„74 % der Unternehmen sagen, dass sie „datengesteuert“ sein wollen, aber nur 29 % sagen, dass sie gut darin sind, Analysen mit Maßnahmen zu verbinden.“ – Forrester
Statistiken und Daten erstellen, verarbeiten und weitergeben – machen diese Handlungen Sie zu einem „datengesteuerten“ Unternehmen?
Sicherlich tun sie das, aber wenn die Daten und Statistiken, die Ihren Entscheidungen zugrunde liegen, ungenau oder völlig falsch sind, können die daraus resultierenden negativen Ergebnisse zu Verwirrung und schlechter Leistung führen.
Glaubwürdige Daten beseitigen die beängstigende Aussicht, sich auf launische Vermutungen und „Bauchgefühl“ zu verlassen. Sie kombinieren menschliche Erfahrung und Intuition mit konkreten Zahlen und Analysen, um Entscheidungen zu treffen, die den Ausschlag geben können.
Intuitive Dashboards, Diagramme, Statistiken und Grafiken verdecken jedoch oft eine falsche Realität:
Fehlleitende Statistiken und Daten.
Da sich die Technologie schnell weiterentwickelt und die Benutzer sich in gleichem Maße anpassen, sind Unternehmen auf Daten und Statistiken angewiesen, um sich in einem wettbewerbsorientierten Geschäftsumfeld zurechtzufinden.
Aber es ist leicht, sich von der Absolutheit der Zahlen blenden zu lassen, vor allem, wenn sie günstigen Hypothesen oder Argumenten Glaubwürdigkeit verleihen.
Falsche Statistiken und Daten zu erkennen, ist eine Gefahr für die datengestützte Entscheidungsfindung.
Es verleitet dazu, voller Vertrauen die sprichwörtlich falschen Knöpfe zu drücken, und genau darin liegt die Gefahr.
In diesem Beitrag erfahren Sie, wie Sie irreführende Statistiken und Daten erkennen können. Wir schauen uns an, wie sie häufig in die Irre führen und wie man feststellt, wann Daten das Gewicht kritischer Entscheidungen tragen können.
- Was ist eine irreführende Statistik?
- Selektive Voreingenommenheit zur Erstellung falscher Statistiken
- Vernachlässigte Stichprobengröße führt zu falscher Präzision
- Fehlerhafte Korrelationen und Kausalitäten führen zu falschen Statistiken
- Missverständliche Diagramme und Grafiken
- Schluss: Schutz vor irreführenden Daten und Statistiken
- Über den Autor
Was ist eine irreführende Statistik?
Quelle
Eine irreführende Statistik entsteht, wenn ein Fehler – absichtlich oder nicht – in einem der 3 Hauptaspekte der Forschung vorliegt:
-
Erhebung: Verwendung kleiner Stichprobengrößen, die große Zahlen projizieren, aber wenig statistische Bedeutung haben.
-
Organisieren: Auslassen von Ergebnissen, die dem Punkt widersprechen, den der Forscher zu beweisen versucht.
-
Präsentieren: Manipulation visueller/numerischer Daten, um die Wahrnehmung zu beeinflussen.
Schlechte Statistiken schleichen sich in Nachrichten, Werbekampagnen und sogar in der wissenschaftlichen Literatur ein. Schockierende 33,7 % der Wissenschaftler – die Superlative der Datenneutralität – haben zugegeben, Statistiken zur Unterstützung ihrer Forschung missbraucht zu haben. Ja, sogar einige der vertrauenswürdigen Informationshüter der Gesellschaft haben sich schuldig gemacht.
Um Ihnen zu helfen, kritische Entscheidungen auf der Grundlage der richtigen Daten zu treffen, haben wir die häufigsten Arten aufgelistet, wie Statistiken irreführen und falsch informieren.
Selektive Voreingenommenheit zur Erstellung falscher Statistiken
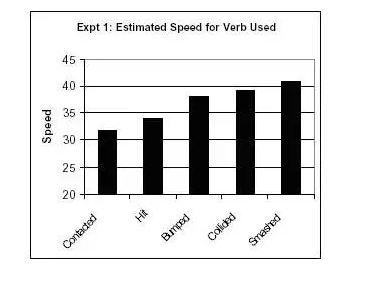
Eine Studie von Elizabeth Loftus untersuchte den Einfluss von Sprache auf Augenzeugenaussagen. Den Probanden wurde ein Film gezeigt, in dem mehrere Autounfälle dargestellt waren. Nachdem sie den Film gesehen hatten, wurden sie gefragt: „Wie schnell fuhren die Autos, als sie ineinander krachten?“
Anderen Versuchspersonen wurde dann die gleiche Frage gestellt, wobei das Wort „zusammengestoßen“ durch suggestive Verben ersetzt wurde:
-
Kontaktiert
-
Gestoßen
-
Angestoßen
-
Zusammengestoßen
Das Ergebnis?
