- Nézd meg, miért olyan félelmetes.
- A számítógépes látás fejlődése
- How Long Does It Take It Take To Decipher An Image
- A számítógépes látás alkalmazásai
- CV az önvezető autókban
- CV az arcfelismerésben
- CV a kiterjesztett valóságban & vegyes valóság
- CV az egészségügyben
- A számítógépes látás kihívásai
- Következtetés
Nézd meg, miért olyan félelmetes.
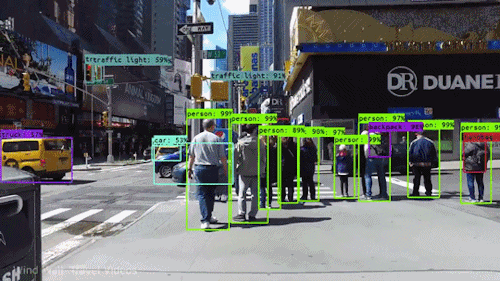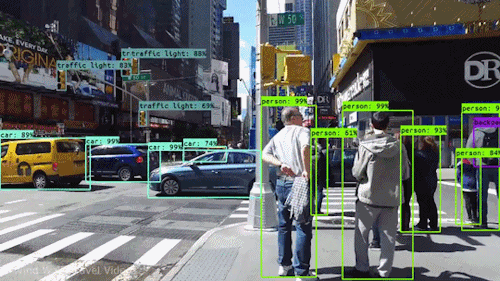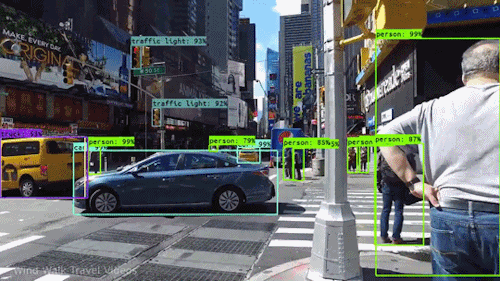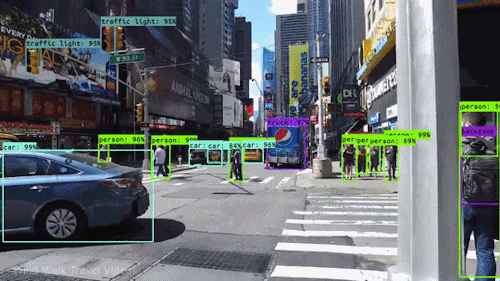
A mesterséges intelligencia egyik legerősebb és legmeggyőzőbb fajtája a számítógépes látás, amelyet szinte biztos, hogy már számtalan módon megtapasztaltál anélkül, hogy tudtad volna. Itt megnézzük, mi ez, hogyan működik, és miért olyan félelmetes (és csak egyre jobb lesz).
A számítógépes látás a számítástechnikának az a területe, amely az emberi látórendszer komplexitásának egyes részeinek másolására összpontosít, és lehetővé teszi a számítógépek számára, hogy az emberekhez hasonlóan azonosítsák és feldolgozzák a képeken és videókon lévő objektumokat. A közelmúltig a számítógépes látás csak korlátozottan működött.
A mesterséges intelligencia fejlődésének, valamint a mélytanulás és a neurális hálózatok terén elért újításoknak köszönhetően a terület az elmúlt években nagyot tudott ugrani, és képes volt megelőzni az embert néhány, az objektumok felismerésével és címkézésével kapcsolatos feladatban.
A számítógépes látás növekedésének egyik mozgatórugója a napjainkban keletkező adatmennyiség, amelyet aztán a számítógépes látás betanítására és tökéletesítésére használunk fel.

Az óriási mennyiségű vizuális adat mellett (naponta több mint 3 milliárd képet osztanak meg online) ma már elérhető az adatok elemzéséhez szükséges számítási teljesítmény is. Ahogy a számítógépes látás területe új hardverekkel és algoritmusokkal bővült, úgy nőtt a tárgyak azonosításának pontossági aránya is. Kevesebb mint egy évtized alatt a mai rendszerek 50 százalékról 99 százalékos pontosságot értek el, ami az embernél pontosabbá teszi őket a vizuális inputokra való gyors reagálásban.
