- Ecco uno sguardo al perché è così impressionante.
- L’Evoluzione Della Visione Computerizzata
- Quanto tempo ci vuole per decifrare un’immagine
- Applications Of Computer Vision
- CV nelle auto a guida autonoma
- CV Nel riconoscimento facciale
- CV nella realtà aumentata &realtà mista
- CV In Healthcare
- Sfide della Computer Vision
- Conclusione
Ecco uno sguardo al perché è così impressionante.
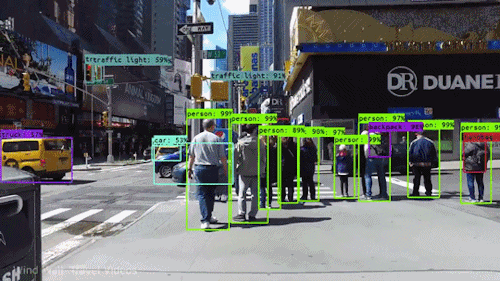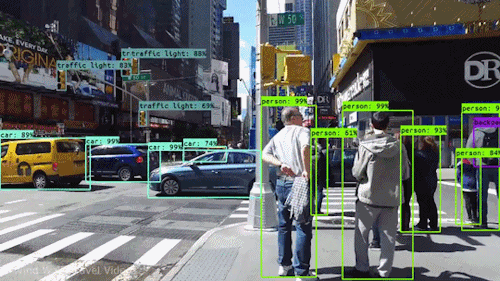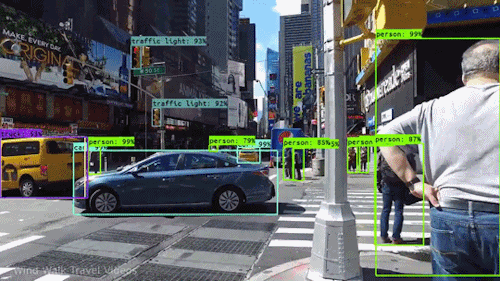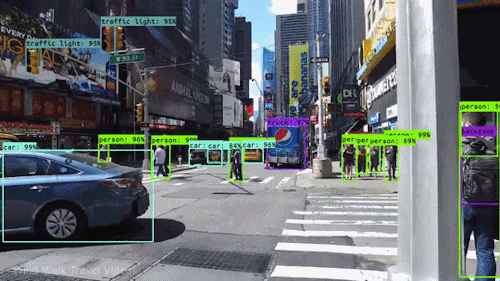
Uno dei tipi più potenti e convincenti di IA è la computer vision che quasi sicuramente hai sperimentato in molti modi senza nemmeno saperlo. Ecco uno sguardo a cos’è, come funziona e perché è così impressionante (e potrà solo migliorare).
La computer vision è il campo dell’informatica che si concentra sulla replica di parti della complessità del sistema visivo umano e consente ai computer di identificare ed elaborare oggetti in immagini e video nello stesso modo in cui lo fanno gli umani. Fino a poco tempo fa, la computer vision funzionava solo in modo limitato.
Grazie ai progressi dell’intelligenza artificiale e alle innovazioni nell’apprendimento profondo e nelle reti neurali, il campo è stato in grado di fare grandi balzi negli ultimi anni ed è stato in grado di superare gli umani in alcuni compiti relativi al rilevamento e all’etichettatura degli oggetti.
Uno dei fattori trainanti della crescita della computer vision è la quantità di dati che generiamo oggi e che vengono poi utilizzati per addestrare e rendere migliore la computer vision.

Insieme a una quantità enorme di dati visivi (più di 3 miliardi di immagini vengono condivise online ogni giorno), la potenza di calcolo necessaria per analizzare i dati è ora accessibile. Come il campo della computer vision è cresciuto con nuovi hardware e algoritmi, così è cresciuto il tasso di precisione per l’identificazione degli oggetti. In meno di un decennio, i sistemi di oggi hanno raggiunto il 99 per cento di accuratezza dal 50 per cento, rendendoli più accurati degli umani nel reagire rapidamente agli input visivi.
