- Strategii populare de imputare statistică a valorilor lipsă într-un set de date.
- 2- Imputarea folosind valorile (medie/mediană):
- 3- Imputarea folosind valori (cele mai frecvente) sau (zero/constante):
- 4- Imputarea folosind k-NN:
- Cum funcționează?
- 5-. Imputarea cu ajutorul imputării multivariate prin ecuație înlănțuită (MICE)
- 6- Imputation Using Deep Learning (Datawig):
- Imputarea prin regresie stochastică:
- Extrapolare și interpolare:
- Imputare Hot-Deck:
Strategii populare de imputare statistică a valorilor lipsă într-un set de date.
Multe seturi de date din lumea reală pot conține valori lipsă din diverse motive. Acestea sunt adesea codificate ca NaNs, spații goale sau orice alte spații libere. Antrenarea unui model cu un set de date care are o mulțime de valori lipsă poate avea un impact drastic asupra calității modelului de învățare automată. Unii algoritmi, cum ar fi estimatorii scikit-learn, presupun că toate valorile sunt numerice și au și păstrează o valoare semnificativă.
O modalitate de a rezolva această problemă este de a scăpa de observațiile care au date lipsă. Cu toate acestea, veți risca să pierdeți puncte de date cu informații valoroase. O strategie mai bună ar fi să imputați valorile lipsă. Cu alte cuvinte, trebuie să deducem acele valori lipsă din partea existentă a datelor. Există trei tipuri principale de date lipsă:
- Lipsesc complet la întâmplare (MCAR)
- Lipsesc la întâmplare (MAR)
- Nu lipsesc la întâmplare (NMAR)
Cu toate acestea, în acest articol, mă voi concentra pe 6 modalități populare de imputare a datelor pentru seturile de date transversale ( Setul de date cu serii de timp este o poveste diferită ).
Esta este una ușoară. Pur și simplu lăsați algoritmul să se ocupe de datele lipsă. Unii algoritmi pot lua în considerare valorile lipsă și pot învăța cele mai bune valori de imputare pentru datele lipsă pe baza reducerii pierderilor de instruire (de exemplu, XGBoost). Alții au opțiunea de a le ignora pur și simplu (de exemplu, LightGBM – use_missing=false). Cu toate acestea, alți algoritmi vor intra în panică și vor afișa o eroare care se va plânge de valorile lipsă (de exemplu, Scikit learn – LinearRegression). În acest caz, va trebui să vă ocupați de datele lipsă și să le curățați înainte de a le transmite algoritmului.
Să vedem alte modalități de a imputa valorile lipsă înainte de instruire:
Nota: Toate exemplele de mai jos utilizează setul de date California Housing Dataset din Scikit-learn.
2- Imputarea folosind valorile (medie/mediană):
Acest lucru funcționează prin calcularea mediei/medianei valorilor care nu lipsesc într-o coloană și apoi înlocuirea valorilor lipsă din fiecare coloană separat și independent de celelalte. Se poate utiliza numai cu date numerice.

Pros:
- Ușor și rapid.
- Funcționează bine cu seturi de date numerice mici.
Cons:
- Nu ține cont de corelațiile dintre caracteristici. Funcționează numai la nivel de coloană.
- Dă rezultate slabe în cazul caracteristicilor categorice codificate (NU îl utilizați pe caracteristici categorice).
- Nu este foarte precis.
- Nu ține cont de incertitudinea din imputări.
3- Imputarea folosind valori (cele mai frecvente) sau (zero/constante):
Cele mai frecvente este o altă strategie statistică de imputare a valorilor lipsă și DA!!! Funcționează cu caracteristici categorice (șiruri de caractere sau reprezentări numerice) prin înlocuirea datelor lipsă cu cele mai frecvente valori din cadrul fiecărei coloane.
Pros:
- Funcționează bine cu caracteristici categorice.
Cons:
- De asemenea, nu ia în considerare corelațiile dintre caracteristici.
- Poate introduce distorsiuni în date.
