- Podívejte se, proč je to tak úžasné.
- Vývoj počítačového vidění
- Jak dlouho trvá rozluštění obrazu
- Aplikace počítačového vidění
- Počítačové vidění v samořiditelných automobilech
- CV v rozpoznávání obličejů
- Počítačové vidění v rozšířené realitě &Smíšená realita
- CV ve zdravotnictví
- Problémy počítačového vidění
- Závěr
Podívejte se, proč je to tak úžasné.
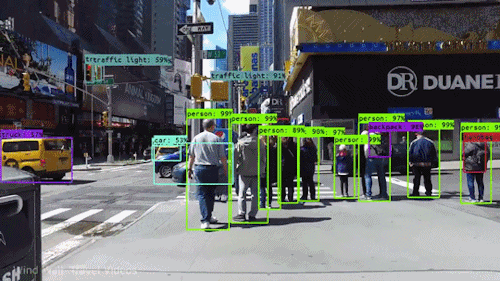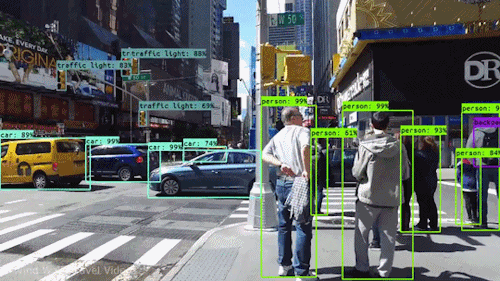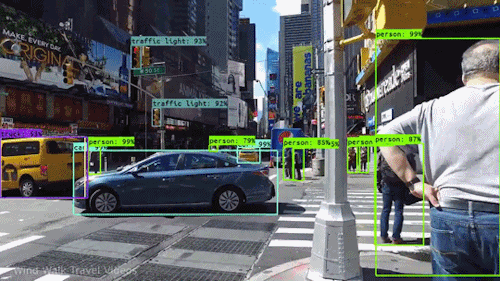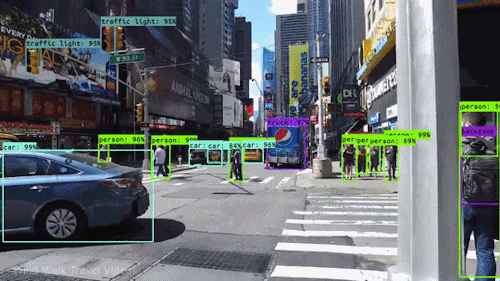
Jedním z nejmocnějších a nejpřitažlivějších typů umělé inteligence je počítačové vidění, se kterým jste se téměř jistě setkali v mnoha ohledech, aniž byste o tom věděli. Podívejte se, co to je, jak funguje a proč je tak úžasné (a bude se jen zlepšovat).
Počítačové vidění je obor informatiky, který se zaměřuje na replikaci části složitosti lidského zrakového systému a umožňuje počítačům identifikovat a zpracovávat objekty na obrázcích a videích stejným způsobem jako lidé. Až donedávna fungovalo počítačové vidění pouze v omezené míře.
Díky pokroku v oblasti umělé inteligence a inovacím v oblasti hlubokého učení a neuronových sítí dokázal tento obor v posledních letech udělat velký skok a v některých úlohách souvisejících s detekcí a označováním objektů dokázal překonat člověka.
Jedním z hnacích faktorů růstu počítačového vidění je množství dat, která dnes generujeme a která jsou následně využívána k trénování a zdokonalování počítačového vidění.

Společně s obrovským množstvím vizuálních dat (každý den jsou online sdíleny více než 3 miliardy obrázků) je nyní dostupný i výpočetní výkon potřebný k jejich analýze. S tím, jak se oblast počítačového vidění rozrůstá o nový hardware a algoritmy, roste i míra přesnosti identifikace objektů. Za méně než deset let dosáhly dnešní systémy z 50 % přesnosti 99 %, takže jsou při rychlé reakci na vizuální vstupy přesnější než člověk.
