- Voici un aperçu de pourquoi c’est si génial.
- L’évolution de la vision par ordinateur
- Combien de temps faut-il pour déchiffrer une image
- Applications de la vision par ordinateur
- Vision par ordinateur dans les voitures autopilotées
- CV Dans la reconnaissance faciale
- CV Dans la réalité augmentée &Réalité mixte
- CV dans les soins de santé
- Défis de la vision par ordinateur
- Conclusion
Voici un aperçu de pourquoi c’est si génial.
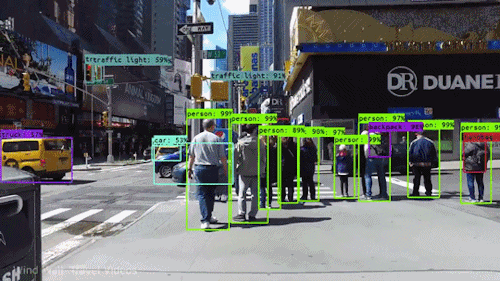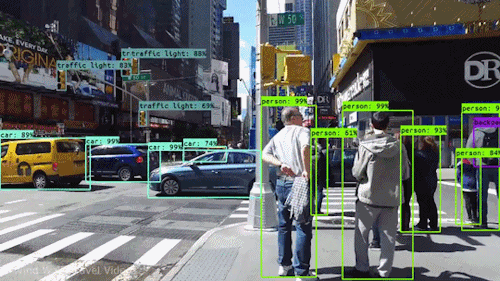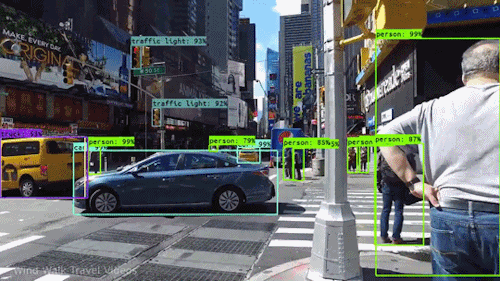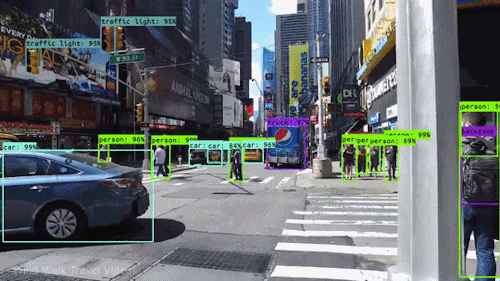
L’un des types d’IA les plus puissants et les plus convaincants est la vision par ordinateur, que vous avez presque certainement expérimentée de nombreuses façons sans même le savoir. Voici un aperçu de ce que c’est, comment cela fonctionne et pourquoi c’est si génial (et ne fera que s’améliorer).
La vision par ordinateur est le domaine de l’informatique qui se concentre sur la reproduction de certaines parties de la complexité du système de vision humain et permet aux ordinateurs d’identifier et de traiter les objets dans les images et les vidéos de la même manière que les humains. Jusqu’à récemment, la vision par ordinateur ne fonctionnait que de manière limitée.
Grâce aux progrès de l’intelligence artificielle et aux innovations dans l’apprentissage profond et les réseaux neuronaux, le domaine a pu faire de grands bonds ces dernières années et a pu dépasser les humains dans certaines tâches liées à la détection et à l’étiquetage des objets.
L’un des facteurs moteurs de la croissance de la vision par ordinateur est la quantité de données que nous générons aujourd’hui et qui sont ensuite utilisées pour former et améliorer la vision par ordinateur.

A côté d’une énorme quantité de données visuelles (plus de 3 milliards d’images sont partagées en ligne chaque jour), la puissance de calcul nécessaire pour analyser ces données est désormais accessible. Le domaine de la vision par ordinateur s’est enrichi de nouveaux matériels et algorithmes, tout comme les taux de précision de l’identification des objets. En moins d’une décennie, les systèmes d’aujourd’hui ont atteint une précision de 99 % à partir de 50 %, ce qui les rend plus précis que les humains pour réagir rapidement aux entrées visuelles.
