Tässä näet, miksi se on niin mahtavaa.
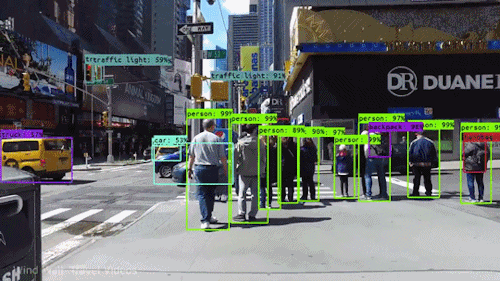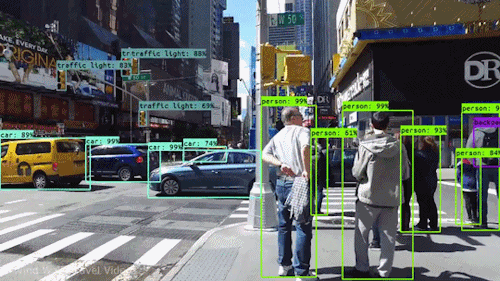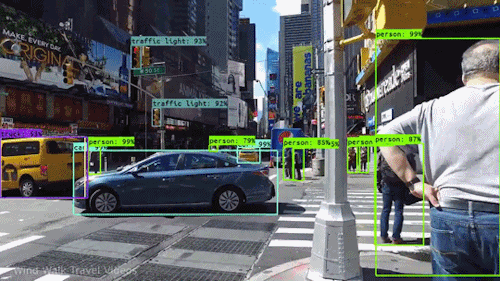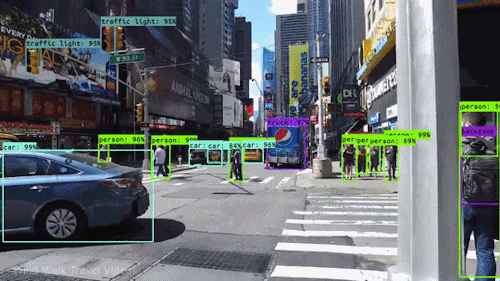
Yksi tehokkaimmista ja kiehtovimmista tekoälyn lajeista on tietokonenäkö, jonka olet lähes varmasti kokenut millä tahansa tavalla tietämättäsi. Tässä on katsaus siihen, mitä se on, miten se toimii ja miksi se on niin mahtavaa (ja tulee vain paranemaan).
Tietokonenäkö on tietojenkäsittelytieteen ala, joka keskittyy jäljittelemään osia ihmisen näköjärjestelmän monimutkaisuudesta ja mahdollistamaan sen, että tietokoneet pystyvät tunnistamaan ja käsittelemään kuvissa ja videoissa olevia kohteita samalla tavalla kuin ihmiset. Viime aikoihin asti tietokonenäkö on toiminut vain rajoitetusti.
Tekoälyn kehittymisen sekä syväoppimiseen ja neuroverkkoihin liittyvien innovaatioiden ansiosta ala on ottanut viime vuosina suuria harppauksia ja pystynyt ohittamaan ihmisen joissakin kohteiden havaitsemiseen ja merkitsemiseen liittyvissä tehtävissä.
Yksi tietokonenäön kasvun taustatekijöistä on nykyisin tuottamamme datan määrä, jota sitten käytetään tietokonenäön harjoitteluun ja parantamiseen.

Visuaalisen datan valtavan määrän (verkossa jaetaan päivittäin yli 3 miljardia kuvaa) ohella myös datan analysoinnissa tarvittava laskentateho on nykyään saatavilla. Kun tietokonenäköala on kasvanut uusien laitteistojen ja algoritmien myötä, myös kohteiden tunnistamisen tarkkuus on kasvanut. Vajaassa vuosikymmenessä nykyiset järjestelmät ovat saavuttaneet 99 prosentin tarkkuuden 50 prosentista, mikä tekee niistä tarkempia kuin ihmisistä, jotka pystyvät reagoimaan nopeasti visuaalisiin syötteisiin.
Tietokonenäön varhaiset kokeilut alkoivat 1950-luvulla, ja sitä käytettiin ensimmäisen kerran kaupallisesti koneella kirjoitetun ja käsin kirjoitetun tekstin erottamiseen 1970-luvulla, ja nykyään tietokonenäön sovellukset ovat kasvaneet räjähdysmäisesti.
