- Här är en titt på varför det är så fantastiskt.
- The Evolution Of Computer Vision
- Hur lång tid tar det att dechiffrera en bild
- Applications Of Computer Vision
- CV i självkörande bilar
- CV i ansiktsigenkänning
- CV i förstärkt verklighet & blandad verklighet
- CV inom hälso- och sjukvården
- Utmaningar med datorseende
- Slutsats
Här är en titt på varför det är så fantastiskt.
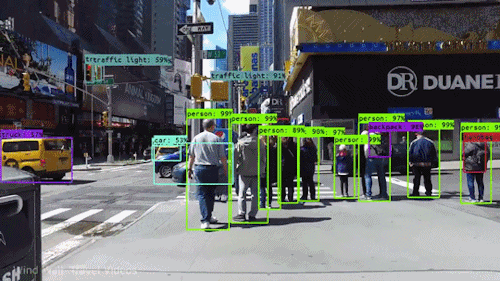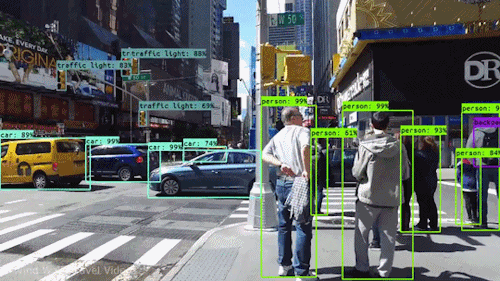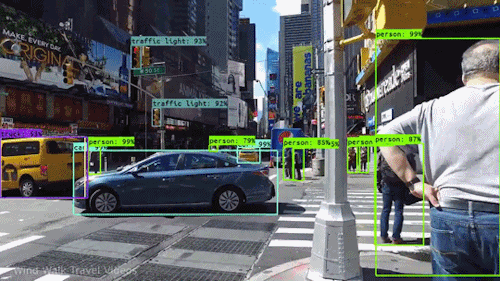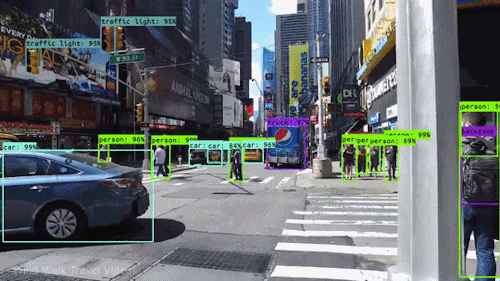
En av de mest kraftfulla och övertygande typerna av artificiell intelligens är datorseende, som du med all säkerhet har upplevt på ett antal olika sätt utan att veta om. Här är en titt på vad det är, hur det fungerar och varför det är så fantastiskt (och bara kommer att bli bättre).
Datorseende är det område inom datavetenskapen som fokuserar på att replikera delar av komplexiteten hos människans synsystem och göra det möjligt för datorer att identifiera och bearbeta objekt i bilder och videor på samma sätt som människor gör. Fram till nyligen fungerade datorseende endast i begränsad kapacitet.
Tack vare framsteg inom artificiell intelligens och innovationer inom djupinlärning och neurala nätverk har området kunnat ta stora steg under de senaste åren och har kunnat överträffa människor i vissa uppgifter som rör upptäckt och märkning av objekt.
En av de drivande faktorerna bakom tillväxten inom datorseende är den mängd data vi genererar i dag som sedan används för att träna och göra datorseende bättre.

Samtidigt som det finns en enorm mängd visuella data (mer än 3 miljarder bilder delas på nätet varje dag) är den datorkraft som krävs för att analysera dessa data nu tillgänglig. I takt med att området datorseende har vuxit med ny hårdvara och nya algoritmer har också noggrannheten för identifiering av objekt ökat. På mindre än ett decennium har dagens system nått en noggrannhet på 99 procent från 50 procent, vilket gör dem noggrannare än människor när det gäller att snabbt reagera på visuell inmatning.
De första experimenten med datorseende inleddes på 1950-talet och det började användas kommersiellt för att skilja mellan maskinskriven och handskriven text på 1970-talet, men i dag har användningsområdena för datorseende vuxit exponentiellt.
För 2022 förväntas marknaden för datorseende och hårdvara nå 48,6 miljarder dollar
En av de stora öppna frågorna inom både neurovetenskap och maskininlärning är: Exakt hur fungerar våra hjärnor, och hur kan vi närma oss det med våra egna algoritmer? Verkligheten är att det finns mycket få fungerande och heltäckande teorier om hjärnans beräkningar; så trots att neurala nät antas ”efterlikna hur hjärnan fungerar” är ingen riktigt säker på om det faktiskt är sant.