Počáteční experimenty v oblasti počítačového vidění začaly v 50. letech 20. století a v 70. letech bylo poprvé komerčně využito k rozlišení psaného textu od ručně psaného, dnes se aplikace počítačového vidění exponenciálně rozrostly.
Očekává se, že do roku 2022 dosáhne trh s počítačovým viděním a hardwarem 48,6 miliardy dolarů
Jednou z hlavních otevřených otázek v oblasti neurověd i strojového učení je: Jak přesně funguje náš mozek a jak se tomu můžeme přiblížit pomocí vlastních algoritmů? Skutečnost je taková, že existuje jen velmi málo funkčních a ucelených teorií mozkových výpočtů; takže navzdory tomu, že neuronové sítě mají „napodobovat způsob, jakým pracuje mozek“, nikdo si není zcela jistý, zda je to skutečně pravda.
Stejný paradox platí i pro počítačové vidění – protože nejsme rozhodnuti, jak mozek a oči zpracovávají obrazy, je těžké říci, jak dobře se algoritmy používané při výrobě přibližují našim vlastním vnitřním duševním procesům.
Na určité úrovni je počítačové vidění především o rozpoznávání vzorů. Jedním ze způsobů, jak vycvičit počítač, jak porozumět vizuálním datům, je tedy podat mu obrázky, spoustu obrázků, tisíce, pokud možno miliony, které byly označeny, a ty pak podrobit různým softwarovým technikám nebo algoritmům, které počítači umožní lovit vzory ve všech prvcích, které se vztahují k těmto označením.
Tak například, když nakrmíte počítač milionem obrázků koček (všichni je milujeme😄😹), podrobí je všechny algoritmům, které mu umožní analyzovat barvy na fotografii, tvary, vzdálenosti mezi tvary, místa, kde se objekty vzájemně ohraničují, a tak dále, takže identifikuje profil toho, co znamená „kočka“. Až bude počítač hotov, bude (teoreticky) schopen využít své zkušenosti, pokud mu budou podávány další neoznačené obrázky, a najít ty, které jsou kočičí.
Nechme naše chlupaté kočičí kamarády na chvíli stranou a pojďme se věnovat techničtějším věcem🤔😹. Níže je jednoduchá ilustrace vyrovnávací paměti pro obrázky ve stupních šedi, ve které je uložen náš obrázek Abrahama Lincolna. Jas každého pixelu je reprezentován jedním 8bitovým číslem, jehož rozsah je od 0 (černá) do 255 (bílá):

V podstatě jsou hodnoty pixelů na hardwarové úrovni téměř univerzálně uloženy v jednorozměrném poli. Například data z výše uvedeného obrázku jsou uložena podobně jako tento dlouhý seznam znaků bez znaménka:
{157, 153, 174, 168, 150, 152, 129, 151, 172, 161, 155, 156,
155, 182, 163, 74, 75, 62, 33, 17, 110, 210, 180, 154,
180, 180, 50, 14, 34, 6, 10, 33, 48, 106, 159, 181,
206, 109, 5, 124, 131, 111, 120, 204, 166, 15, 56, 180,
194, 68, 137, 251, 237, 239, 239, 228, 227, 87, 71, 201,
172, 105, 207, 233, 233, 214, 220, 239, 228, 98, 74, 206,
188, 88, 179, 209, 185, 215, 211, 158, 139, 75, 20, 169,
189, 97, 165, 84, 10, 168, 134, 11, 31, 62, 22, 148,
199, 168, 191, 193, 158, 227, 178, 143, 182, 106, 36, 190,
205, 174, 155, 252, 236, 231, 149, 178, 228, 43, 95, 234,
190, 216, 116, 149, 236, 187, 86, 150, 79, 38, 218, 241,
190, 224, 147, 108, 227, 210, 127, 102, 36, 101, 255, 224,
190, 214, 173, 66, 103, 143, 96, 50, 2, 109, 249, 215,
187, 196, 235, 75, 1, 81, 47, 0, 6, 217, 255, 211,
183, 202, 237, 145, 0, 0, 12, 108, 200, 138, 243, 236,
195, 206, 123, 207, 177, 121, 123, 200, 175, 13, 96, 218};
Tento způsob ukládání obrazových dat může být v rozporu s vaším očekáváním, protože při zobrazení se data jistě jeví jako dvourozměrná. Přesto tomu tak je, protože paměť počítače se jednoduše skládá ze stále se zvětšujícího lineárního seznamu adresních prostorů.