Vuoteen 2022 mennessä tietokonenäkö- ja laitteistomarkkinoiden odotetaan nousevan 48,6 miljardiin dollariin
Yksi tärkeimmistä avoimista kysymyksistä sekä neurotieteen että koneoppimisen alalla on: Miten aivomme tarkalleen ottaen toimivat, ja miten voimme approksimoida sitä omilla algoritmeillamme? Todellisuudessa aivojen laskennasta on hyvin vähän toimivia ja kattavia teorioita; joten huolimatta siitä, että neuroverkkojen oletetaan ”jäljittelevän aivojen toimintatapaa”, kukaan ei ole aivan varma, pitääkö se todella paikkansa.
Sama paradoksi pätee myös tietokonenäköön – koska emme ole päättäneet, miten aivot ja silmät käsittelevät kuvia, on vaikea sanoa, kuinka hyvin tuotannossa käytettävät algoritmit lähentelevät omia sisäisiä henkisiä prosessejamme.
Tietyllä tasolla tietokonenäkössä on kyse hahmontunnistuksesta. Yksi tapa kouluttaa tietokonetta ymmärtämään visuaalista dataa on syöttää sille kuvia, paljon kuvia, tuhansia, miljoonia, jos mahdollista, jotka on merkitty, ja sitten altistaa ne erilaisille ohjelmistotekniikoille tai algoritmeille, joiden avulla tietokone voi etsiä kuvioita kaikista elementeistä, jotka liittyvät näihin merkintöihin.
Jos tietokoneelle syötetään esimerkiksi miljoona kuvaa kissoista (me kaikki rakastamme niitä😄😹), se alistaa ne kaikki algoritmeille, joiden avulla se voi analysoida kuvan värejä, muotoja, muotojen välisiä etäisyyksiä, sitä, missä kohteet rajautuvat toisiinsa, ja niin edelleen, jotta se tunnistaa profiilin siitä, mitä ”kissa” tarkoittaa. Kun se on valmis, tietokone pystyy (teoriassa) käyttämään kokemustaan, jos sille syötetään muita merkitsemättömiä kuvia, löytääkseen ne, joissa on kissa.
Jättäkäämme pörröiset kissaystävämme hetkeksi sivuun ja mennään teknisempään🤔😹. Alla on yksinkertainen havainnollistus harmaasävykuvapuskurista, joka tallentaa Abraham Lincolnin kuvamme. Kunkin pikselin kirkkautta edustaa yksi 8-bittinen luku, jonka vaihteluväli on 0:sta (musta) 255:een (valkoinen):

Pikselien arvot tallennetaan lähes yleisesti laitteistotasolla yksiulotteiseen joukkoon. Esimerkiksi yllä olevan kuvan tiedot on tallennettu samalla tavalla kuin tämä pitkä lista merkitsemättömiä merkkejä:
{157, 153, 174, 168, 150, 152, 129, 151, 172, 161, 155, 156,
155, 182, 163, 74, 75, 62, 33, 17, 110, 210, 180, 154,
180, 180, 50, 14, 34, 6, 10, 33, 48, 106, 159, 181,
206, 109, 5, 124, 131, 111, 120, 204, 166, 15, 56, 180,
194, 68, 137, 251, 237, 239, 239, 228, 227, 87, 71, 201,
172, 105, 207, 233, 233, 214, 220, 239, 228, 98, 74, 206,
188, 88, 179, 209, 185, 215, 211, 158, 139, 75, 20, 169,
189, 97, 165, 84, 10, 168, 134, 11, 31, 62, 22, 148,
199, 168, 191, 193, 158, 227, 178, 143, 182, 106, 36, 190,
205, 174, 155, 252, 236, 231, 149, 178, 228, 43, 95, 234,
190, 216, 116, 149, 236, 187, 86, 150, 79, 38, 218, 241,
190, 224, 147, 108, 227, 210, 127, 102, 36, 101, 255, 224,
190, 214, 173, 66, 103, 143, 96, 50, 2, 109, 249, 215,
187, 196, 235, 75, 1, 81, 47, 0, 6, 217, 255, 211,
183, 202, 237, 145, 0, 0, 12, 108, 200, 138, 243, 236,
195, 206, 123, 207, 177, 121, 123, 200, 175, 13, 96, 218};
Tämä tapa tallentaa kuvadataa saattaa olla vastoin odotuksiasi, sillä tiedot näyttävät varmasti kaksiulotteisilta, kun niitä näytetään. Näin kuitenkin on, sillä tietokoneen muisti koostuu yksinkertaisesti yhä kasvavasta lineaarisesta listasta osoiteavaruuksia.