Imputarea zero sau constantă – după cum sugerează și numele – înlocuiește valorile lipsă fie cu zero, fie cu orice valoare constantă pe care o specificați

4- Imputarea folosind k-NN:
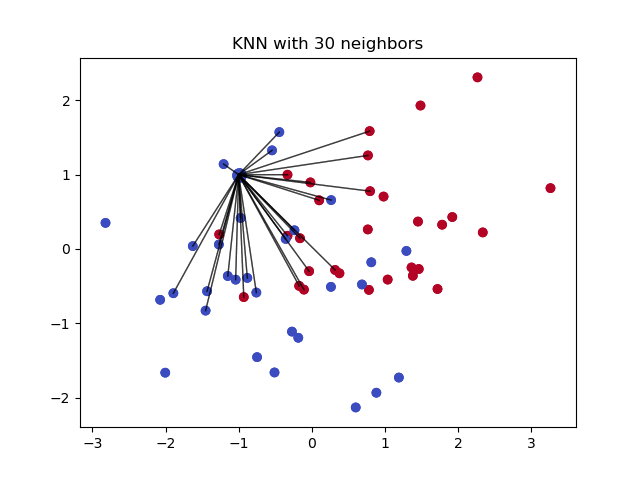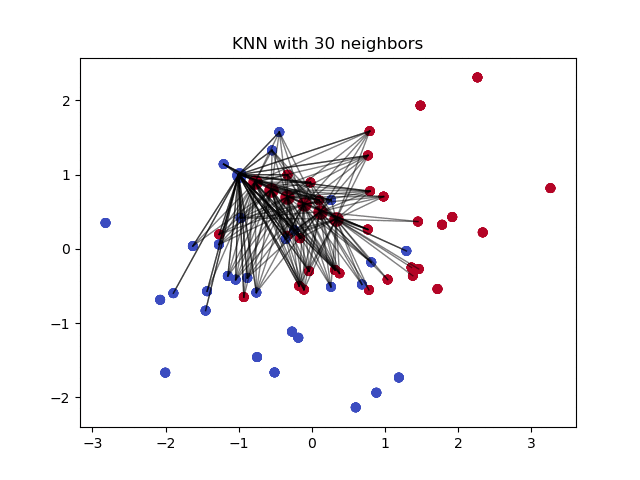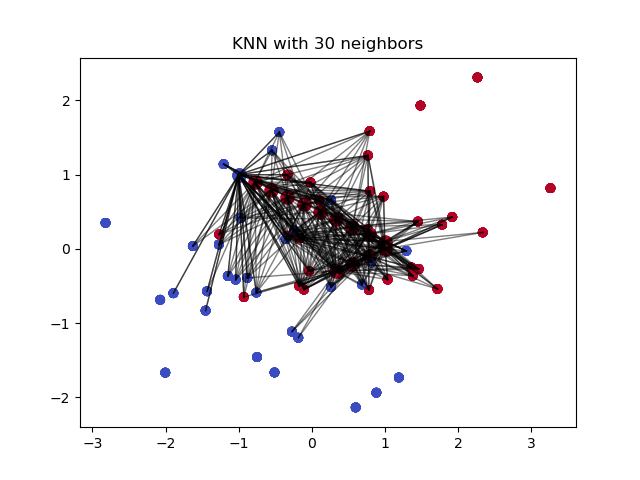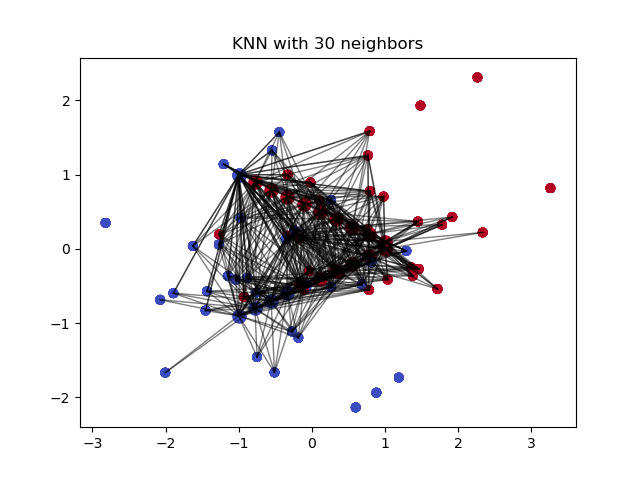
Vecinii cei mai apropiați k este un algoritm care este utilizat pentru clasificarea simplă. Algoritmul utilizează „similitudinea caracteristicilor” pentru a prezice valorile oricăror noi puncte de date. Aceasta înseamnă că noului punct i se atribuie o valoare în funcție de cât de mult se aseamănă cu punctele din setul de antrenament. Acest lucru poate fi foarte util pentru a face predicții cu privire la valorile lipsă prin găsirea celor mai apropiați vecini k ai observației cu date lipsă și apoi prin imputare pe baza valorilor care nu lipsesc din vecinătate. Să vedem câteva exemple de cod care utilizează biblioteca Impyute care oferă o modalitate simplă și ușoară de a utiliza KNN pentru imputare:
Cum funcționează?