I primi esperimenti di computer vision sono iniziati negli anni ’50 ed è stato utilizzato per la prima volta commercialmente per distinguere tra testo digitato e scritto a mano negli anni ’70, oggi le applicazioni della computer vision sono cresciute esponenzialmente.
Entro il 2022, il mercato della computer vision e dell’hardware dovrebbe raggiungere i 48,6 miliardi di dollari
Una delle maggiori domande aperte sia nelle neuroscienze che nel machine learning è: come funziona esattamente il nostro cervello e come possiamo approssimarlo con i nostri algoritmi? La realtà è che ci sono pochissime teorie funzionanti e complete sulla computazione del cervello; così, nonostante il fatto che si suppone che le reti neurali “imitino il modo in cui funziona il cervello”, nessuno è del tutto sicuro che questo sia effettivamente vero.
Lo stesso paradosso vale per la computer vision – poiché non siamo decisi su come il cervello e gli occhi elaborano le immagini, è difficile dire quanto bene gli algoritmi usati nella produzione approssimano i nostri processi mentali interni.
A un certo livello la computer vision è tutta una questione di riconoscimento di modelli. Quindi un modo per addestrare un computer a capire i dati visivi è quello di fornirgli immagini, migliaia di immagini, milioni se possibile, che sono state etichettate, e poi sottoporle a varie tecniche software, o algoritmi, che permettono al computer di andare a caccia di modelli in tutti gli elementi che si riferiscono a quelle etichette.
Così, per esempio, se date in pasto a un computer un milione di immagini di gatti (tutti li amiamo😄😹), esso le sottoporrà tutte ad algoritmi che gli permettono di analizzare i colori nella foto, le forme, le distanze tra le forme, dove gli oggetti confinano tra loro, e così via, in modo da identificare un profilo di ciò che significa “gatto”. Quando ha finito, il computer sarà (in teoria) in grado di usare la sua esperienza se alimentato con altre immagini non etichettate per trovare quelle che sono di gatto.
Lasciamo per un momento da parte i nostri soffici amici gatti e andiamo più sul tecnico🤔😹. Qui sotto c’è una semplice illustrazione del buffer di immagini in scala di grigi che memorizza la nostra immagine di Abraham Lincoln. La luminosità di ogni pixel è rappresentata da un singolo numero a 8 bit, il cui range va da 0 (nero) a 255 (bianco):

In effetti, i valori dei pixel sono quasi universalmente memorizzati, a livello hardware, in un array unidimensionale. Per esempio, i dati dell’immagine qui sopra sono memorizzati in un modo simile a questa lunga lista di caratteri senza segno:
{157, 153, 174, 168, 150, 152, 129, 151, 172, 161, 155, 156,
155, 182, 163, 74, 75, 62, 33, 17, 110, 210, 180, 154,
180, 180, 50, 14, 34, 6, 10, 33, 48, 106, 159, 181,
206, 109, 5, 124, 131, 111, 120, 204, 166, 15, 56, 180,
194, 68, 137, 251, 237, 239, 239, 228, 227, 87, 71, 201,
172, 105, 207, 233, 233, 214, 220, 239, 228, 98, 74, 206,
188, 88, 179, 209, 185, 215, 211, 158, 139, 75, 20, 169,
189, 97, 165, 84, 10, 168, 134, 11, 31, 62, 22, 148,
199, 168, 191, 193, 158, 227, 178, 143, 182, 106, 36, 190,
205, 174, 155, 252, 236, 231, 149, 178, 228, 43, 95, 234,
190, 216, 116, 149, 236, 187, 86, 150, 79, 38, 218, 241,
190, 224, 147, 108, 227, 210, 127, 102, 36, 101, 255, 224,
190, 214, 173, 66, 103, 143, 96, 50, 2, 109, 249, 215,
187, 196, 235, 75, 1, 81, 47, 0, 6, 217, 255, 211,
183, 202, 237, 145, 0, 0, 12, 108, 200, 138, 243, 236,
195, 206, 123, 207, 177, 121, 123, 200, 175, 13, 96, 218};
Questo modo di memorizzare i dati dell’immagine può andare contro le vostre aspettative, poiché i dati sembrano certamente essere bidimensionali quando vengono visualizzati. Eppure, è così, poiché la memoria del computer consiste semplicemente in una lista lineare sempre crescente di spazi di indirizzo.

