- Zobacz, dlaczego to takie niesamowite.
- Ewolucja widzenia komputerowego
- How Long Does It Take To Decipher An Image
- Zastosowania widzenia komputerowego
- Wizja komputerowa w samochodach samojezdnych
- CV W rozpoznawaniu twarzy
- CV W rzeczywistości rozszerzonej &Rzeczywistość mieszana
- CV W opiece zdrowotnej
- Wyzwania wizji komputerowej
- Wniosek
Zobacz, dlaczego to takie niesamowite.
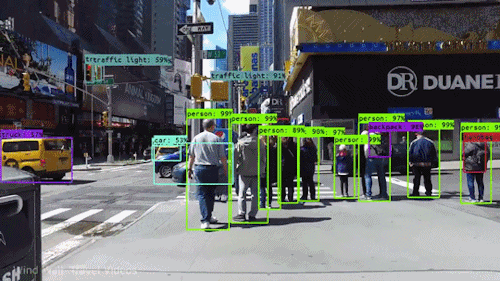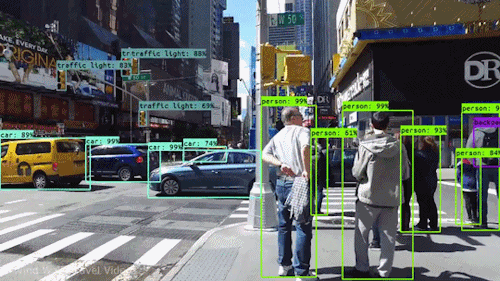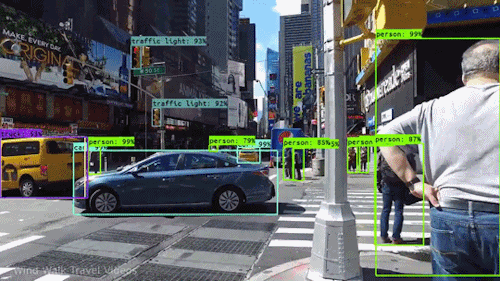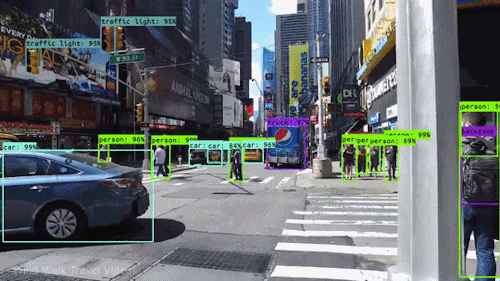
Jednym z najpotężniejszych i najbardziej fascynujących rodzajów sztucznej inteligencji jest wizja komputerowa, której prawie na pewno doświadczyłeś na wiele sposobów, nawet o tym nie wiedząc. Oto spojrzenie na to, co to jest, jak działa i dlaczego jest tak niesamowite (i będzie tylko coraz lepiej).
Wizja komputerowa to dziedzina informatyki, która koncentruje się na replikowaniu części złożoności ludzkiego systemu wizyjnego i umożliwieniu komputerom identyfikowania i przetwarzania obiektów na obrazach i wideo w taki sam sposób, jak robią to ludzie. Do niedawna widzenie komputerowe działało tylko w ograniczonym zakresie.
Dzięki postępom w dziedzinie sztucznej inteligencji oraz innowacjom w zakresie głębokiego uczenia się i sieci neuronowych, w ostatnich latach dziedzina ta była w stanie wykonać wielkie skoki i była w stanie przewyższyć ludzi w niektórych zadaniach związanych z wykrywaniem i oznaczaniem obiektów.
Jednym z czynników napędzających wzrost wizji komputerowej jest ilość danych, które generujemy dzisiaj, a które są następnie wykorzystywane do szkolenia i uczynienia wizji komputerowej lepszej.

Wraz z ogromną ilością danych wizualnych (ponad 3 miliardy obrazów jest udostępnianych online każdego dnia), moc obliczeniowa wymagana do analizy tych danych jest teraz dostępna. Wraz z rozwojem dziedziny wizji komputerowej, dzięki nowemu sprzętowi i algorytmom, wzrosła również dokładność identyfikacji obiektów. W mniej niż dekadę dzisiejsze systemy osiągnęły 99-procentową dokładność z 50 procent, co czyni je dokładniejszymi od ludzi w szybkim reagowaniu na bodźce wizualne.