Vraťme se znovu k prvnímu obrázku a představme si, že přidáme barevný. Nyní se věci začínají komplikovat. Počítače obvykle čtou barvu jako sérii tří hodnot – červené, zelené a modré (RGB) – na stejné stupnici 0-255. V tomto případě se jedná o červenou, zelenou a modrou barvu. Nyní má každý pixel ve skutečnosti 3 hodnoty, které počítač ukládá kromě jeho polohy. Pokud bychom chtěli vybarvit prezidenta Lincolna, vedlo by to k získání 12 x 16 x 3 hodnot, tedy 576 čísel.

To je hodně paměti pro jeden obrázek a hodně pixelů pro iteraci algoritmu. Ale k natrénování modelu se smysluplnou přesností, zejména pokud mluvíme o hlubokém učení, byste obvykle potřebovali desítky tisíc obrázků, a čím více, tím lépe.
Vývoj počítačového vidění
Před příchodem hlubokého učení byly úlohy, které mohlo počítačové vidění provádět, velmi omezené a vyžadovaly mnoho ručního kódování a úsilí vývojářů a lidských operátorů. Pokud jste například chtěli provádět rozpoznávání obličeje, museli jste provést následující kroky:
- Vytvořit databázi:
- Anotovat snímky: Museli jste pořídit jednotlivé snímky všech subjektů, které jste chtěli sledovat, ve specifickém formátu: Pak byste museli u každého jednotlivého snímku zadat několik klíčových údajů, jako je vzdálenost mezi očima, šířka nosního můstku, vzdálenost mezi horním rtem a nosem a desítky dalších měření, která definují jedinečné vlastnosti každé osoby.
- Pořizování nových snímků: Dále byste museli zachytit nové snímky, ať už z fotografií nebo videoobsahu. A pak jste museli znovu projít procesem měření a označit klíčové body na snímku. Museli jste také zohlednit úhel, pod jakým byl snímek pořízen.
Po veškeré této ruční práci by aplikace nakonec byla schopna porovnat měření na novém snímku s měřeními uloženými v databázi a sdělit vám, zda odpovídá některému ze sledovaných profilů. Ve skutečnosti bylo automatizace velmi málo a většina práce se prováděla ručně. A chybovost byla stále velká.
Machine learning poskytl jiný přístup k řešení problémů počítačového vidění. Díky strojovému učení již vývojáři nemuseli ručně kódovat každé pravidlo do svých aplikací pro vidění. Místo toho naprogramovali „funkce“, menší aplikace, které dokázaly detekovat specifické vzory v obrazech. Poté použili algoritmus statistického učení, jako je lineární regrese, logistická regrese, rozhodovací stromy nebo podpůrné vektorové stroje (SVM), k detekci vzorů a klasifikaci obrazů a detekci objektů v nich.
Strojové učení pomohlo vyřešit mnoho problémů, které byly historicky náročné pro klasické nástroje a přístupy k vývoji softwaru. Před lety se například inženýrům zabývajícím se strojovým učením podařilo vytvořit software, který dokázal předpovědět okna pro přežití rakoviny prsu lépe než lidští odborníci. Vytvoření funkcí tohoto softwaru však vyžadovalo úsilí desítek inženýrů a odborníků na rakovinu prsu a jeho vývoj zabral mnoho času.