Les premières expériences de la vision par ordinateur ont commencé dans les années 1950 et elle a été mise à profit commercialement pour distinguer les textes dactylographiés et manuscrits dans les années 1970, aujourd’hui les applications de la vision par ordinateur ont connu une croissance exponentielle.
D’ici 2022, le marché de la vision par ordinateur et du matériel devrait atteindre 48,6 milliards de dollars
L’une des principales questions ouvertes à la fois dans les neurosciences et l’apprentissage automatique est la suivante : comment fonctionne exactement notre cerveau, et comment pouvons-nous nous en approcher avec nos propres algorithmes ? La réalité est qu’il y a très peu de théories fonctionnelles et complètes sur le calcul du cerveau ; ainsi, malgré le fait que les réseaux neuronaux sont censés « imiter la façon dont le cerveau fonctionne », personne n’est tout à fait sûr que c’est réellement vrai.
Le même paradoxe vaut pour la vision par ordinateur – puisque nous ne sommes pas décidés sur la façon dont le cerveau et les yeux traitent les images, il est difficile de dire dans quelle mesure les algorithmes utilisés dans la production se rapprochent de nos propres processus mentaux internes.
À un certain niveau, la vision par ordinateur est tout au sujet de la reconnaissance des formes. Donc une façon d’entraîner un ordinateur à comprendre des données visuelles est de lui fournir des images, beaucoup d’images des milliers, des millions si possible qui ont été étiquetées, puis de les soumettre à diverses techniques logicielles, ou algorithmes, qui permettent à l’ordinateur de traquer des modèles dans tous les éléments qui se rapportent à ces étiquettes.
Donc, par exemple, si vous nourrissez un ordinateur d’un million d’images de chats (nous les aimons tous😄😹), il les soumettra toutes à des algorithmes qui leur permettent d’analyser les couleurs de la photo, les formes, les distances entre les formes, où les objets se bordent, et ainsi de suite, afin qu’il identifie un profil de ce que signifie « chat ». Lorsqu’il aura terminé, l’ordinateur sera (en théorie) capable d’utiliser son expérience si nourri d’autres images non étiquetées pour trouver celles qui sont de chat.
Laissons un instant de côté nos amis les chats en peluche et devenons plus techniques🤔😹. Voici une illustration simple du tampon d’image en niveaux de gris qui stocke notre image d’Abraham Lincoln. La luminosité de chaque pixel est représentée par un seul nombre de 8 bits, dont la plage va de 0 (noir) à 255 (blanc) :

En fait, les valeurs des pixels sont presque universellement stockées, au niveau matériel, dans un tableau unidimensionnel. Par exemple, les données de l’image ci-dessus sont stockées d’une manière similaire à cette longue liste de caractères non signés :
{157, 153, 174, 168, 150, 152, 129, 151, 172, 161, 155, 156,
155, 182, 163, 74, 75, 62, 33, 17, 110, 210, 180, 154,
180, 180, 50, 14, 34, 6, 10, 33, 48, 106, 159, 181,
206, 109, 5, 124, 131, 111, 120, 204, 166, 15, 56, 180,
194, 68, 137, 251, 237, 239, 239, 228, 227, 87, 71, 201,
172, 105, 207, 233, 233, 214, 220, 239, 228, 98, 74, 206,
188, 88, 179, 209, 185, 215, 211, 158, 139, 75, 20, 169,
189, 97, 165, 84, 10, 168, 134, 11, 31, 62, 22, 148,
199, 168, 191, 193, 158, 227, 178, 143, 182, 106, 36, 190,
205, 174, 155, 252, 236, 231, 149, 178, 228, 43, 95, 234,
190, 216, 116, 149, 236, 187, 86, 150, 79, 38, 218, 241,
190, 224, 147, 108, 227, 210, 127, 102, 36, 101, 255, 224,
190, 214, 173, 66, 103, 143, 96, 50, 2, 109, 249, 215,
187, 196, 235, 75, 1, 81, 47, 0, 6, 217, 255, 211,
183, 202, 237, 145, 0, 0, 12, 108, 200, 138, 243, 236,
195, 206, 123, 207, 177, 121, 123, 200, 175, 13, 96, 218};
Cette façon de stocker les données d’image peut aller à l’encontre de vos attentes, puisque les données semblent certainement être bidimensionnelles lorsqu’elles sont affichées. Pourtant, c’est le cas, puisque la mémoire des ordinateurs consiste simplement en une liste linéaire toujours croissante d’espaces d’adressage.