Wczesne eksperymenty w dziedzinie wizji komputerowej rozpoczęły się w latach 50. ubiegłego wieku, a po raz pierwszy zastosowano ją komercyjnie do rozróżniania tekstu pisanego na maszynie i odręcznie w latach 70.
Do 2022 r. oczekuje się, że rynek wizji komputerowej i sprzętu osiągnie wartość 48,6 mld USD
Jednym z głównych otwartych pytań zarówno w neuronauce, jak i uczeniu maszynowym jest: jak dokładnie działają nasze mózgi i jak możemy to przybliżyć za pomocą naszych własnych algorytmów? Rzeczywistość jest taka, że istnieje bardzo niewiele działających i kompleksowych teorii obliczeń mózgu; więc pomimo faktu, że sieci neuronowe mają „naśladować sposób działania mózgu”, nikt nie jest do końca pewien, czy to rzeczywiście prawda.
Ten sam paradoks dotyczy wizji komputerowej – ponieważ nie jesteśmy zdecydowani, jak mózg i oczy przetwarzają obrazy, trudno jest powiedzieć, jak dobrze algorytmy używane w produkcji przybliżają nasze wewnętrzne procesy umysłowe.
Na pewnym poziomie wizja komputerowa polega na rozpoznawaniu wzorców. Tak więc jednym ze sposobów trenowania komputera, jak zrozumieć dane wizualne, jest podawanie mu obrazów, wielu obrazów, tysięcy, milionów, jeśli to możliwe, które zostały opatrzone etykietami, a następnie poddawanie ich różnym technikom programowym lub algorytmom, które pozwalają komputerowi polować na wzorce we wszystkich elementach, które odnoszą się do tych etykiet.
So, na przykład, jeśli karmić komputer milion zdjęć kotów (wszyscy je kochamy😄😹), będzie poddać je wszystkie do algorytmów, które pozwalają im analizować kolory na zdjęciu, kształty, odległości między kształtami, gdzie obiekty graniczą ze sobą, i tak dalej, tak, że identyfikuje profil co „kot” oznacza. Kiedy to się skończy, komputer będzie (w teorii) w stanie wykorzystać swoje doświadczenie, jeśli karmione innych nieznakowanych obrazów, aby znaleźć te, które są z cat.
Zostawmy naszych puszystych przyjaciół kotów na chwilę na boku i niech się bardziej techniczne🤔😹. Poniżej znajduje się prosta ilustracja bufora obrazu w skali szarości, który przechowuje nasz obraz Abrahama Lincolna. Jasność każdego piksela jest reprezentowana przez pojedynczą 8-bitową liczbę, której zakres wynosi od 0 (czarny) do 255 (biały):

W rzeczywistości wartości pikseli są niemal powszechnie przechowywane, na poziomie sprzętowym, w tablicy jednowymiarowej. Na przykład, dane z powyższego obrazu są przechowywane w sposób podobny do tej długiej listy unsigned chars:
{157, 153, 174, 168, 150, 152, 129, 151, 172, 161, 155, 156,
155, 182, 163, 74, 75, 62, 33, 17, 110, 210, 180, 154,
180, 180, 50, 14, 34, 6, 10, 33, 48, 106, 159, 181,
206, 109, 5, 124, 131, 111, 120, 204, 166, 15, 56, 180,
194, 68, 137, 251, 237, 239, 239, 228, 227, 87, 71, 201,
172, 105, 207, 233, 233, 214, 220, 239, 228, 98, 74, 206,
188, 88, 179, 209, 185, 215, 211, 158, 139, 75, 20, 169,
189, 97, 165, 84, 10, 168, 134, 11, 31, 62, 22, 148,
199, 168, 191, 193, 158, 227, 178, 143, 182, 106, 36, 190,
205, 174, 155, 252, 236, 231, 149, 178, 228, 43, 95, 234,
190, 216, 116, 149, 236, 187, 86, 150, 79, 38, 218, 241,
190, 224, 147, 108, 227, 210, 127, 102, 36, 101, 255, 224,
190, 214, 173, 66, 103, 143, 96, 50, 2, 109, 249, 215,
187, 196, 235, 75, 1, 81, 47, 0, 6, 217, 255, 211,
183, 202, 237, 145, 0, 0, 12, 108, 200, 138, 243, 236,
195, 206, 123, 207, 177, 121, 123, 200, 175, 13, 96, 218};
Ten sposób przechowywania danych obrazu może być sprzeczny z Twoimi oczekiwaniami, ponieważ dane z pewnością wydają się być dwuwymiarowe, gdy są wyświetlane. A jednak tak jest, ponieważ pamięć komputerowa składa się po prostu z coraz większej liniowej listy przestrzeni adresowych.