Samma paradox gäller för datorseende – eftersom vi inte har bestämt oss för hur hjärnan och ögonen bearbetar bilder är det svårt att säga hur väl algoritmerna som används i produktionen närmar sig våra egna interna mentala processer.
På en viss nivå handlar datorseende om mönsterigenkänning. Så ett sätt att träna en dator i att förstå visuella data är att mata den med bilder, massor av bilder, tusentals, miljoner om möjligt, som har märkts, och sedan utsätta dem för olika programvarutekniker, eller algoritmer, som gör det möjligt för datorn att jaga mönster i alla element som relaterar till dessa märken.
Om du till exempel matar en dator med en miljon bilder av katter (vi älskar dem alla😄😹), kommer den att låta algoritmer analysera färgerna i fotot, formerna, avstånden mellan formerna, var föremålen gränsar till varandra och så vidare, så att den kan identifiera en profil av vad ”katt” betyder. När den är klar kommer datorn (i teorin) att kunna använda sin erfarenhet om matade andra omärkta bilder för att hitta de bilder som är av katt.
Lämna våra fluffiga kattvänner för en stund vid sidan om och låt oss bli mer tekniska🤔😹. Nedan följer en enkel illustration av den gråskaliga bildbuffert som lagrar vår bild av Abraham Lincoln. Varje pixels ljusstyrka representeras av ett enda 8-bitarstal vars intervall går från 0 (svart) till 255 (vitt):

Pixelvärden lagras nästan alltid på hårdvarunivå i en endimensionell matris. Data från bilden ovan lagras till exempel på ett sätt som liknar den här långa listan av tecken utan förtecken:
{157, 153, 174, 168, 150, 152, 129, 151, 172, 161, 155, 156,
155, 182, 163, 74, 75, 62, 33, 17, 110, 210, 180, 154,
180, 180, 50, 14, 34, 6, 10, 33, 48, 106, 159, 181,
206, 109, 5, 124, 131, 111, 120, 204, 166, 15, 56, 180,
194, 68, 137, 251, 237, 239, 239, 228, 227, 87, 71, 201,
172, 105, 207, 233, 233, 214, 220, 239, 228, 98, 74, 206,
188, 88, 179, 209, 185, 215, 211, 158, 139, 75, 20, 169,
189, 97, 165, 84, 10, 168, 134, 11, 31, 62, 22, 148,
199, 168, 191, 193, 158, 227, 178, 143, 182, 106, 36, 190,
205, 174, 155, 252, 236, 231, 149, 178, 228, 43, 95, 234,
190, 216, 116, 149, 236, 187, 86, 150, 79, 38, 218, 241,
190, 224, 147, 108, 227, 210, 127, 102, 36, 101, 255, 224,
190, 214, 173, 66, 103, 143, 96, 50, 2, 109, 249, 215,
187, 196, 235, 75, 1, 81, 47, 0, 6, 217, 255, 211,
183, 202, 237, 145, 0, 0, 12, 108, 200, 138, 243, 236,
195, 206, 123, 207, 177, 121, 123, 200, 175, 13, 96, 218};
Detta sätt att lagra bilddata kan strida mot dina förväntningar, eftersom data verkligen verkar vara tvådimensionella när de visas. Ändå är detta fallet, eftersom datorminnet helt enkelt består av en ständigt ökande linjär lista av adressutrymmen.

Hur pixlar lagras i minnet
Vi återgår till den första bilden igen och föreställer oss att vi lägger till en färgad bild. Nu börjar saker och ting bli mer komplicerade. Datorer läser vanligtvis färg som en serie av tre värden – rött, grönt och blått (RGB) – på samma skala 0-255. Nu har varje pixel faktiskt tre värden för datorn att lagra utöver sin position. Om vi skulle färglägga president Lincoln skulle det leda till 12 x 16 x 3 värden, eller 576 siffror.

Det är mycket minne för en bild och många pixlar för en algoritm att iterera över. Men för att träna en modell med meningsfull noggrannhet, särskilt när man talar om djupinlärning, behöver man vanligtvis tiotusentals bilder, och ju fler desto bättre.
The Evolution Of Computer Vision
Före införandet av djupinlärning var de uppgifter som datorseende kunde utföra mycket begränsade och krävde en hel del manuell kodning och ansträngning av utvecklare och mänskliga operatörer. Om du till exempel ville utföra ansiktsigenkänning skulle du behöva utföra följande steg:
- Skapa en databas: Du var tvungen att ta individuella bilder av alla personer som du ville spåra i ett visst format.
- Kommentera bilderna: För varje enskild bild måste du sedan ange flera viktiga datapunkter, t.ex. avståndet mellan ögonen, bredden på näsbryggan, avståndet mellan överläppen och näsan och dussintals andra mätningar som definierar varje persons unika egenskaper.