A számítógépes látással kapcsolatos korai kísérletek az 1950-es években kezdődtek, és az 1970-es években alkalmazták először kereskedelmi célokra a gépelt és a kézzel írt szöveg megkülönböztetésére, mára a számítógépes látás alkalmazásai exponenciálisan nőttek.
2022-re a számítógépes látás és a hardverek piaca várhatóan eléri a 48,6 milliárd dollárt
Az idegtudomány és a gépi tanulás egyik legfontosabb nyitott kérdése egyaránt az, hogy pontosan hogyan működik az agyunk, és hogyan tudjuk ezt saját algoritmusainkkal megközelíteni. A valóság az, hogy nagyon kevés működő és átfogó elmélet létezik az agyi számításokról; így annak ellenére, hogy a neurális hálók állítólag “utánozzák az agy működését”, senki sem tudja biztosan, hogy ez valóban így van-e.
Ugyanez a paradoxon igaz a számítógépes látásra is – mivel nem döntöttük el, hogyan dolgozza fel az agy és a szem a képeket, nehéz megmondani, hogy a gyártásban használt algoritmusok mennyire közelítik meg a saját belső mentális folyamatainkat.
Egy bizonyos szinten a számítógépes látás a mintafelismerésről szól. Tehát egy számítógépet úgy lehet betanítani a vizuális adatok megértésére, hogy képeket, sok-sok képet, lehetőleg ezreket, milliókat etetünk vele, amelyeket megjelöltek, majd ezeket különböző szoftveres technikáknak vagy algoritmusoknak vetjük alá, amelyek lehetővé teszik a számítógép számára, hogy mintákat keressen az összes olyan elemben, amelyek a címkékhez kapcsolódnak.
Így például, ha egy számítógépet milliónyi macskaképpel etetünk meg (mindannyian szeretjük őket😄😹), akkor a számítógép az összeset olyan algoritmusoknak veti alá, amelyek lehetővé teszik, hogy elemezze a képen lévő színeket, a formákat, a formák közötti távolságokat, azt, hogy hol határolják egymást a tárgyak, és így tovább, így azonosít egy profilt arról, hogy mit jelent a “macska”. Ha ezzel végzett, a számítógép (elméletileg) képes lesz arra, hogy a tapasztalatait felhasználva, ha más címkézetlen képekkel etetik, megtalálja azokat, amelyeken macska szerepel.
Hagyjuk egy pillanatra félre bolyhos macskabarátainkat, és térjünk át a technikára🤔😹. Az alábbiakban egy egyszerű illusztráció a szürkeárnyalatos képpufferről, amely Abraham Lincoln képünket tárolja. Minden egyes pixel fényerejét egyetlen 8 bites számmal ábrázoljuk, amelynek tartománya 0 (fekete) és 255 (fehér) között van:

A pixelértékeket hardveres szinten szinte mindenhol egydimenziós tömbben tárolják. Például a fenti kép adatait ehhez az előjel nélküli karakterek hosszú listájához hasonló módon tárolják:
{157, 153, 174, 168, 150, 152, 129, 151, 172, 161, 155, 156,
155, 182, 163, 74, 75, 62, 33, 17, 110, 210, 180, 154,
180, 180, 50, 14, 34, 6, 10, 33, 48, 106, 159, 181,
206, 109, 5, 124, 131, 111, 120, 204, 166, 15, 56, 180,
194, 68, 137, 251, 237, 239, 239, 228, 227, 87, 71, 201,
172, 105, 207, 233, 233, 214, 220, 239, 228, 98, 74, 206,
188, 88, 179, 209, 185, 215, 211, 158, 139, 75, 20, 169,
189, 97, 165, 84, 10, 168, 134, 11, 31, 62, 22, 148,
199, 168, 191, 193, 158, 227, 178, 143, 182, 106, 36, 190,
205, 174, 155, 252, 236, 231, 149, 178, 228, 43, 95, 234,
190, 216, 116, 149, 236, 187, 86, 150, 79, 38, 218, 241,
190, 224, 147, 108, 227, 210, 127, 102, 36, 101, 255, 224,
190, 214, 173, 66, 103, 143, 96, 50, 2, 109, 249, 215,
187, 196, 235, 75, 1, 81, 47, 0, 6, 217, 255, 211,
183, 202, 237, 145, 0, 0, 12, 108, 200, 138, 243, 236,
195, 206, 123, 207, 177, 121, 123, 200, 175, 13, 96, 218};
A képadatok tárolásának ez a módja ellentétes lehet az elvárásaiddal, mivel az adatok megjelenítéskor minden bizonnyal kétdimenziósnak tűnnek. Mégis ez a helyzet, hiszen a számítógépes memória egyszerűen a címterek egyre növekvő lineáris listájából áll.