Hluboké učení poskytlo zásadně odlišný přístup k provádění strojového učení. Hluboké učení se opírá o neuronové sítě, což je univerzální funkce, která dokáže vyřešit jakýkoli problém reprezentovatelný pomocí příkladů. Když neuronové síti poskytnete mnoho označených příkladů určitého druhu dat, bude schopna extrahovat společné vzorce mezi těmito příklady a transformovat je do matematické rovnice, která pomůže klasifikovat budoucí informace.
Například vytvoření aplikace pro rozpoznávání obličejů pomocí hlubokého učení vyžaduje pouze vyvinout nebo vybrat předem sestavený algoritmus a trénovat jej pomocí příkladů obličejů lidí, které musí rozpoznat. Při dostatečném množství příkladů (hodně příkladů) bude neuronová síť schopna detekovat obličeje bez dalších instrukcí týkajících se funkcí nebo měření.
Hluboké učení je velmi efektivní metoda pro počítačové vidění. Ve většině případů spočívá vytvoření dobrého algoritmu hlubokého učení ve shromáždění velkého množství označených trénovacích dat a vyladění parametrů, jako je typ a počet vrstev neuronové sítě a trénovacích epoch. Ve srovnání s předchozími typy strojového učení je vývoj a nasazení hlubokého učení jednodušší i rychlejší.
Většina současných aplikací počítačového vidění, jako je detekce rakoviny, samořídící auta a rozpoznávání obličejů, využívá hluboké učení. Hluboké učení a hluboké neuronové sítě se díky dostupnosti a pokroku v oblasti hardwaru a cloudových výpočetních zdrojů přesunuly z konceptuální sféry do praktických aplikací.
Jak dlouho trvá rozluštění obrazu
Zkrátka nic moc. To je klíč k tomu, proč je počítačové vidění tak vzrušující: Zatímco v minulosti mohlo i superpočítačům trvat dny, týdny nebo dokonce měsíce, než zvládly všechny potřebné výpočty, díky dnešním ultrarychlým čipům a souvisejícímu hardwaru a rychlému a spolehlivému internetu a cloudovým sítím je tento proces bleskový. Jedním z rozhodujících faktorů je ochota mnoha velkých společností zabývajících se výzkumem umělé inteligence sdílet svou práci Facebook, Google, IBM a Microsoft, zejména tím, že otevřely některé své práce v oblasti strojového učení.
To umožňuje ostatním navázat na jejich práci, místo aby začínali od nuly. Výsledkem je, že odvětví umělé inteligence vaří z vody a experimenty, které ještě nedávno trvaly týdny, dnes mohou trvat 15 minut. A u mnoha reálných aplikací počítačového vidění probíhá celý tento proces nepřetržitě v mikrosekundách, takže počítač dnes dokáže být tím, čemu vědci říkají „situačně uvědomělý“.
Aplikace počítačového vidění
Počítačové vidění je jednou z oblastí strojového učení, kde jsou základní koncepty již integrovány do hlavních produktů, které denně používáme.
Počítačové vidění v samořiditelných automobilech
Nejsou to však jen technologické společnosti, které využívají strojové učení pro obrazové aplikace.
Počítačové vidění umožňuje samořiditelným automobilům vnímat své okolí. Kamery snímají video z různých úhlů v okolí vozu a předávají je softwaru pro počítačové vidění, který pak v reálném čase zpracovává obraz, aby našel krajní body silnic, přečetl dopravní značky, detekoval jiná auta, objekty a chodce. Samořízené auto pak může řídit svou cestu po ulicích a dálnicích, vyhýbat se nárazům do překážek a (doufejme) bezpečně dovézt své cestující do cíle.
Počítačové vidění hraje důležitou roli také v aplikacích pro rozpoznávání obličejů, což je technologie, která umožňuje počítačům porovnávat obrazy obličejů lidí s jejich identitou. Algoritmy počítačového vidění detekují rysy obličeje na snímcích a porovnávají je s databázemi profilů obličejů. Spotřebitelská zařízení používají rozpoznávání obličeje k ověřování totožnosti svých majitelů. Aplikace sociálních médií používají rozpoznávání obličeje k detekci a označování uživatelů. Na technologii rozpoznávání obličejů se spoléhají také orgány činné v trestním řízení při identifikaci zločinců ve videozáznamech.
