În acest blog, vom discuta conceptele de bază ale regresiei logistice și ce fel de probleme ne poate ajuta să rezolvăm.

Regresia logistică este un algoritm de clasificare utilizat pentru a atribui observații la un set discret de clase. Câteva dintre exemplele de probleme de clasificare sunt: Email spam sau nu spam, Tranzacții online frauduloase sau nu frauduloase, Tumoare maligne sau benigne. Regresia logistică își transformă ieșirea folosind funcția logistică sigmoidă pentru a returna o valoare de probabilitate.
Care sunt tipurile de regresie logistică
- Binare (ex. Tumor Malign sau Benign)
- Funcții multiliniare eșueazăClasa (ex. Pisici, câini sau oi)
Regresie logistică
Regresia logistică este un algoritm de învățare automată care este utilizat pentru problemele de clasificare, este un algoritm de analiză predictivă și se bazează pe conceptul de probabilitate.

Potem numi modelul de regresie logistică un model de regresie liniară, dar regresia logistică folosește o funcție de cost mai complexă, această funcție de cost poate fi definită ca fiind „funcția Sigmoid” sau cunoscută și sub numele de „funcție logistică” în loc de o funcție liniară.
Ipoteza regresiei logistice tinde să o limiteze funcția de cost între 0 și 1. Prin urmare, funcțiile liniare nu reușesc să o reprezinte, deoarece aceasta poate avea o valoare mai mare decât 1 sau mai mică decât 0, ceea ce nu este posibil conform ipotezei regresiei logistice.
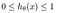
Ce este funcția Sigmoid?
Pentru a pune în corespondență valorile prezise cu probabilitățile, se folosește funcția Sigmoid. Funcția mapează orice valoare reală într-o altă valoare între 0 și 1. În învățarea automată, folosim sigmoid pentru a cartografia predicțiile în probabilități.


Reprezentarea ipotezei
Când folosim regresia liniară folosim o formulă a ipotezei, adică:
hΘ(x) = β₀ + β₁X
Pentru regresia logistică o vom modifica puțin i.e.
σ(Z) = σ(β₀ + β₁X)
Ne-am așteptat ca ipoteza noastră să dea valori cuprinse între 0 și 1.
Z = β₀ + β₁X
hΘ(x) = sigmoid(Z)
i.e. hΘ(x) = 1/(1 + e^-(β₀ + β₁X)

Limitația de decizie
.
Ne așteptăm ca clasificatorul nostru să ne ofere un set de ieșiri sau clase bazate pe probabilitate atunci când trecem intrările printr-o funcție de predicție și returnează un scor de probabilitate între 0 și 1.
De exemplu, avem 2 clase, să le luăm ca fiind pisici și câini (1 – câine , 0 – pisici). Practic, decidem cu o valoare de prag peste care clasificăm valorile în clasa 1, iar dacă valoarea se situează sub prag, atunci o clasificăm în clasa 2.
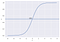
După cum se arată în graficul de mai sus, am ales pragul de 0,5, dacă funcția de predicție ar fi returnat o valoare de 0,7 atunci am clasifica această observație în Clasa 1(CÂINE). Dacă predicția noastră a returnat o valoare de 0,2, atunci am clasifica observația ca fiind Clasa 2(CAT).
Funcția de cost
Am învățat despre funcția de cost J(θ) în regresia liniară, funcția de cost reprezintă obiectivul de optimizare, adică creăm o funcție de cost și o minimizăm astfel încât să putem dezvolta un model precis cu eroare minimă.
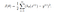
Dacă încercăm să folosim funcția de cost a regresiei liniare în „Regresia logistică”, atunci nu ne-ar fi de folos, deoarece ar sfârși prin a fi o funcție neconvexă cu multe minime locale, în care ar fi foarte dificil să minimizăm valoarea costului și să găsim minimul global.

Pentru regresia logistică, funcția de cost se definește astfel:
-log(hθ(x)) dacă y = 1
-log(1-hθ(x)) dacă y = 0

.