Még egyszer térjünk vissza az első képhez, és képzeljünk el egy színes képet. Most már kezdenek bonyolultabbá válni a dolgok. A számítógépek a színeket általában 3 érték – vörös, zöld és kék (RGB) – sorozataként olvassák, ugyanazon a 0-255-ös skálán. Most minden egyes pixelhez valójában 3 érték tartozik, amelyeket a számítógép a pozícióján kívül tárolni tud. Ha Lincoln elnököt színeznénk, ez 12 x 16 x 3 értéket, azaz 576 számot eredményezne.

Ez nagyon sok memóriát igényel egy képhez, és nagyon sok pixelt egy algoritmusnak, amin át kell iterálnia. De egy modell értelmes pontosságú betanításához, különösen ha mélytanulásról beszélünk, általában több tízezer képre van szükség, és minél több, annál jobb.
A számítógépes látás fejlődése
A mélytanulás megjelenése előtt a számítógépes látás által elvégezhető feladatok nagyon korlátozottak voltak, és sok kézi kódolást és erőfeszítést igényeltek a fejlesztőktől és az emberi kezelőktől. Ha például arcfelismerést akartunk végezni, a következő lépéseket kellett végrehajtani:
- Adatbázis létrehozása: Egyedi képeket kellett rögzítenie az összes olyan alanyról, akit nyomon akart követni egy meghatározott formátumban.
- A képek megjegyzése: Ezután minden egyes képhez számos kulcsfontosságú adatpontot kellett megadnia, például a szemek közötti távolságot, az orrnyereg szélességét, a felső ajak és az orr közötti távolságot és több tucat más mérési adatot, amelyek meghatározzák az egyes személyek egyedi jellemzőit.
- Új képek rögzítése: Ezután új képeket kellene rögzítenie, akár fényképekből, akár videótartalomból. Ezután pedig újra végig kellett mennie a mérési folyamaton, megjelölve a kulcsfontosságú pontokat a képen. Azt is figyelembe kellett vennie, hogy milyen szögben készült a kép.
Ezek után a kézi munka után az alkalmazás végül képes volt összehasonlítani az új képen lévő méréseket az adatbázisában tárolt mérésekkel, és megmondani, hogy az megfelel-e az általa követett profilok valamelyikének. Valójában nagyon kevés automatizálás történt, a munka nagy részét kézzel végezték. És a hibahatár még mindig nagy volt.
A gépi tanulás más megközelítést nyújtott a számítógépes látás problémáinak megoldásához. A gépi tanulással a fejlesztőknek többé nem kellett minden egyes szabályt kézzel kódolniuk a látó alkalmazásokba. Ehelyett “jellemzőket” programoztak, kisebb alkalmazásokat, amelyek képesek voltak bizonyos mintákat felismerni a képeken. Ezután statisztikai tanulási algoritmust, például lineáris regressziót, logisztikus regressziót, döntési fákat vagy támogató vektorgépeket (SVM) használtak a minták felismerésére, a képek osztályozására és a bennük lévő objektumok felismerésére.
A gépi tanulás számos olyan probléma megoldását segítette, amelyek a klasszikus szoftverfejlesztési eszközök és megközelítések számára történelmileg kihívást jelentettek. Évekkel ezelőtt például a gépi tanulással foglalkozó mérnökök olyan szoftvert tudtak létrehozni, amely jobban meg tudta jósolni a mellrák túlélési ablakát, mint az emberi szakértők. A szoftver funkcióinak kiépítése azonban több tucat mérnök és mellrákszakértő erőfeszítéseit igényelte, és sok időt vett igénybe a fejlesztés.
A mélytanulás alapvetően más megközelítést biztosított a gépi tanuláshoz. A mélytanulás a neurális hálózatokra támaszkodik, egy olyan általános célú funkcióra, amely bármilyen, példákon keresztül reprezentálható problémát képes megoldani. Ha egy neurális hálózatnak sok címkézett példát adunk egy adott adattípusból, az képes lesz arra, hogy kivonja a példák közötti közös mintákat, és átalakítsa azokat egy olyan matematikai egyenletté, amely segít a jövőbeli információk osztályozásában.