Je stärker das verwendete „geladene“ Verb war, desto höher war die von den Zeugen geschätzte Geschwindigkeit.
Quelle
Die Studie ergab außerdem, dass die Probanden bei Verwendung eines stärkeren Verbs mit größerer Wahrscheinlichkeit von Glasscherben am Unfallort berichteten, auch wenn im Video keine Glasscherben zu sehen waren.
Die Verwendung von Sprache zur Beeinflussung von Umfrageantworten und -ergebnissen ist nur ein Beispiel für Selektionsverzerrungen. Im Jahr 2007 zwang die Advertising Standards Authority (ASA) Colgate, die Behauptung „über 80 % der Zahnärzte empfehlen die Verwendung von Colgate“ aufzugeben, weil die Behauptung irreführenderweise implizierte, dass „80 % der Zahnärzte Colgate-Zahnpasta vor allen anderen Marken empfehlen“.
Die eigentliche Frage lautete: „Wenn Sie die Wahl hätten zwischen alleinigem Zähneputzen und der Verwendung einer Zahnpasta – wie Colgate – welche würden Sie empfehlen?“
Durch das Herauspicken der Umfrageergebnisse hat Colgate den Eindruck erweckt, dass Zahnärzte Colgate gegenüber den Marken der Konkurrenz empfehlen; die tatsächliche Empfehlung lautete, dass die Verwendung einer beliebigen Zahnpasta dem alleinigen Zähneputzen überlegen ist.
Selektive Verzerrungen treten häufig auf, wenn ausgewählte Stichproben oder Daten unvollständig oder herausgepickt sind, um die Wahrnehmung von Statistiken und Daten zu beeinflussen oder sogar zu verfälschen.
Vernachlässigte Stichprobengröße führt zu falscher Präzision

(Quelle)
90 Personen, die von 100 Personen mit „Ja“ antworten (90 %), im Vergleich zu 900 Personen, die von 1000 Personen mit „Ja“ antworten (ebenfalls 90 %); die Prozentsätze sind ähnlich, aber der Unterschied im Wert und in der Gültigkeit der Daten ist statistisch signifikant.
Kleine Stichprobengrößen garantieren fast immer alarmierend signifikante Ergebnisse. Hüten Sie sich immer vor extremen Ergebnissen und akzeptieren Sie niemals Prozentzahlen für bare Münze. Mit den Worten der Biochemie-Forscherin Ana-maria Sundic:
„Um sicherzustellen, dass die Stichprobe repräsentativ für eine Population ist, sollte die Stichprobe zufällig sein, d.h. jedes Subjekt muss die gleiche Wahrscheinlichkeit haben, in die Studie aufgenommen zu werden. Es ist zu beachten, dass Stichprobenverzerrungen auch dann auftreten können, wenn die Stichprobe zu klein ist, um die Zielpopulation zu repräsentieren.“
Fehlerhafte Korrelationen und Kausalitäten führen zu falschen Statistiken
„Korrelation bedeutet nicht Kausalität“.
Diesen Satz haben Sie sicher schon einmal gehört, aber er ist aus gutem Grund wahr.
Wenn zwei Variablen miteinander korrelieren, gilt in der Regel Folgendes:
-
Y verursacht X.
-
X verursacht Y.
-
Ein dritter Faktor löst X + Y aus.
-
Die Korrelation ist auf Zufall zurückzuführen.
