I den här bloggen kommer vi att diskutera de grundläggande begreppen för logistisk regression och vilken typ av problem den kan hjälpa oss att lösa.

Logistisk regression är en klassificeringsalgoritm som används för att tilldela observationer till en diskret uppsättning klasser. Några exempel på klassificeringsproblem är skräppost eller inte skräppost, bedrägeri eller inte bedrägeri vid online-transaktioner, malign eller godartad tumör. Logistisk regression omvandlar sitt resultat med hjälp av den logistiska sigmoidfunktionen för att returnera ett sannolikhetsvärde.
Vad är typerna av logistisk regression
- Binär (t.ex. tumör malign eller godartad)
- Multilinjära funktioner failsClass (t.ex. Cats, dogs or Sheep’s)
Logistisk regression
Logistisk regression är en algoritm för maskininlärning som används för klassificeringsproblem, det är en algoritm för prediktiv analys och bygger på begreppet sannolikhet.

Vi kan kalla en logistisk regression för en linjär regressionsmodell, men den logistiska regressionen använder en mer komplex kostnadsfunktion, denna kostnadsfunktion kan definieras som ”Sigmoid-funktionen” eller även känd som ”logistisk funktion” i stället för en linjär funktion.
Hypotesen för logistisk regression tenderar att begränsa kostnadsfunktionen mellan 0 och 1. Därför kan linjära funktioner inte representera den eftersom den kan ha ett värde som är större än 1 eller mindre än 0, vilket inte är möjligt enligt hypotesen för logistisk regression.
Vad är Sigmoid-funktionen?
För att kartlägga förutsagda värden till sannolikheter använder vi Sigmoid-funktionen. Funktionen mappar varje verkligt värde till ett annat värde mellan 0 och 1. Inom maskininlärning använder vi Sigmoid för att mappa förutsägelser till sannolikheter.


Hypotesrepresentation
När vi använder linjär regression använder vi en formel för hypotesen, dvs.
hΘ(x) = β₀ + β₁X
För logistisk regression kommer vi att modifiera den en liten bit.e.
σ(Z) = σ(β₀ + β₁X)
Vi har förväntat oss att vår hypotes ska ge värden mellan 0 och 1.
Z = β₀ + β₁X
hΘ(x) = sigmoid(Z)
dvs. hΘ(x) = 1/(1 + e^-(β₀ + β₁X)

Beslutningsgräns
Vi förväntar oss att vår klassificerare ska ge oss en uppsättning utdata eller klasser baserat på sannolikhet när vi skickar inmatningarna genom en prediktionsfunktion och returnerar ett sannolikhetsvärde mellan 0 och 1.
Till exempel har vi två klasser, låt oss ta dem som katter och hundar (1 – hund , 0 – katter). Vi bestämmer i princip med ett tröskelvärde över vilket vi klassificerar värden i klass 1 och om värdet går under tröskelvärdet klassificerar vi det i klass 2.
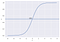
Som framgår av grafen ovan har vi valt ett tröskelvärde på 0,5. Om prediktionsfunktionen gav ett värde på 0,7 skulle vi klassificera observationen i klass 1 (hund). Om vår förutsägelse gav ett värde på 0,2 skulle vi klassificera observationen som klass 2(CAT).
Kostnadsfunktion
Vi lärde oss om kostnadsfunktionen J(θ) i den linjära regressionen, kostnadsfunktionen representerar optimeringsmålet dvs. vi skapar en kostnadsfunktion och minimerar den så att vi kan utveckla en korrekt modell med minsta möjliga fel.
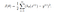
Om vi försöker använda kostnadsfunktionen för den linjära regressionen i ”logistisk regression” skulle den inte vara till någon nytta eftersom det skulle sluta med att den skulle bli en icke-konvex funktion med många lokala minimaler, där det skulle vara mycket svårt att minimera kostnadsvärdet och hitta det globala minimum.

För logistisk regression definieras kostnadsfunktionen som:
-log(hθ(x)) om y = 1
-log(1-hθ(x)) om y = 0

.