Torniamo ancora alla prima immagine e immaginiamo di aggiungerne una colorata. Ora le cose cominciano a diventare più complicate. I computer di solito leggono il colore come una serie di 3 valori – rosso, verde e blu (RGB) – su quella stessa scala 0-255. Ora, ogni pixel ha effettivamente 3 valori che il computer deve memorizzare oltre alla sua posizione. Se dovessimo colorare il presidente Lincoln, questo porterebbe a 12 x 16 x 3 valori, o 576 numeri.

Questa è un sacco di memoria da richiedere per un’immagine, e un sacco di pixel per un algoritmo da iterare. Ma per addestrare un modello con un’accuratezza significativa, specialmente quando si parla di Deep Learning, di solito sono necessarie decine di migliaia di immagini, e più sono meglio è.
L’Evoluzione Della Visione Computerizzata
Prima dell’avvento del deep learning, i compiti che la computer vision poteva eseguire erano molto limitati e richiedevano un sacco di codifica manuale e sforzi da parte di sviluppatori e operatori umani. Per esempio, se si voleva eseguire il riconoscimento facciale, si dovevano eseguire i seguenti passi:
- Creare un database: Dovevate catturare singole immagini di tutti i soggetti che volevate tracciare in un formato specifico.
- Annotate le immagini: Poi per ogni singola immagine, avresti dovuto inserire diversi punti di dati chiave, come la distanza tra gli occhi, la larghezza del ponte del naso, la distanza tra il labbro superiore e il naso, e decine di altre misure che definiscono le caratteristiche uniche di ogni persona.
- Catturare nuove immagini: Successivamente, si dovevano catturare nuove immagini, sia da fotografie che da contenuti video. E poi si doveva passare di nuovo attraverso il processo di misurazione, segnando i punti chiave sull’immagine. Bisognava anche tenere conto dell’angolo in cui l’immagine era stata scattata.
Dopo tutto questo lavoro manuale, l’applicazione era finalmente in grado di confrontare le misure della nuova immagine con quelle memorizzate nel suo database e dirvi se corrispondeva a uno dei profili che stava seguendo. In realtà, c’era pochissima automazione e la maggior parte del lavoro veniva fatto manualmente. E il margine di errore era ancora grande.
L’apprendimento automatico ha fornito un approccio diverso alla soluzione dei problemi di computer vision. Con il machine learning, gli sviluppatori non avevano più bisogno di codificare manualmente ogni singola regola nelle loro applicazioni di visione. Invece hanno programmato delle “caratteristiche”, applicazioni più piccole in grado di rilevare modelli specifici nelle immagini. Hanno poi usato un algoritmo di apprendimento statistico come la regressione lineare, la regressione logistica, gli alberi decisionali o le macchine vettoriali di supporto (SVM) per individuare i modelli e classificare le immagini e rilevare gli oggetti in esse.
L’apprendimento automatico ha aiutato a risolvere molti problemi che erano storicamente impegnativi per gli strumenti e gli approcci classici di sviluppo del software. Per esempio, anni fa, gli ingegneri del machine learning sono stati in grado di creare un software che poteva prevedere le finestre di sopravvivenza del cancro al seno meglio degli esperti umani. Tuttavia la costruzione delle caratteristiche del software ha richiesto gli sforzi di decine di ingegneri ed esperti di cancro al seno e ha richiesto molto tempo per lo sviluppo.