Palaamme taas ensimmäiseen kuvaan ja kuvittelemme, että lisäämme siihen värillisen kuvan. Nyt asiat alkavat muuttua monimutkaisemmiksi. Tietokoneet lukevat väriä yleensä kolmen arvon – punaisen, vihreän ja sinisen (RGB) – sarjana samalla 0-255 asteikolla. Nyt jokaisella pikselillä on itse asiassa kolme arvoa, jotka tietokone tallentaa sen sijainnin lisäksi. Jos värittäisimme presidentti Lincolnin, se johtaisi 12 x 16 x 3 arvoon eli 576 numeroon.

Tässä on paljon muistia vaadittavaa yhteen kuvaan, ja paljon pikseleitä algoritmille iteroitavaksi. Mutta mallin kouluttamiseen mielekkäällä tarkkuudella, varsinkin kun puhutaan syväoppimisesta, tarvitaan yleensä kymmeniä tuhansia kuvia, ja mitä enemmän, sitä parempi.
Tietokonenäön kehitys
Vor syväoppimisen tuloa tietokonenäön tehtävät, joita tietokonenäkö pystyi suorittamaan, olivat hyvin rajallisia ja vaativat paljon manuaalista koodausta ja kehittäjien ja ihmisoperaattoreiden työtä. Jos esimerkiksi halusit suorittaa kasvojentunnistuksen, sinun täytyi suorittaa seuraavat vaiheet:
- Luo tietokanta: Sinun piti ottaa yksittäisiä kuvia kaikista kohteista, joita halusit seurata, tietyssä muodossa.
- Merkitse kuvat: Sitten jokaiseen yksittäiseen kuvaan piti syöttää useita avaintietoja, kuten silmien välinen etäisyys, nenäsillan leveys, ylähuulen ja nenän välinen etäisyys ja kymmeniä muita mittauksia, jotka määrittelevät kunkin henkilön ainutlaatuiset ominaisuudet.
- Ota uusia kuvia: Seuraavaksi sinun olisi otettava uusia kuvia, joko valokuvista tai videosisällöstä. Ja sitten sinun piti käydä mittausprosessi läpi uudelleen merkitsemällä kuvaan avainkohdat. Sinun piti myös ottaa huomioon kuvakulma, josta kuva otettiin.
Kaiken tämän manuaalisen työn jälkeen sovellus pystyi lopulta vertaamaan uuden kuvan mittauksia tietokantaansa tallennettuihin mittauksiin ja kertomaan, vastasiko se jotakin seurannassaan olevista profiileista. Itse asiassa automatisointi oli hyvin vähäistä, ja suurin osa työstä tehtiin manuaalisesti. Ja virhemarginaali oli edelleen suuri.
Koneoppiminen tarjosi erilaisen lähestymistavan tietokonenäön ongelmien ratkaisemiseen. Koneoppimisen avulla kehittäjien ei enää tarvinnut manuaalisesti koodata jokaista sääntöä visiosovelluksiinsa. Sen sijaan he ohjelmoivat ”ominaisuuksia”, pienempiä sovelluksia, jotka pystyivät havaitsemaan tiettyjä kuvien kuvioita. Sen jälkeen he käyttivät tilastollista oppimisalgoritmia, kuten lineaarista regressiota, logistista regressiota, päätöspuita tai tukivektorikoneita (SVM), havaitakseen kuvioita ja luokitellakseen kuvia ja havaitakseen niissä olevia kohteita.
Koneoppiminen auttoi ratkaisemaan monia ongelmia, jotka olivat historiallisesti haastavia klassisille ohjelmistokehitystyökaluille ja -menetelmille. Esimerkiksi vuosia sitten koneoppimisinsinöörit pystyivät luomaan ohjelmiston, joka pystyi ennustamaan rintasyövän selviytymisikkunoita paremmin kuin ihmisasiantuntijat. Ohjelmiston ominaisuuksien rakentaminen vaati kuitenkin kymmenien insinöörien ja rintasyöpäasiantuntijoiden panosta ja vei paljon aikaa.
Syväluotaava oppiminen (engl. ”deep learning”)
Pitkäluotaava oppiminen (engl. ”deep learning”)
tarjosi perustavanlaatuisesti toisenlaisen lähestymistavan koneoppimiseen. Syväoppiminen perustuu neuroverkkoihin, yleiskäyttöisiin funktioihin, jotka voivat ratkaista minkä tahansa esimerkkien avulla esitettävissä olevan ongelman. Kun neuroverkolle annetaan monia merkittyjä esimerkkejä tietyntyyppisestä datasta, se pystyy poimimaan yhteisiä malleja näiden esimerkkien väliltä ja muuntamaan ne matemaattiseksi yhtälöksi, joka auttaa luokittelemaan tulevia tietopaloja.