Egy arcfelismerő alkalmazás mélytanulással történő létrehozásához például csak egy előre elkészített algoritmust kell kifejleszteni vagy kiválasztani, és a felismerendő emberek arcának példáival kell betanítani. Elegendő példa (sok példa) esetén a neurális hálózat képes lesz az arcok felismerésére a jellemzőkkel vagy mérésekkel kapcsolatos további utasítások nélkül.
A mélytanulás egy nagyon hatékony módszer a számítógépes látás megvalósítására. A legtöbb esetben egy jó mélytanulási algoritmus létrehozása nagy mennyiségű címkézett képzési adat összegyűjtésén és a paraméterek, például a neurális hálózatok típusának és rétegeinek számának, valamint a képzési epocháknak a beállításán múlik. A gépi tanulás korábbi típusaihoz képest a mélytanulás egyszerre könnyebben és gyorsabban fejleszthető és alkalmazható.
A legtöbb jelenlegi számítógépes látási alkalmazás, például a rákfelismerés, az önvezető autók és az arcfelismerés a mélytanulást használja. A mélytanulás és a mély neurális hálózatok a hardver és a felhőalapú számítástechnikai erőforrások elérhetőségének és fejlődésének köszönhetően a koncepcionális területről átkerültek a gyakorlati alkalmazásokba.
How Long Does It Take It Take To Decipher An Image
Röviden nem sok. Ez a kulcsa annak, hogy miért olyan izgalmas a számítógépes látás: Míg a múltban még a szuperszámítógépeknek is napokig, hetekig vagy akár hónapokig is eltarthatott, amíg végigvitték az összes szükséges számítást, a mai ultragyors chipek és a kapcsolódó hardverek, valamint a gyors és megbízható internet és a felhőhálózatok villámgyorsá teszik a folyamatot. Egyszer döntő tényező volt az is, hogy a mesterséges intelligencia kutatásával foglalkozó nagyvállalatok közül sokan hajlandóak megosztani munkájukat a Facebook, a Google, az IBM és a Microsoft, különösen azáltal, hogy nyílt forráskódúvá tették gépi tanulási munkájuk egy részét.
Ez lehetővé teszi, hogy mások az ő munkájukra építsenek ahelyett, hogy a nulláról kezdenék. Ennek eredményeképpen a mesterséges intelligencia ipara egyre csak főz, és azok a kísérletek, amelyek nemrég még hetekig tartottak, ma már 15 perc alatt elvégezhetők. A számítógépes látás számos valós alkalmazása esetében pedig mindez a folyamat folyamatosan, mikromásodpercek alatt történik, így egy számítógép ma már képes arra, amit a tudósok “szituációtudatosnak” neveznek.”
A számítógépes látás alkalmazásai
A számítógépes látás a gépi tanulás azon területeinek egyike, ahol az alapvető koncepciókat már beépítették a mindennap használt főbb termékekbe.
CV az önvezető autókban
De nem csak a technológiai vállalatok használják ki a gépi tanulást a képi alkalmazásokban.
A számítógépes látás lehetővé teszi az önvezető autók számára, hogy értelmezni tudják a környezetüket. A kamerák különböző szögekből rögzítik a videót az autó körül, és betáplálják a számítógépes látás szoftverébe, amely aztán valós időben feldolgozza a képeket, hogy megtalálja az utak végpontjait, leolvassa a közlekedési táblákat, felismerje a többi autót, tárgyakat és gyalogosokat. Az önvezető autó ezután képes irányítani az utakon és autópályákon, elkerülni az akadályokba ütközést, és (remélhetőleg) biztonságosan eljuttatni utasait a célállomásra.
CV az arcfelismerésben
A számítógépes látás az arcfelismerő alkalmazásokban is fontos szerepet játszik, abban a technológiában, amelynek segítségével a számítógépek az emberek arcáról készült képeket azonosítani tudják. A számítógépes látás algoritmusai felismerik az arcvonásokat a képeken, és összehasonlítják azokat az arcprofilokat tartalmazó adatbázisokkal. A fogyasztói eszközök arcfelismerést használnak a tulajdonosok személyazonosságának hitelesítésére. A közösségi médiaalkalmazások arcfelismerést használnak a felhasználók felismerésére és megjelölésére. A bűnüldöző szervek szintén az arcfelismerő technológiára támaszkodnak a bűnözők videókon történő azonosításában.