L’apprendimento profondo ha fornito un approccio fondamentalmente diverso per fare apprendimento automatico. L’apprendimento profondo si basa sulle reti neurali, una funzione generale che può risolvere qualsiasi problema rappresentabile attraverso esempi. Quando si fornisce a una rete neurale molti esempi etichettati di un tipo specifico di dati, essa sarà in grado di estrarre modelli comuni tra quegli esempi e trasformarli in un’equazione matematica che aiuterà a classificare le informazioni future.
Per esempio, creare un’applicazione di riconoscimento facciale con il deep learning richiede solo di sviluppare o scegliere un algoritmo precostituito e addestrarlo con esempi dei volti delle persone che deve rilevare. Dati abbastanza esempi (molti esempi), la rete neurale sarà in grado di rilevare i volti senza ulteriori istruzioni su caratteristiche o misure.
Il deep learning è un metodo molto efficace per fare la visione artificiale. Nella maggior parte dei casi, la creazione di un buon algoritmo di deep learning si riduce alla raccolta di una grande quantità di dati di allenamento etichettati e alla messa a punto di parametri come il tipo e il numero di strati delle reti neurali e le epoche di allenamento. Rispetto ai precedenti tipi di apprendimento automatico, l’apprendimento profondo è sia più facile che più veloce da sviluppare e implementare.
La maggior parte delle attuali applicazioni di computer vision come il rilevamento del cancro, le auto a guida autonoma e il riconoscimento facciale fanno uso dell’apprendimento profondo. L’apprendimento profondo e le reti neurali profonde sono passate dal regno concettuale alle applicazioni pratiche grazie alla disponibilità e ai progressi dell’hardware e delle risorse di cloud computing.
Quanto tempo ci vuole per decifrare un’immagine
In breve non molto. Questa è la chiave del perché la computer vision è così eccitante: Mentre in passato anche i supercomputer potevano impiegare giorni, settimane o addirittura mesi per eseguire tutti i calcoli richiesti, i chip ultraveloci di oggi e l’hardware correlato, insieme a un internet veloce e affidabile e alle reti cloud, rendono il processo fulmineo. Un fattore cruciale è stata la volontà di molte delle grandi aziende che fanno ricerca sull’IA di condividere il loro lavoro Facebook, Google, IBM e Microsoft, in particolare con l’open sourcing di alcuni dei loro lavori di apprendimento automatico.
Questo permette agli altri di costruire sul loro lavoro piuttosto che partire da zero. Di conseguenza, l’industria dell’IA si sta muovendo, e gli esperimenti che non molto tempo fa richiedevano settimane per essere eseguiti potrebbero richiedere 15 minuti oggi. E per molte applicazioni reali di computer vision, tutto questo processo avviene continuamente in microsecondi, così che un computer oggi è in grado di essere quello che gli scienziati chiamano “situationally aware.”
Applications Of Computer Vision
Computer vision è una delle aree del Machine Learning dove i concetti fondamentali sono già integrati nei principali prodotti che usiamo ogni giorno.
CV nelle auto a guida autonoma
Ma non sono solo le aziende tecnologiche che stanno sfruttando il Machine Learning per applicazioni di immagini.
La visione artificiale permette alle auto a guida autonoma di dare un senso all’ambiente circostante. Le telecamere catturano video da diverse angolazioni intorno all’auto e li passano al software di computer vision, che poi elabora le immagini in tempo reale per trovare le estremità delle strade, leggere i segnali stradali, rilevare altre auto, oggetti e pedoni. L’auto a guida autonoma può quindi orientarsi su strade e autostrade, evitare di colpire gli ostacoli e (si spera) guidare in modo sicuro i suoi passeggeri a destinazione.
CV Nel riconoscimento facciale
La computer vision gioca anche un ruolo importante nelle applicazioni di riconoscimento facciale, la tecnologia che permette ai computer di abbinare le immagini dei volti delle persone alle loro identità. Gli algoritmi di visione del computer rilevano le caratteristiche facciali nelle immagini e le confrontano con i database dei profili dei volti. I dispositivi di consumo usano il riconoscimento facciale per autenticare le identità dei loro proprietari. Le app dei social media usano il riconoscimento facciale per individuare e taggare gli utenti. Anche le forze dell’ordine si affidano alla tecnologia di riconoscimento facciale per identificare i criminali nei feed video.
