In diesem Blog werden wir die grundlegenden Konzepte der logistischen Regression besprechen und welche Art von Problemen wir damit lösen können.

Die logistische Regression ist ein Klassifizierungsalgorithmus, der verwendet wird, um Beobachtungen einer diskreten Menge von Klassen zuzuordnen. Einige Beispiele für Klassifizierungsprobleme sind E-Mail-Spam oder nicht Spam, Online-Transaktionen Betrug oder nicht Betrug, bösartiger oder gutartiger Tumor. Die logistische Regression transformiert ihre Ausgabe mithilfe der logistischen Sigmoidfunktion, um einen Wahrscheinlichkeitswert zurückzugeben.
Welche Arten von logistischer Regression gibt es
- Binär (z. B. Tumor bösartig oder gutartig)
- Multilineare Funktionen scheiternKlasse (z. B. Katzen, Hunde oder Schafe)
Logistische Regression
Die logistische Regression ist ein Algorithmus des maschinellen Lernens, der für Klassifizierungsprobleme verwendet wird. Es handelt sich um einen prädiktiven Analysealgorithmus, der auf dem Konzept der Wahrscheinlichkeit basiert.

Wir können eine logistische Regression als lineares Regressionsmodell bezeichnen, aber die logistische Regression verwendet eine komplexere Kostenfunktion, diese Kostenfunktion kann als „Sigmoidfunktion“ oder auch als „logistische Funktion“ anstelle einer linearen Funktion definiert werden.
Die Hypothese der logistischen Regression neigt dazu, die Kostenfunktion zwischen 0 und 1 zu begrenzen. Daher können lineare Funktionen sie nicht darstellen, da sie einen Wert größer als 1 oder kleiner als 0 haben kann, was gemäß der Hypothese der logistischen Regression nicht möglich ist.
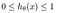
Was ist die Sigmoid-Funktion?
Um vorhergesagte Werte auf Wahrscheinlichkeiten abzubilden, verwenden wir die Sigmoid-Funktion. Die Funktion bildet jeden realen Wert auf einen anderen Wert zwischen 0 und 1 ab. Beim maschinellen Lernen verwenden wir Sigmoid, um Vorhersagen auf Wahrscheinlichkeiten abzubilden.


Hypothesendarstellung
Bei der linearen Regression haben wir eine Formel für die Hypothese verwendet, d.h.
hΘ(x) = β₀ + β₁X
Für die logistische Regression werden wir sie ein wenig modifizieren, d.h.d.
σ(Z) = σ(β₀ + β₁X)
Wir haben erwartet, dass unsere Hypothese Werte zwischen 0 und 1 ergeben wird.
Z = β₀ + β₁X
hΘ(x) = sigmoid(Z)
d.h. hΘ(x) = 1/(1 + e^-(β₀ + β₁X)

Entscheidungsgrenze
Wir erwarten von unserem Klassifikator, dass er uns eine Reihe von Ausgaben oder Klassen auf der Grundlage der Wahrscheinlichkeit liefert, wenn wir die Eingaben durch eine Vorhersagefunktion leiten und einen Wahrscheinlichkeitswert zwischen 0 und 1 zurückgeben.
Zum Beispiel: Wir haben 2 Klassen, nehmen wir sie als Katzen und Hunde (1 – Hund, 0 – Katzen). Wir entscheiden uns für einen Schwellenwert, über dem wir die Werte in Klasse 1 einordnen und wenn der Wert unter dem Schwellenwert liegt, ordnen wir ihn in Klasse 2 ein.
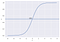
Wie im obigen Diagramm gezeigt, haben wir den Schwellenwert 0,5 gewählt. Wenn die Vorhersagefunktion einen Wert von 0,7 ergeben würde, würden wir diese Beobachtung als Klasse 1 (Hund) klassifizieren. Wenn unsere Vorhersage einen Wert von 0,2 ergibt, würden wir die Beobachtung als Klasse 2 (KAT) einstufen.
Kostenfunktion
Wir haben die Kostenfunktion J(θ) in der linearen Regression kennengelernt, die Kostenfunktion stellt ein Optimierungsziel dar, d. h. wir erstellen eine Kostenfunktion und minimieren sie, damit wir ein genaues Modell mit minimalem Fehler entwickeln können.
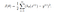
Wenn wir versuchen würden, die Kostenfunktion der linearen Regression in der ‚Logistischen Regression‘ zu verwenden, dann wäre sie unbrauchbar, da sie am Ende eine nicht-konvexe Funktion mit vielen lokalen Minima wäre, bei der es sehr schwierig wäre, den Kostenwert zu minimieren und das globale Minimum zu finden.

Für die logistische Regression ist die Kostenfunktion definiert als:
-log(hθ(x)) wenn y = 1
-log(1-hθ(x)) wenn y = 0