CV a kiterjesztett valóságban & vegyes valóság
A számítógépes látás a kiterjesztett és vegyes valóságban is fontos szerepet játszik, abban a technológiában, amely lehetővé teszi, hogy a számítástechnikai eszközök, például az okostelefonok, táblagépek és okosszemüvegek virtuális tárgyakat helyezzenek el és ágyazzanak be a valós világ képeire. A számítógépes látás segítségével az AR-eszközök érzékelik a valós világ tárgyait, hogy meghatározzák a virtuális tárgyak elhelyezésének helyét az eszköz kijelzőjén. A számítógépes látás algoritmusai például segíthetnek az AR-alkalmazásoknak az olyan síkok, mint az asztallapok, falak és padlók felismerésében, ami nagyon fontos része a mélység és a méretek megállapításának, valamint a virtuális tárgyak fizikai világban való elhelyezésének.
CV az egészségügyben
A számítógépes látás az egészségügyi technológia fejlődésének is fontos részét képezi. A számítógépes látás algoritmusai segíthetnek olyan feladatok automatizálásában, mint például a rákos anyajegyek felismerése a bőrfelvételeken vagy a tünetek megtalálása a röntgen- és MRI-felvételeken.
A számítógépes látás kihívásai
A számítógépek látásának segítése nagyon nehéznek bizonyul.
Egy olyan gép feltalálása, amely úgy lát, mint mi, megtévesztően nehéz feladat, és nemcsak azért, mert nehéz rávenni a számítógépeket, hanem azért is, mert nem vagyunk teljesen biztosak abban, hogy az emberi látás egyáltalán hogyan működik.
A biológiai látás tanulmányozása megköveteli az érzékelő szervek, például a szemek, valamint az érzékelés agyon belüli értelmezésének megértését. Sok előrelépés történt mind a folyamat feltérképezése, mind a rendszer által használt trükkök és rövidítések felfedezése terén, bár mint minden olyan vizsgálat, amely az agyat érinti, még hosszú út áll előttünk.

Számos népszerű számítógépes látás alkalmazásban próbálnak felismerni dolgokat fényképeken; például:
- Objektumosztályozás:
- Objektum azonosítása:
- Objektum ellenőrzése: Rajta van-e a tárgy a fényképen?
- Tárgyfelismerés: Hol vannak a tárgyak a fényképen?
- Objektum tájékozódási pontok felismerése: Melyek a tárgy kulcspontjai a fényképen?
- Objektum szegmentálás: Milyen pixelek tartoznak a képen lévő objektumhoz?
- Objektumfelismerés: Milyen tárgyak vannak ezen a fényképen, és hol vannak?
A felismerésen kívül az elemzés egyéb módszerei közé tartoznak:
- A videó mozgáselemzés a számítógépes látást használja a videón lévő tárgyak vagy maga a kamera sebességének becslésére.
- A képszegmentálás során az algoritmusok a képeket több nézetcsoportra osztják.
- A jelenet rekonstrukciója a képek vagy videók segítségével megadott jelenet 3D modelljét hozza létre.
- A képrestaurálás során a zaj, például az elmosódás eltávolítása a fényképekről gépi tanuláson alapuló szűrők segítségével történik.
Minden más alkalmazás, amely a pixelek szoftveres megértését foglalja magában, nyugodtan nevezhető számítógépes látásnak.
Következtetés
A közelmúltbeli, lenyűgöző fejlődés ellenére még mindig nem vagyunk közel a számítógépes látás megoldásához. Azonban már több olyan egészségügyi intézmény és vállalat van, amely megtalálta a módját annak, hogy a CNN-ek által működtetett CV-rendszereket valós problémákra alkalmazza. És ez a tendencia valószínűleg nem fog egyhamar megállni.
Ha szeretnél kapcsolatba lépni velem, és egyébként tudsz egy jó viccet, akkor a Twitteren vagy a LinkedIn-en kapcsolatba léphetsz velem.
Köszönöm az olvasást!😄 🙌