Korrelation und Kausalität sind sehr verdächtig, denn Forscher – und die Konsumenten dieser Forschung – werden Opfer von:
-Zahlenfetischismus
-Korrelationsjagd
Tyler Vegihn hat einige lustige Beispiele für irreführende Statistiken zusammengestellt, um genau das zu beweisen:
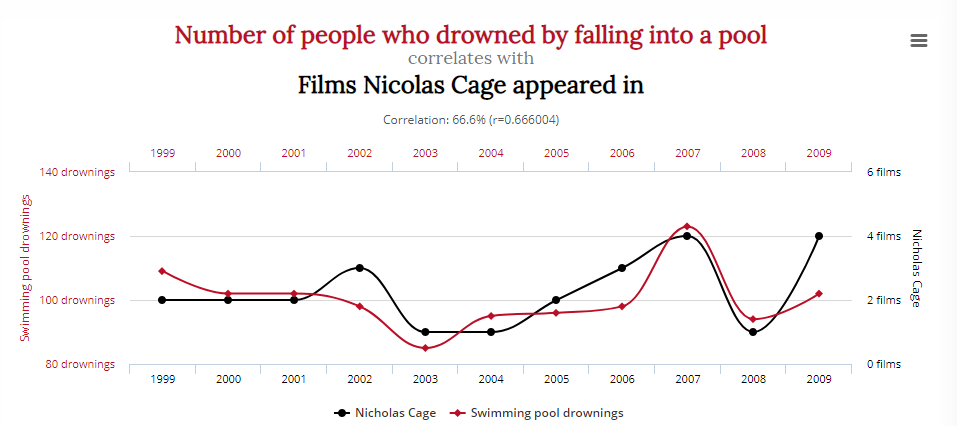
Dieses Diagramm zeigt eine zwingende Korrelation zwischen der Anzahl der Menschen, die beim Sturz in einen Pool ertrunken sind, und der Anzahl der Filme, in denen Nicolas Cage mitgespielt hat:
Eine andere zeigt eine Korrelation zwischen der Anzahl der Menschen, die sich in Bettlaken verfangen haben, und dem Käsekonsum:
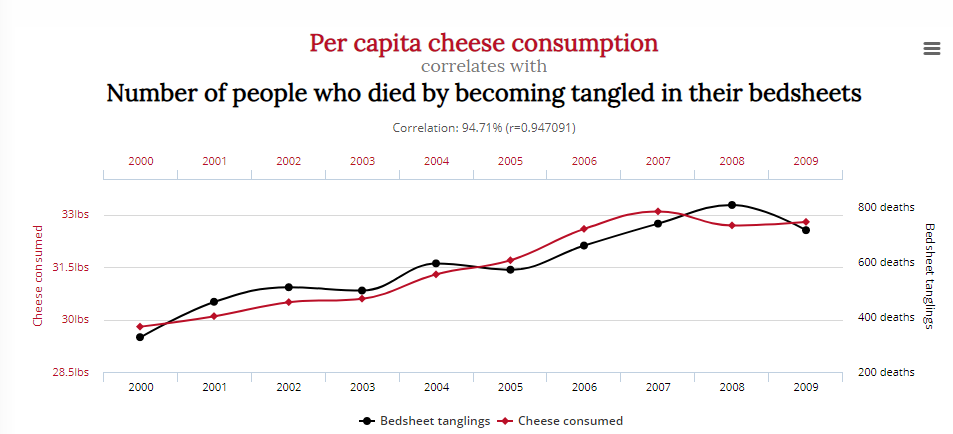
Bedeutet dies, dass eine Reduzierung des Käsekonsums und der Schauspielrollen von Nicolas Cage Leben retten wird? Wahrscheinlich nicht.
Da Forscher unter Druck stehen, nützliche Daten zu entdecken oder eine Hypothese zu beweisen, ist die Versuchung groß, vorschnell einen „Aha“- oder „Heureka“-Moment zu verkünden.
Dies stellt ein Problem für gesunde Analysen und Statistiken dar; wenn man genügend Variablen einbezieht, ist es fast garantiert, dass man eine Korrelation mit irgendetwas findet.
Missverständliche Diagramme und Grafiken
Datenvisualisierungen verwandeln rohe Zahlen in visuelle Darstellungen von Schlüsselbeziehungen, Trends und Mustern. Sie können Daten zum Leben erwecken, sind aber auch ein beliebtes Medium für irreführende Statistiken und Daten.
In seinem Buch „Graphics, Lies, Misleading Visuals“ (Grafiken, Lügen, irreführendes Bildmaterial) entlarvt der Datenjournalist Alberto Cairo irreführende statistische Beispiele aus der Marketingwerbung, politischen Kampagnen und der Nachrichtenberichterstattung.
Ein beliebtes Beispiel aus den Nachrichten ist der Fall Terri Schiavo, ein Rechtsstreit um das Recht auf Sterbehilfe in den USA.