Powróćmy jeszcze raz do pierwszego obrazka i wyobraźmy sobie dodanie kolorowego. Teraz sprawy zaczynają się robić bardziej skomplikowane. Komputery zazwyczaj odczytują kolor jako serię 3 wartości – czerwonej, zielonej i niebieskiej (RGB) – w tej samej skali 0-255. Teraz każdy piksel ma trzy wartości, które komputer musi przechowywać oprócz swojej pozycji. Gdybyśmy mieli pokolorować prezydenta Lincolna, dałoby to 12 x 16 x 3 wartości, czyli 576 liczb.

To dużo pamięci wymaganej dla jednego obrazu i dużo pikseli, nad którymi algorytm może iterować. Ale aby wytrenować model ze znaczącą dokładnością, zwłaszcza gdy mówisz o głębokim uczeniu się, zwykle potrzebujesz dziesiątek tysięcy obrazów, a im więcej, tym lepiej.
Ewolucja widzenia komputerowego
Przed pojawieniem się głębokiego uczenia się zadania, które może wykonywać widzenie komputerowe, były bardzo ograniczone i wymagały dużo ręcznego kodowania oraz wysiłku programistów i ludzkich operatorów. Na przykład, gdybyś chciał wykonać rozpoznawanie twarzy, musiałbyś wykonać następujące kroki:
- Utwórz bazę danych: Musiałeś przechwycić indywidualne obrazy wszystkich obiektów, które chciałeś śledzić, w określonym formacie.
- Opatrzenie obrazów adnotacjami: Następnie dla każdego indywidualnego obrazu musiałbyś wprowadzić kilka kluczowych punktów danych, takich jak odległość między oczami, szerokość mostka nosowego, odległość między górną wargą a nosem oraz dziesiątki innych pomiarów, które definiują unikalne cechy każdej osoby.
- Przechwytywanie nowych obrazów: Następnie trzeba by było uchwycić nowe obrazy, czy to ze zdjęć czy treści wideo. I wtedy musiałbyś ponownie przejść przez proces pomiaru, zaznaczając kluczowe punkty na obrazie. Musiałeś również wziąć pod uwagę kąt, pod jakim zdjęcie zostało zrobione.
Po całej tej ręcznej pracy, aplikacja w końcu byłaby w stanie porównać pomiary na nowym zdjęciu z tymi przechowywanymi w bazie danych i powiedzieć Ci, czy odpowiadało ono któremuś z profili, które śledziła. W rzeczywistości, automatyzacja była bardzo niewielka, a większość pracy wykonywana była ręcznie. A margines błędu wciąż był duży.
Uczenie maszynowe zapewniło inne podejście do rozwiązywania problemów związanych z widzeniem komputerowym. Dzięki uczeniu maszynowemu programiści nie musieli już ręcznie kodować każdej pojedynczej reguły w swoich aplikacjach wizyjnych. Zamiast tego programowali „funkcje”, mniejsze aplikacje, które mogły wykrywać określone wzorce w obrazach. Następnie używali algorytmów uczenia statystycznego, takich jak regresja liniowa, regresja logistyczna, drzewa decyzyjne lub maszyny wektorów wspierających (SVM) do wykrywania wzorców i klasyfikowania obrazów oraz wykrywania na nich obiektów.
Uczenie maszynowe pomogło rozwiązać wiele problemów, które historycznie stanowiły wyzwanie dla klasycznych narzędzi i podejść do tworzenia oprogramowania. Na przykład, lata temu, inżynierowie uczenia maszynowego byli w stanie stworzyć oprogramowanie, które mogło przewidzieć okna przeżycia raka piersi lepiej niż ludzcy eksperci. Jednak zbudowanie funkcji tego oprogramowania wymagało wysiłku dziesiątek inżynierów i ekspertów od raka piersi i zajęło dużo czasu.
Głębokie uczenie zapewniło zasadniczo inne podejście do uczenia maszynowego. Głębokie uczenie opiera się na sieciach neuronowych, funkcji ogólnego przeznaczenia, która może rozwiązać każdy problem reprezentowalny przez przykłady. Gdy dostarczysz sieci neuronowej wiele oznaczonych przykładów określonego rodzaju danych, będzie ona w stanie wyodrębnić wspólne wzorce między tymi przykładami i przekształcić je w równanie matematyczne, które pomoże sklasyfikować przyszłe fragmenty informacji.