Esimerkiksi kasvontunnistussovelluksen luominen syväoppimisen avulla edellyttää vain, että kehität tai valitset valmiiksi laaditun algoritmin ja harjoittelet sitä esimerkeillä ihmisten kasvoista, jotka sen on tunnistettava. Kun annetaan tarpeeksi esimerkkejä (paljon esimerkkejä), neuroverkko pystyy tunnistamaan kasvot ilman lisäohjeita ominaisuuksista tai mittauksista.
Syväoppiminen on erittäin tehokas menetelmä tietokonenäön tekemiseen. Useimmissa tapauksissa hyvän syväoppimisalgoritmin luomisessa on kyse suuren määrän leimattua harjoitusdataa keräämisestä ja parametrien, kuten neuroverkkojen tyyppien ja kerrosten lukumäärän sekä harjoitusepookkien, virittämisestä. Verrattuna aiempiin koneoppimisen tyyppeihin syväoppiminen on sekä helpompaa että nopeampaa kehittää ja ottaa käyttöön.
Useimmissa nykyisissä tietokonenäön sovelluksissa, kuten syövän havaitsemisessa, itseajavissa autoissa ja kasvojentunnistuksessa, käytetään syväoppimista. Syväoppiminen ja syvät neuroverkot ovat siirtyneet käsitteellisestä alueesta käytännön sovelluksiin laitteistojen ja pilvilaskentaresurssien saatavuuden ja kehityksen ansiosta.
Kuinka kauan kestää kuvan tulkitseminen
Lyhyesti sanottuna ei paljon. Tämä on avain siihen, miksi tietokonenäkö on niin jännittävää: Aikaisemmin jopa supertietokoneilta saattoi kulua päiviä, viikkoja tai jopa kuukausia kaikkien tarvittavien laskutoimitusten suorittamiseen, mutta nykypäivän huippunopeat sirut ja niihin liittyvät laitteistot sekä nopea ja luotettava internet ja pilvipalveluverkot tekevät prosessista salamannopean. Eräänä ratkaisevana tekijänä on ollut monien tekoälytutkimusta tekevien suurten yritysten halukkuus jakaa työtään Facebook, Google, IBM ja Microsoft, jotka ovat avanneet joitakin koneoppimistöitään avoimen lähdekoodin avulla.
Tämä antaa muille mahdollisuuden rakentaa työnsä varaan sen sijaan, että ne aloittaisivat tyhjästä. Tämän seurauksena tekoälyteollisuus kiehuu eteenpäin, ja kokeet, joiden suorittaminen vielä jokin aika sitten kesti viikkoja, saattavat nykyään kestää 15 minuuttia. Ja monissa tietokonenäön reaalimaailman sovelluksissa tämä kaikki prosessi tapahtuu jatkuvasti mikrosekunneissa, joten tietokone pystyy nykyään olemaan, mitä tutkijat kutsuvat ”tilannetietoiseksi”.
Tietokonenäön sovellukset
Tietokonenäkö on yksi koneoppimisen osa-alueista, jonka keskeisiä käsitteitä integroidaan jo nyt tärkeisiin tuotteisiin, joita käytämme päivittäin.
Tietokonenäkö itsestään ajavissa autoissa
Mutta eivät vain teknologiayritykset hyödynnä koneoppimista kuvasovelluksissa.
Tietokonenäön avulla itsestään ajavat autot pystyvät hahmottamaan ympäristöään. Kamerat kaappaavat videokuvaa eri kulmista auton ympäriltä ja syöttävät sen tietokonenäköohjelmistolle, joka sitten käsittelee kuvia reaaliaikaisesti löytääkseen teiden ääripäitä, lukeakseen liikennemerkkejä, havaitakseen muita autoja, esineitä ja jalankulkijoita. Itsestään ajava auto voi sitten ohjata tiensä kaduilla ja valtateillä, välttää törmäämästä esteisiin ja (toivottavasti) kuljettaa matkustajansa turvallisesti määränpäähänsä.
CV kasvojentunnistuksessa
Tietokonenäköllä on tärkeä rooli myös kasvojentunnistussovelluksissa, eli teknologiassa, jonka avulla tietokoneet pystyvät sovittamaan ihmisten kasvojen kuvat yhteen heidän henkilöllisyytensä kanssa. Tietokonenäköalgoritmit havaitsevat kuvien kasvonpiirteet ja vertaavat niitä kasvoprofiilien tietokantoihin. Kuluttajalaitteet käyttävät kasvojentunnistusta omistajiensa henkilöllisyyden todentamiseen. Sosiaalisen median sovellukset käyttävät kasvojentunnistusta käyttäjien tunnistamiseen ja merkitsemiseen. Myös lainvalvontaviranomaiset tukeutuvat kasvontunnistustekniikkaan rikollisten tunnistamiseksi videosyötteistä.