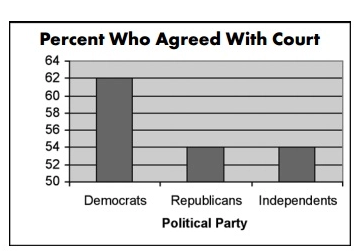
Während des Falles wurde ein Diagramm wie das folgende von CNN verwendet, um darzustellen, wie verschiedene politische Gruppen über die Entfernung von Terris lebenserhaltenden Maßnahmen dachten:
Quelle
Ein Blick auf dieses Diagramm lässt vermuten, dass im Vergleich zu Republikanern und Unabhängigen dreimal mehr Demokraten dem Gericht zustimmten
Bei näherer Betrachtung zeigt sich jedoch ein kleiner Unterschied von 14 % bei den Stimmen.
Das abgeschnittene Diagramm und die manipulierte Y-Achse (beginnend bei 50 statt bei 0) verzerren die Daten und verleiten dazu, eine übertriebene Vorstellung von einer bestimmten Gruppe zu haben.
Vermeiden Sie es, beim Betrachten von Diagrammen und visuellen Darstellungen in die Irre geführt zu werden, indem Sie auf Folgendes achten:
-
Das Fehlen der Grundlinie oder der abgeschnittenen Achse in einem Diagramm.
-
Die Intervalle und Skalen. Prüfen Sie auf ungleiche Abstufungen und ungerade Messungen (Verwendung von Zahlen anstelle von Prozentsätzen usw.).
-
Der vollständige Kontext und andere vergleichende Diagramme, um zu sehen, wie ähnliche Daten gemessen und dargestellt werden.
Schluss: Schutz vor irreführenden Daten und Statistiken
Missverständliche Statistiken und Daten prahlen mit grandiosen Conversion-Rate-Verbesserungen durch „CTA-Tweaks“ und „einfache Farbänderungen“.
Sie sorgen für schockierende Schlagzeilen, die Schwärme von Besuchern anlocken, aber bestenfalls fehlerhafte Erkenntnisse liefern.
Schlechte Statistiken und Daten sind gefährlich.
Anstatt Ihnen dabei zu helfen, Umwege, Schlaglöcher und Fallstricke zu überwinden, steuern sie Sie wissentlich – oder unwissentlich – genau in diese hinein. Aber Sie sind klug genug, sie zu erkennen.
Wenn Sie das nächste Mal auf überzeugende Daten stoßen, sollten Sie sich diese einfachen, aber wirkungsvollen Fragen stellen:
Wer führt die Forschung durch?
Forschung ist teuer und zeitaufwändig. Prüfen Sie, wer sie sponsert, wägen Sie deren Voreingenommenheit gegenüber dem Thema ab und wie sie von den Ergebnissen profitieren könnten. Handelt es sich um ein B2C-Unternehmen mit einem Produkt? Ein Beratungsdienst? Handelt es sich um eine unabhängige, von einer Universität finanzierte Studie?
Kann man Stichprobengröße und Studiendauer ernst nehmen?
Eine Überprüfung der unterstützenden oder verschleierten Zahlen wird eine schwache statistische Stärke aufdecken.
Werden die Daten visuell angemessen dargestellt?
Sind die Skalen und Intervalle gleichmäßig und neutral? Unterstreicht eine Statistik eine bestimmte Idee oder Agenda? Gibt es zu viele Kennzahlen in Ihrem Dashboard?
Wird die Forschung ehrlich und unparteiisch dargestellt?
Überprüfen Sie die verwendete Sprache, die Art und Weise, wie die Frage formuliert ist, und die befragten Personen.
Um zu verhindern, dass irreführende Statistiken und Daten Ihre Dashboards, Berichte und Analysen verunreinigen, sollten Sie neuen Informationen mit einer neugierigen und skeptischen Haltung begegnen.
Über den Autor
Hassan Uddeen ist ein in Großbritannien ansässiger freiberuflicher Autor für B2B-, SaaS- und Fintech-Unternehmen. Er liebt alles, was mit Content Marketing zu tun hat. Wenn er sich von der Tastatur losreißen kann, hüpft er gerne in seinem heimischen Fitnessstudio herum (und spielt dabei ein Rollenspiel als Goku) und vertieft sich in einen guten James Patterson-Roman.