Na przykład, tworzenie aplikacji do rozpoznawania twarzy z głębokim uczeniem wymaga tylko opracowania lub wybrania wstępnie skonstruowanego algorytmu i wytrenowania go z przykładami twarzy osób, które musi wykryć. Biorąc pod uwagę wystarczającą liczbę przykładów (dużo przykładów), sieć neuronowa będzie w stanie wykryć twarze bez dalszych instrukcji dotyczących cech lub pomiarów.
Głębokie uczenie jest bardzo skuteczną metodą wykonywania wizji komputerowej. W większości przypadków stworzenie dobrego algorytmu głębokiego uczenia sprowadza się do zebrania dużej ilości etykietowanych danych treningowych i dostrojenia parametrów, takich jak typ i liczba warstw sieci neuronowych oraz epok treningowych. W porównaniu z poprzednimi typami uczenia maszynowego, głębokie uczenie jest zarówno łatwiejsze, jak i szybsze do opracowania i wdrożenia.
Większość obecnych aplikacji widzenia komputerowego, takich jak wykrywanie raka, samochody samojezdne i rozpoznawanie twarzy, korzysta z głębokiego uczenia. Głębokie uczenie i głębokie sieci neuronowe przeniosły się ze sfery koncepcyjnej do praktycznych zastosowań dzięki dostępności i postępom w zakresie sprzętu i zasobów obliczeniowych w chmurze.
How Long Does It Take To Decipher An Image
W skrócie niewiele. To właśnie klucz do tego, dlaczego wizja komputerowa jest tak porywająca: Podczas gdy w przeszłości nawet superkomputery mogły potrzebować dni, tygodni, a nawet miesięcy, aby wykonać wszystkie wymagane obliczenia, dzisiejsze ultraszybkie układy scalone i powiązany z nimi sprzęt, wraz z szybkim, niezawodnym Internetem i sieciami w chmurze, czynią ten proces błyskawicznym. Jednym z kluczowych czynników jest gotowość wielu dużych firm prowadzących badania nad AI do dzielenia się swoją pracą Facebook, Google, IBM i Microsoft, zwłaszcza poprzez otwarte udostępnianie niektórych z ich prac związanych z uczeniem maszynowym.
Pozwala to innym bazować na ich pracy, zamiast zaczynać od zera. W rezultacie, przemysł AI gotuje się, a eksperymenty, które nie tak dawno temu trwały tygodniami, dziś mogą trwać 15 minut. A dla wielu zastosowań widzenia komputerowego w świecie rzeczywistym, proces ten odbywa się w sposób ciągły w ciągu mikrosekund, tak że komputer jest dziś w stanie być tym, co naukowcy nazywają „sytuacyjnie świadomy.”
Zastosowania widzenia komputerowego
Wizja komputerowa jest jednym z obszarów uczenia maszynowego, gdzie podstawowe koncepcje są już zintegrowane z głównymi produktami, z których korzystamy na co dzień.
Wizja komputerowa w samochodach samojezdnych
Ale nie tylko firmy technologiczne wykorzystują uczenie maszynowe do zastosowań związanych z obrazem.
Wizja komputerowa umożliwia samochodom samojezdnym zrozumienie otoczenia. Kamery rejestrują obraz z różnych kątów wokół samochodu i przekazują go do oprogramowania komputerowego, które następnie przetwarza obrazy w czasie rzeczywistym, aby znaleźć krańce dróg, odczytać znaki drogowe, wykryć inne samochody, obiekty i pieszych. Samojeżdżący samochód może wtedy kierować się na ulicach i autostradach, unikać przeszkód i (miejmy nadzieję) bezpiecznie dowieźć swoich pasażerów do celu.
CV W rozpoznawaniu twarzy
Wizja komputerowa odgrywa również ważną rolę w aplikacjach rozpoznawania twarzy, technologii, która umożliwia komputerom dopasowanie obrazów twarzy ludzi do ich tożsamości. Algorytmy wizji komputerowej wykrywają cechy twarzy na obrazach i porównują je z bazami danych profili twarzy. Urządzenia konsumenckie wykorzystują rozpoznawanie twarzy do uwierzytelniania tożsamości swoich właścicieli. Aplikacje mediów społecznościowych wykorzystują rozpoznawanie twarzy do wykrywania i oznaczania użytkowników. Organy ścigania również polegają na technologii rozpoznawania twarzy w celu identyfikacji przestępców w kanałach wideo.