CV lisätyssä todellisuudessa & sekatodellisuudessa
Tietokonenäköllä on tärkeä rooli myös lisätyssä ja sekatodellisuudessa, eli teknologiassa, jonka avulla tietokonelaitteilla, kuten älypuhelimilla, tablet-laitteilla ja älylaseilla, voidaan päällekkäin sijoittaa virtuaalisia objekteja ja upottaa niitä reaalimaailman kuvien päälle. Tietokonenäön avulla AR-vaihteet havaitsevat reaalimaailman kohteet, jotta laitteen näytöllä voidaan määrittää paikat, joihin virtuaalinen objekti voidaan sijoittaa. Tietokonenäköalgoritmit voivat esimerkiksi auttaa AR-sovelluksia havaitsemaan pöytätasojen, seinien ja lattioiden kaltaisia tasoja, mikä on erittäin tärkeä osa syvyyden ja mittasuhteiden määrittämistä ja virtuaalisten objektien sijoittamista fyysiseen maailmaan.
CV terveydenhuollossa
Tietokonenäkö on myös ollut tärkeä osa terveydenhuollon teknologian edistymistä. Tietokonenäköalgoritmit voivat auttaa automatisoimaan tehtäviä, kuten syöpämutkien havaitsemista ihokuvista tai oireiden löytämistä röntgen- ja magneettikuvauksista.
Tietokonenäön haasteet
Tietokoneiden auttaminen näkemään osoittautuu hyvin vaikeaksi.
Keksiä kone, joka näkee kuten me, on petollisen vaikea tehtävä, ei vain siksi, että tietokoneita on vaikea saada tekemään sitä, vaan myös siksi, että emme ole täysin varmoja siitä, miten ihmisen näkökyky ylipäätään toimii.
Biologisen näkemisen tutkiminen edellyttää ymmärrystä havaintoelimistä, kuten silmistä, sekä havaintojen tulkinnasta aivoissa. Mike Tamir
Monissa suosituissa tietokonenäön sovelluksissa yritetään tunnistaa asioita valokuvista; esimerkiksi:
- Objektien luokittelu:
- Kohteen tunnistaminen: Minkä tyyppinen tietty kohde on tässä valokuvassa?
- Kohteen todentaminen: Onko kohde kuvassa?
- Kohteen havaitseminen: Missä kohteet ovat valokuvassa?
- Kohteen maamerkkien havaitseminen: Mitkä ovat valokuvan kohteen avainkohdat?
- Kohteen segmentointi: Mitkä pikselit kuuluvat kuvassa olevaan kohteeseen?
- Kohteen tunnistaminen: Mitä kohteita tässä valokuvassa on ja missä ne ovat?
Pelkän tunnistamisen lisäksi muita analyysimenetelmiä ovat:
- Videon liikeanalyysi käyttää tietokonenäköä arvioimaan videon kohteiden tai itse kameran nopeutta.
- Kuvan segmentoinnissa algoritmit jakavat kuvat useisiin näkymäsarjoihin.
- Kuvan rekonstruktio luo 3D-mallin kuvien tai videon avulla syötetystä kohtauksesta.
- Kuvan restauroinnissa kuvista poistetaan kohinaa, kuten epätarkkuutta, koneoppimiseen perustuvilla suodattimilla.
Mitä tahansa muuta sovellusta, johon liittyy pikseleiden ymmärtäminen ohjelmistojen avulla, voidaan turvallisesti leimata tietokonenäköksi.
Johtopäätös
Viimeaikaisesta edistyksestä huolimatta, joka on ollut vaikuttavaa, emme ole vieläkään lähelläkään tietokonenäön ratkaisua. On kuitenkin jo useita terveydenhuollon laitoksia ja yrityksiä, jotka ovat löytäneet keinoja soveltaa CNN:ien käyttämiä CV-järjestelmiä reaalimaailman ongelmiin. Eikä tämä suuntaus todennäköisesti pysähdy lähiaikoina.
Jos haluat ottaa yhteyttä ja muuten tiedät hyvän vitsin, voit olla minuun yhteydessä Twitterissä tai LinkedInissä.
Kiitos lukemisesta!😄 🙌