Creează o imputare medie de bază, apoi utilizează lista completă rezultată pentru a construi un KDTree. Apoi, utilizează KDTree-ul rezultat pentru a calcula vecinii cei mai apropiați (NN). După ce găsește cei k-NN, ia media ponderată a acestora.
Pros:
- Poate fi mult mai precisă decât metodele de imputare medie, mediană sau cea mai frecventă (Depinde de setul de date).
Cons:
- Costisitoare din punct de vedere computațional. KNN funcționează prin stocarea în memorie a întregului set de date de instruire.
- K-NN este destul de sensibil la valorile aberante din date (spre deosebire de SVM)
5-. Imputarea cu ajutorul imputării multivariate prin ecuație înlănțuită (MICE)
Acest tip de imputare funcționează prin completarea de mai multe ori a datelor lipsă. Imputările multiple (IM) sunt mult mai bune decât o singură imputare, deoarece măsoară incertitudinea valorilor lipsă într-un mod mai bun. Abordarea cu ecuații înlănțuite este, de asemenea, foarte flexibilă și poate gestiona diferite variabile de diferite tipuri de date (de exemplu, continue sau binare), precum și complexități, cum ar fi limitele sau modelele de omisiune ale sondajului. Pentru mai multe informații despre mecanica algoritmului, puteți consulta lucrarea de cercetare

6- Imputation Using Deep Learning (Datawig):
Această metodă funcționează foarte bine cu caracteristici categorice și nenumerice. Este o bibliotecă care învață modele de învățare automată folosind rețele neuronale profunde pentru a imputa valorile lipsă într-un cadru de date. De asemenea, suportă atât CPU, cât și GPU pentru instruire.
Pros:
- Destul de precisă în comparație cu alte metode.
- Dispune de câteva funcții care pot gestiona date categorice (Feature Encoder).
- Suportă procesoare și GPU.
Cons:
- Imputare pe o singură coloană.
- Poate fi destul de lent cu seturi mari de date.
- Trebuie să specificați coloanele care conțin informații despre coloana țintă care va fi imputată.
Imputarea prin regresie stochastică:
Este destul de asemănătoare cu imputarea prin regresie, care încearcă să prezică valorile lipsă prin regresie pe baza altor variabile înrudite din același set de date plus o anumită valoare reziduală aleatorie.
Extrapolare și interpolare:
Încearcă să estimeze valorile din alte observații în intervalul unui set discret de puncte de date cunoscute.
Imputare Hot-Deck:
Funcționează prin alegerea aleatorie a valorii lipsă dintr-un set de variabile înrudite și similare.
În concluzie, nu există o modalitate perfectă de compensare a valorilor lipsă dintr-un set de date. Fiecare strategie poate funcționa mai bine pentru anumite seturi de date și tipuri de date lipsă, dar poate funcționa mult mai prost în cazul altor tipuri de seturi de date. Există câteva reguli prestabilite pentru a decide ce strategie să utilizați pentru anumite tipuri de valori lipsă, dar, dincolo de acestea, ar trebui să experimentați și să verificați ce model funcționează cel mai bine pentru setul dvs. de date.
.