CV W rzeczywistości rozszerzonej &Rzeczywistość mieszana
Wizja komputerowa odgrywa również ważną rolę w rzeczywistości rozszerzonej i mieszanej, technologii, która umożliwia urządzeniom komputerowym, takim jak smartfony, tablety i inteligentne okulary, nakładanie i osadzanie wirtualnych obiektów na obrazach świata rzeczywistego. Wykorzystując widzenie komputerowe, sprzęt AR wykrywa obiekty w świecie rzeczywistym w celu określenia miejsc na wyświetlaczu urządzenia, w których można umieścić wirtualny obiekt. Na przykład algorytmy widzenia komputerowego mogą pomóc aplikacjom AR w wykrywaniu płaszczyzn, takich jak blaty, ściany i podłogi, co stanowi bardzo ważną część ustalania głębi i wymiarów oraz umieszczania wirtualnych obiektów w świecie fizycznym.
CV W opiece zdrowotnej
Wizja komputerowa była również ważną częścią postępów w technologii zdrowotnej. Algorytmy wizji komputerowej mogą pomóc w automatyzacji zadań, takich jak wykrywanie rakowych pieprzyków na obrazach skóry lub wyszukiwanie objawów na skanach rentgenowskich i MRI.
Wyzwania wizji komputerowej
Pomaganie komputerom w widzeniu okazuje się bardzo trudne.
Wynalezienie maszyny, która widzi tak jak my, jest zwodniczo trudnym zadaniem, nie tylko dlatego, że trudno jest zmusić komputery do tego, ale dlatego, że nie jesteśmy do końca pewni, jak w ogóle działa ludzka wizja.
Badanie biologicznej wizji wymaga zrozumienia organów percepcyjnych, takich jak oczy, a także interpretacji percepcji w mózgu. Poczyniono znaczne postępy, zarówno w wykreślaniu tego procesu, jak i w odkrywaniu sztuczek i skrótów stosowanych przez system, choć jak w przypadku każdego badania, które dotyczy mózgu, jest jeszcze długa droga do przebycia.

Wiele popularnych zastosowań widzenia komputerowego polega na próbach rozpoznawania rzeczy na zdjęciach; na przykład:
- Klasyfikacja obiektów: Jaka szeroka kategoria obiektów znajduje się na tym zdjęciu?
- Identyfikacja obiektów: Jaki typ danego obiektu znajduje się na tym zdjęciu?
- Weryfikacja obiektu: Czy dany obiekt znajduje się na zdjęciu?
- Wykrywanie obiektów: Gdzie znajdują się obiekty na fotografii?
- Object Landmark Detection: Jakie są kluczowe punkty dla obiektu na fotografii?
- Segmentacja obiektu: Jakie piksele należą do obiektu na zdjęciu?
- Rozpoznawanie obiektów: Jakie obiekty znajdują się na tym zdjęciu i gdzie?
Oprócz samego rozpoznawania inne metody analizy obejmują:
- Analiza ruchu w wideo wykorzystuje widzenie komputerowe do szacowania prędkości obiektów w wideo lub samej kamery.
- W segmentacji obrazu algorytmy dzielą obrazy na wiele zestawów widoków.
- Rekonstrukcja sceny tworzy trójwymiarowy model sceny wprowadzony za pomocą obrazów lub wideo.
- W przywracaniu obrazu, szumy, takie jak rozmycie, są usuwane ze zdjęć za pomocą filtrów opartych na uczeniu maszynowym.
Każda inna aplikacja, która obejmuje zrozumienie pikseli za pomocą oprogramowania, może być bezpiecznie oznaczona jako wizja komputerowa.
Wniosek
Mimo ostatnich postępów, które były imponujące, nadal nie jesteśmy nawet blisko rozwiązania wizji komputerowej. Jednak już teraz wiele instytucji opieki zdrowotnej i przedsiębiorstw znalazło sposoby na zastosowanie systemów CV, zasilanych przez CNN, do rozwiązywania rzeczywistych problemów. I ten trend raczej nie zatrzyma się w najbliższym czasie.
Jeśli chcesz się ze mną skontaktować, a przy okazji znasz dobry dowcip, możesz się ze mną skontaktować na Twitterze lub LinkedIn.
Dzięki za przeczytanie!😄 🙌