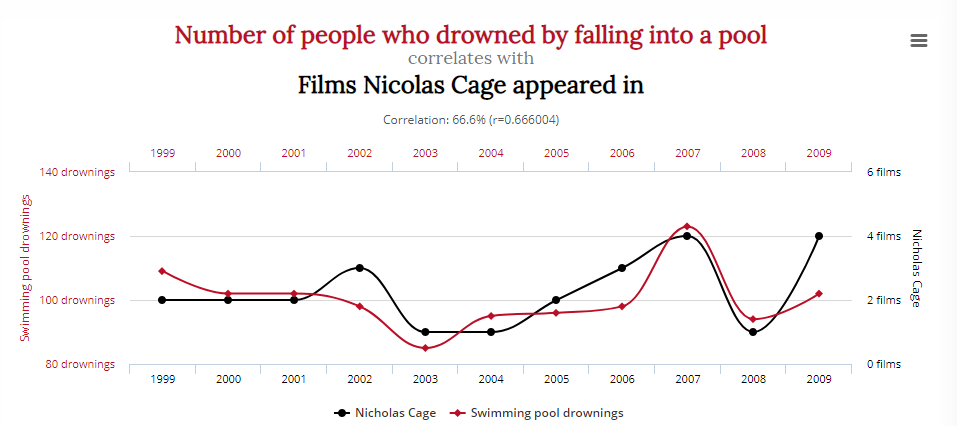
Tyler Vegihn skompilował kilka zabawnych, mylących przykładów statystyk, aby udowodnić ten dokładny punkt:
Ten wykres przedstawia zniewalającą korelację pomiędzy liczbą osób, które utonęły wpadając do basenu, a liczbą filmów, w których wystąpił Nicolas Cage:
Inny pokazuje korelację między liczbą osób, które zmarły przez zaplątanie się w pościel, a spożyciem sera:
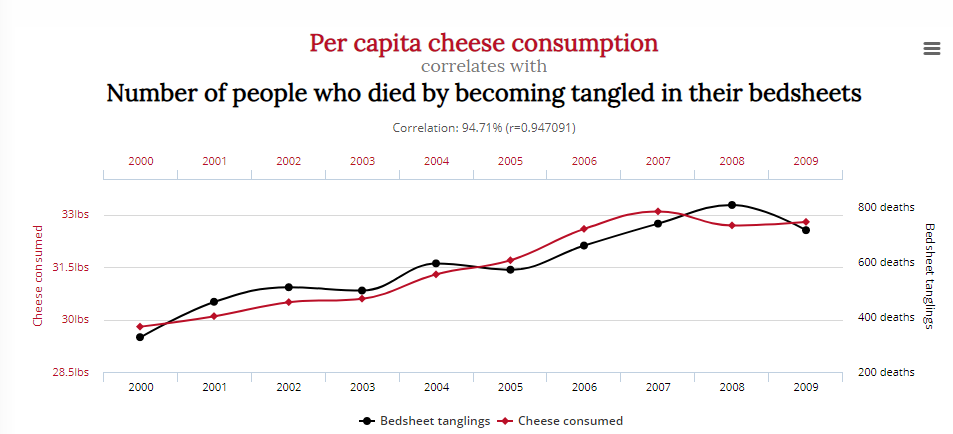
Czy to oznacza, że zmniejszenie spożycia sera i ról aktorskich Nicolasa Cage’a uratuje życie? Prawdopodobnie nie.
Zważywszy, że badacze są naciskani, aby odkryć użyteczne dane lub udowodnić hipotezę, pokusa przedwczesnego ogłoszenia momentu „aha” lub „eureka” jest wysoka.
To stanowi problem dla zdrowych analiz i statystyk; wrzuć wystarczająco dużo zmiennych, a prawie na pewno znajdziesz korelację, z czymkolwiek.
Wprowadzające w błąd wykresy i wizualizacje
Wizualizacje danych zmieniają surowe liczby w wizualne reprezentacje kluczowych relacji, trendów i wzorów. Chociaż są one w stanie ożywić Twoje dane, są również popularnym medium dla wprowadzających w błąd statystyk i danych.