CV nella realtà aumentata &realtà mista
La visione del computer gioca anche un ruolo importante nella realtà aumentata e mista, la tecnologia che permette ai dispositivi informatici come smartphone, tablet e occhiali intelligenti di sovrapporre e incorporare oggetti virtuali sulle immagini del mondo reale. Utilizzando la computer vision, gli ingranaggi AR rilevano gli oggetti nel mondo reale al fine di determinare le posizioni sul display di un dispositivo per posizionare un oggetto virtuale. Per esempio, gli algoritmi di computer vision possono aiutare le applicazioni AR a rilevare piani come i piani dei tavoli, le pareti e i pavimenti, una parte molto importante per stabilire la profondità e le dimensioni e posizionare gli oggetti virtuali nel mondo fisico.
CV In Healthcare
La computer vision è stata anche una parte importante dei progressi nella tecnologia sanitaria. Gli algoritmi di computer vision possono aiutare ad automatizzare compiti come l’individuazione di nei cancerosi nelle immagini della pelle o la ricerca di sintomi nelle scansioni a raggi X e MRI.
Sfide della Computer Vision
Aiutare i computer a vedere risulta essere molto difficile.
Inventare una macchina che veda come noi è un compito ingannevolmente difficile, non solo perché è difficile farlo fare ai computer, ma perché non siamo del tutto sicuri di come funzioni la visione umana in primo luogo.
Studiare la visione biologica richiede una comprensione degli organi di percezione come gli occhi, così come l’interpretazione della percezione nel cervello. Sono stati fatti molti progressi, sia nel tracciare il processo che in termini di scoperta dei trucchi e delle scorciatoie usate dal sistema, anche se, come ogni studio che coinvolge il cervello, c’è ancora molta strada da fare.

Molte applicazioni popolari di computer vision coinvolgono il tentativo di riconoscere cose nelle fotografie; per esempio:
- Classificazione degli oggetti: Quale ampia categoria di oggetti si trova in questa fotografia?
- Identificazione dell’oggetto: Quale tipo di un dato oggetto si trova in questa fotografia?
- Verifica dell’oggetto: L’oggetto è nella fotografia?
- Rilevamento dell’oggetto: Dove sono gli oggetti nella fotografia?
- Rilevamento dei punti di riferimento dell’oggetto: Quali sono i punti chiave per l’oggetto nella fotografia?
- Segmentazione dell’oggetto: Quali pixel appartengono all’oggetto nell’immagine?
- Riconoscimento dell’oggetto: Quali oggetti ci sono in questa fotografia e dove sono?
Al di fuori del semplice riconoscimento, altri metodi di analisi includono:
- L’analisi del movimento video usa la visione artificiale per stimare la velocità degli oggetti in un video, o la telecamera stessa.
- Nella segmentazione delle immagini, gli algoritmi dividono le immagini in più serie di viste.
- La ricostruzione della scena crea un modello 3D di una scena immessa attraverso immagini o video.
- Nel restauro delle immagini, il rumore come la sfocatura viene rimosso dalle foto usando filtri basati sul Machine Learning.
Tutte le altre applicazioni che coinvolgono la comprensione dei pixel attraverso il software possono essere tranquillamente etichettate come computer vision.
Conclusione
Nonostante i recenti progressi, che sono stati impressionanti, non siamo ancora nemmeno vicini alla soluzione della computer vision. Tuttavia, ci sono già molteplici istituzioni sanitarie e imprese che hanno trovato il modo di applicare i sistemi CV, alimentati dalle CNN, ai problemi del mondo reale. E questa tendenza non si fermerà molto presto.
Se vuoi metterti in contatto e, a proposito, conosci una bella barzelletta, puoi connetterti con me su Twitter o LinkedIn.
Grazie per aver letto!😄 🙌