- Fånga nya bilder: Därefter måste du fånga nya bilder, antingen från fotografier eller videoinnehåll. Och sedan var man tvungen att gå igenom mätprocessen igen och markera nyckelpunkterna på bilden. Du var också tvungen att ta hänsyn till vinkeln som bilden togs.
Efter allt detta manuella arbete skulle programmet slutligen kunna jämföra måtten i den nya bilden med dem som fanns lagrade i databasen och tala om för dig om den motsvarade någon av de profiler som den spårade. I själva verket var det väldigt lite automatisering inblandad och det mesta av arbetet gjordes manuellt. Och felmarginalen var fortfarande stor.
Maskininlärning gav ett annat sätt att lösa problem med datorseende. Med maskininlärning behövde utvecklarna inte längre manuellt koda varje enskild regel i sina visionsprogram. Istället programmerade de ”funktioner”, mindre program som kunde upptäcka specifika mönster i bilder. De använde sedan en statistisk inlärningsalgoritm som linjär regression, logistisk regression, beslutsträd eller stödvektormaskiner (SVM) för att upptäcka mönster och klassificera bilder och upptäcka objekt i dem.
Maskininlärning hjälpte till att lösa många problem som historiskt sett var en utmaning för klassiska verktyg och metoder för programvaruutveckling. För flera år sedan kunde maskininlärningsingenjörer till exempel skapa en programvara som kunde förutsäga bröstcancers överlevnadsfönster bättre än mänskliga experter. För att bygga upp programvarans funktioner krävdes dock insatser från dussintals ingenjörer och bröstcancerexperter och det tog mycket tid att utveckla.
Djupinlärning erbjöd ett fundamentalt annorlunda sätt att göra maskininlärning. Djupinlärning bygger på neurala nätverk, en funktion för allmänna ändamål som kan lösa alla problem som kan representeras med hjälp av exempel. När du förser ett neuralt nätverk med många märkta exempel på en viss typ av data kan det extrahera gemensamma mönster mellan dessa exempel och omvandla det till en matematisk ekvation som hjälper till att klassificera framtida information.
För att skapa ett program för ansiktsigenkänning med hjälp av djupinlärning krävs det till exempel bara att du utvecklar eller väljer en förkonstruerad algoritm och tränar den med exempel på ansikten av de personer som den ska upptäcka. Med tillräckligt många exempel (massor av exempel) kommer det neurala nätverket att kunna upptäcka ansikten utan ytterligare instruktioner om egenskaper eller mätningar.
Djupinlärning är en mycket effektiv metod för att göra datorseende. I de flesta fall handlar det om att skapa en bra algoritm för djupinlärning genom att samla in en stor mängd märkta träningsdata och ställa in parametrarna, t.ex. typ och antal lager av neurala nätverk och träningsepoker. Jämfört med tidigare typer av maskininlärning är djupinlärning både enklare och snabbare att utveckla och använda.
De flesta av dagens tillämpningar för datorseende, t.ex. upptäckt av cancer, självkörande bilar och ansiktsigenkänning, använder sig av djupinlärning. Djupinlärning och djupa neurala nätverk har gått från den konceptuella sfären till praktiska tillämpningar tack vare tillgängligheten och framstegen inom hårdvara och molndatorresurser.
Hur lång tid tar det att dechiffrera en bild
In korthet inte mycket. Det är nyckeln till varför datorseende är så spännande: Tidigare tog det till och med superdatorer dagar, veckor eller till och med månader att göra alla de beräkningar som krävs, men dagens ultrasnabba chip och tillhörande hårdvara, tillsammans med snabba och tillförlitliga internet- och molnnätverk, gör processen blixtsnabb. En avgörande faktor har varit att många av de stora företag som forskar om artificiell intelligens är villiga att dela med sig av sitt arbete Facebook, Google, IBM och Microsoft, särskilt genom att öppna en del av sitt arbete med maskininlärning.
Detta gör det möjligt för andra att bygga vidare på deras arbete i stället för att börja om från början. Som ett resultat av detta kokar AI-industrin med, och experiment som för inte så länge sedan tog veckor att genomföra kan i dag ta 15 minuter. Och för många verkliga tillämpningar av datorseende sker allt detta kontinuerligt på mikrosekunder, så att en dator i dag kan vara vad forskarna kallar ”situationsmedveten.”
Applications Of Computer Vision
Datorseende är ett av de områden inom maskininlärning där kärnkoncepten redan håller på att integreras i viktiga produkter som vi använder varje dag.
CV i självkörande bilar
Men det är inte bara teknikföretag som utnyttjar maskininlärning för bildtillämpningar.