W swojej książce „Grafiki, kłamstwa, wprowadzające w błąd wizualizacje” dziennikarz danych Alberto Cairo demaskuje wprowadzające w błąd przykłady statystyk z reklam marketingowych, kampanii politycznych i wiadomości.
Jednym z popularnych przykładów z wiadomości jest sprawa Terri Schiavo, sprawa prawna dotycząca prawa do śmierci w USA.
Podczas tej sprawy, wykres taki jak ten poniżej został użyty przez CNN do zobrazowania opinii różnych grup politycznych na temat usunięcia Terri z systemu podtrzymywania życia:
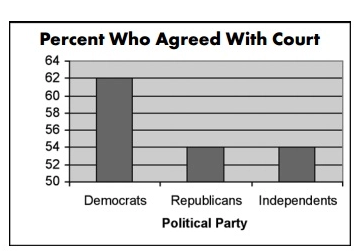
Źródło
Spojrzenie na ten wykres sugeruje, że w porównaniu z Republikanami i Niezależnymi, 3 razy więcej Demokratów zgodziło się z sądem
Bliższe spojrzenie ujawnia jednak niewielką, 14% różnicę w głosach.
Przycięty wykres i zmanipulowana oś Y (zaczynająca się od 50 zamiast 0) zniekształcają dane i skłaniają do uwierzenia w przesadzone wyobrażenie o pewnej grupie.
Unikaj wprowadzania w błąd podczas przeglądania wykresów i wizualizacji, zwracając uwagę na:
-
Pominięcie linii bazowej lub przyciętej osi na wykresie.
-
Przedziały i skale. Należy sprawdzić, czy nie ma nierównych przyrostów i dziwnych pomiarów (stosowanie liczb zamiast procentów itp.).
-
Pełny kontekst i inne wykresy porównawcze, aby zobaczyć, jak podobne dane są mierzone i przedstawiane.
Zakończenie: Ochrona przed wprowadzającymi w błąd danymi i statystykami
Wprowadzające w błąd statystyki i dane chwalą się wspaniałymi ulepszeniami współczynnika konwersji dzięki „poprawkom CTA” i „prostym zmianom kolorów”.
Tworzą one szokujące nagłówki, które przyciągają roje ruchu, ale w najlepszym wypadku dostarczają błędnych spostrzeżeń.
Złe statystyki i dane są niebezpieczne.
Nie pomagają Ci poruszać się po objazdach, wybojach i pułapkach, ale świadomie – lub nieświadomie – kierują Cię prosto w nie. Ale Ty jesteś wystarczająco bystry, aby je zauważyć.
Następnym razem, gdy napotkasz przekonujące dane, zadaj sobie te proste, ale potężne pytania:
Kto przeprowadza badania?
Badania są drogie i czasochłonne. Sprawdź, kto je sponsoruje, zważ ich uprzedzenia do tematu i jak mogą skorzystać z wyników. Czy jest to firma B2C z produktem? Usługa konsultingowa? Czy jest to niezależne badanie finansowane przez uniwersytet?
Czy wielkość próby i długość badania mogą być traktowane poważnie?
Sprawdzenie liczb pomocniczych lub zawoalowanych ujawni słabą siłę statystyczną.
Czy wizualizacje danych są przedstawiane uczciwie?
Czy skale i interwały są równomiernie rozmieszczone i neutralne? Czy dana statystyka promuje konkretny pomysł lub agendę? Czy na pulpicie nawigacyjnym jest zbyt wiele wskaźników?
Czy badania są przedstawione uczciwie i bezstronnie?
Zapoznaj się z używanym językiem, sposobem formułowania pytań i osobami badanymi.
Aby zapobiec zanieczyszczaniu pulpitów, raportów i analiz przez wprowadzające w błąd statystyki i dane, witaj nowe informacje z ciekawością i sceptycyzmem.
O autorze
Hassan Uddeen jest brytyjskim freelancerem piszącym dla firm B2B, SaaS i Fintech. Uwielbia wszystkie rzeczy związane z marketingiem treści. Kiedy może oderwać się od klawiatury, lubi obijać się na domowej siłowni (grając jako Goku) i zagłębiać się w dobrej powieści Jamesa Pattersona.