Počítačové vidění v rozšířené realitě &Smíšená realita
Počítačové vidění hraje důležitou roli také v rozšířené a smíšené realitě, technologii, která umožňuje počítačovým zařízením, jako jsou chytré telefony, tablety a chytré brýle, překrývat a vkládat virtuální objekty do obrazů reálného světa. Zařízení pro rozšířenou realitu pomocí počítačového vidění detekují objekty v reálném světě, aby určila místa na displeji zařízení pro umístění virtuálního objektu. Algoritmy počítačového vidění mohou například pomoci aplikacím AR detekovat roviny, jako jsou desky stolů, stěny a podlahy, což je velmi důležitá součást určení hloubky a rozměrů a umístění virtuálních objektů do fyzického světa.
CV ve zdravotnictví
Počítačové vidění je také důležitou součástí pokroku v oblasti zdravotnických technologií. Algoritmy počítačového vidění mohou pomoci automatizovat úlohy, jako je odhalování rakovinných znamének na snímcích kůže nebo vyhledávání příznaků na rentgenových snímcích a snímcích magnetické rezonance.
Problémy počítačového vidění
Pomoci počítačům vidět se ukazuje jako velmi obtížné.
Vymyslet stroj, který by viděl jako my, je ošidně obtížný úkol nejen proto, že je těžké přimět počítače, aby to dělaly, ale také proto, že si nejsme zcela jisti, jak lidské vidění vůbec funguje.
Studium biologického vidění vyžaduje pochopení orgánů vnímání, jako jsou oči, a také interpretaci vjemů v mozku. Bylo dosaženo velkého pokroku, a to jak při mapování tohoto procesu, tak z hlediska objevování triků a zkratek, které systém používá, i když jako u každého studia, které zahrnuje mozek, je před námi ještě dlouhá cesta.

Mnoho populárních aplikací počítačového vidění zahrnuje snahu rozpoznávat věci na fotografiích; například:
- Klasifikace objektů:
- Identifikace objektu: Jaká široká kategorie objektu je na této fotografii? Který typ daného objektu je na této fotografii?
- Ověření objektu: Je daný objekt na fotografii?
- Detekce objektu: Kde jsou objekty na fotografii?
- Detekce orientačních bodů objektu:
- Segmentace objektu: Jaké jsou klíčové body objektu na fotografii?
- Rozpoznávání objektů: Jaké pixely patří k objektu na snímku? Jaké objekty jsou na této fotografii a kde se nacházejí?
Mezi další metody analýzy patří:
- Analýza pohybu videa využívá počítačové vidění k odhadu rychlosti objektů ve videu nebo samotné kamery.
- Při segmentaci obrazu algoritmy rozdělují obrazy na více sad pohledů.
- Rekonstrukce scény vytváří 3D model scény zadaný prostřednictvím snímků nebo videa.
- Při obnově obrazu se z fotografií odstraňuje šum, například rozmazání, pomocí filtrů založených na strojovém učení.
Jakoukoli jinou aplikaci, která zahrnuje porozumění pixelům prostřednictvím softwaru, lze bezpečně označit jako počítačové vidění.
Závěr
Přes nedávný pokrok, který je impozantní, stále nejsme ani blízko vyřešení počítačového vidění. Existuje však již řada zdravotnických institucí a podniků, které našly způsoby, jak aplikovat systémy CV, poháněné CNN, na problémy reálného světa. A tento trend se pravděpodobně v dohledné době nezastaví.
Pokud se chcete ozvat a mimochodem znáte dobrý vtip, můžete se se mnou spojit na Twitteru nebo LinkedIn.
Díky za přečtení!😄 🙌