Datorseende gör det möjligt för självkörande bilar att förstå sin omgivning. Kameror fångar video från olika vinklar runt bilen och matar den till datorseende programvara, som sedan bearbetar bilderna i realtid för att hitta vägens ytterpunkter, läsa trafikskyltar, upptäcka andra bilar, föremål och fotgängare. Den självkörande bilen kan sedan styra sin väg på gator och motorvägar, undvika att köra på hinder och (förhoppningsvis) säkert köra sina passagerare till sin destination.
CV i ansiktsigenkänning
Datorseende spelar också en viktig roll i tillämpningar för ansiktsigenkänning, den teknik som gör det möjligt för datorer att matcha bilder av människors ansikten med deras identiteter. Algoritmer för datorseende upptäcker ansiktsdrag i bilder och jämför dem med databaser med ansiktsprofiler. Konsumentapparater använder ansiktsigenkänning för att autentisera ägarens identitet. Appar för sociala medier använder ansiktsigenkänning för att upptäcka och märka användare. Brottsbekämpande myndigheter förlitar sig också på teknik för ansiktsigenkänning för att identifiera brottslingar i videoflöden.
CV i förstärkt verklighet & blandad verklighet
Datorseende spelar också en viktig roll i förstärkt och blandad verklighet, den teknik som gör det möjligt för datorer som smarttelefoner, surfplattor och smarta glasögon att överlagra och bädda in virtuella objekt på bilder från den verkliga världen. Med hjälp av datorseende upptäcker AR-utrustningen objekt i den verkliga världen för att avgöra var på enhetens bildskärm ett virtuellt objekt ska placeras. Algoritmer för datorseende kan till exempel hjälpa AR-tillämpningar att upptäcka plan såsom bordsskivor, väggar och golv, vilket är en mycket viktig del för att fastställa djup och dimensioner och placera virtuella objekt i den fysiska världen.
CV inom hälso- och sjukvården
Datorseende har också varit en viktig del av framstegen inom hälsotekniken. Algoritmer för datorseende kan hjälpa till att automatisera uppgifter som att upptäcka cancermärken i hudbilder eller hitta symtom i röntgen- och magnetröntgenbilder.
Utmaningar med datorseende
Att hjälpa datorer att se visar sig vara mycket svårt.
Att uppfinna en maskin som ser som vi gör är en bedrägligt svår uppgift, inte bara för att det är svårt att få datorer att göra det, utan också för att vi inte är helt säkra på hur människans syn fungerar till att börja med.
Studier av biologiskt seende kräver en förståelse för perceptionsorganen, som ögonen, samt tolkningen av perceptionen i hjärnan. Stora framsteg har gjorts, både när det gäller att kartlägga processen och när det gäller att upptäcka de knep och genvägar som systemet använder, även om det, som i alla studier som involverar hjärnan, finns en lång väg att gå.

Många populära tillämpningar för datorseende innebär att man försöker känna igen saker i fotografier, till exempel:
- Objektklassificering:
- Identifiering av objekt:
- Verifiering av objekt: Vilken typ av ett visst objekt finns i det här fotografiet?
- Verifiering av objekt: Finns objektet i fotografiet?
- Objektdetektering: Var finns föremålen i fotografiet?
- Objektdetektering av landmärken: Vilka är de viktigaste punkterna för objektet i fotografiet?
- Segmentering av objekt: Vilka pixlar hör till objektet i bilden?
- Objektigenkänning: Vilka objekt finns på det här fotografiet och var finns de?
Outom igenkänning finns det andra analysmetoder:
- Vid analys av videorörelser används datorseende för att uppskatta hastigheten hos objekten i en video eller kameran själv.
- Vid bildsegmentering delar algoritmerna upp bilderna i flera olika uppsättningar av vyer.
- Vid rekonstruktion av en scen skapas en 3D-modell av en scen som matas in med hjälp av bilder eller video.
- I bildrestaurering avlägsnas brus, t.ex. oskärpa, från foton med hjälp av maskininlärningsbaserade filter.
Alla andra tillämpningar som innebär att man förstår pixlar med hjälp av mjukvara kan säkert betecknas som datorseende.
Slutsats
Trots de senaste framstegen, som har varit imponerande, är vi fortfarande inte ens i närheten av att lösa datorseende. Det finns dock redan flera vårdinrättningar och företag som har hittat sätt att tillämpa CV-system, som drivs av CNN, på verkliga problem. Och den här trenden kommer sannolikt inte att upphöra inom den närmaste tiden.
Om du vill komma i kontakt med mig och förresten vet ett bra skämt kan du ta kontakt med mig på Twitter eller LinkedIn.
Tack för att du läste!😄 🙌
.