Reprenons à nouveau la première image et imaginons qu’on en ajoute une de couleur. Là, les choses commencent à se compliquer. Les ordinateurs lisent généralement la couleur comme une série de 3 valeurs – rouge, vert et bleu (RVB) – sur cette même échelle de 0 à 255. Or, chaque pixel possède en réalité 3 valeurs que l’ordinateur doit stocker en plus de sa position. Si nous devions coloriser le président Lincoln, cela conduirait à 12 x 16 x 3 valeurs, soit 576 chiffres.

C’est beaucoup de mémoire à exiger pour une image, et beaucoup de pixels sur lesquels un algorithme doit itérer. Mais pour former un modèle avec une précision significative, surtout lorsque vous parlez d’apprentissage profond, vous auriez généralement besoin de dizaines de milliers d’images, et plus il y en a, plus on rit.
L’évolution de la vision par ordinateur
Avant l’avènement de l’apprentissage profond, les tâches que la vision par ordinateur pouvait effectuer étaient très limitées et nécessitaient beaucoup de codage manuel et d’efforts de la part des développeurs et des opérateurs humains. Par exemple, si vous vouliez effectuer une reconnaissance faciale, vous deviez effectuer les étapes suivantes :
- Créer une base de données : Vous deviez capturer des images individuelles de tous les sujets que vous vouliez suivre dans un format spécifique.
- Annoter les images : Ensuite, pour chaque image individuelle, vous deviez saisir plusieurs points de données clés, comme la distance entre les yeux, la largeur de l’arête du nez, la distance entre la lèvre supérieure et le nez, et des dizaines d’autres mesures qui définissent les caractéristiques uniques de chaque personne.
- Capturer de nouvelles images : Ensuite, vous deviez capturer de nouvelles images, que ce soit à partir de photographies ou de contenus vidéo. Et vous deviez alors repasser par le processus de mesure, en marquant les points clés sur l’image. Vous deviez également tenir compte de l’angle de prise de vue.
Après tout ce travail manuel, l’application était enfin capable de comparer les mesures de la nouvelle image avec celles stockées dans sa base de données et de vous dire si elle correspondait à l’un des profils qu’elle suivait. En fait, il y avait très peu d’automatisation et la plupart du travail était effectué manuellement. Et la marge d’erreur était encore importante.
L’apprentissage automatique a fourni une approche différente pour résoudre les problèmes de vision par ordinateur. Avec l’apprentissage automatique, les développeurs n’avaient plus besoin de coder manuellement chaque règle dans leurs applications de vision. Au lieu de cela, ils ont programmé des « fonctionnalités », des applications plus petites qui pouvaient détecter des modèles spécifiques dans les images. Ils utilisaient ensuite un algorithme d’apprentissage statistique tel que la régression linéaire, la régression logistique, les arbres de décision ou les machines à vecteurs de support (SVM) pour détecter les motifs et classer les images et y détecter des objets.
L’apprentissage automatique a permis de résoudre de nombreux problèmes qui étaient historiquement difficiles pour les outils et les approches classiques de développement de logiciels. Par exemple, il y a quelques années, les ingénieurs en apprentissage automatique ont pu créer un logiciel capable de prédire les fenêtres de survie du cancer du sein mieux que les experts humains. Cependant, la construction des fonctionnalités du logiciel a nécessité les efforts de dizaines d’ingénieurs et d’experts du cancer du sein et a pris beaucoup de temps à développer.
L’apprentissage profond a fourni une approche fondamentalement différente pour faire de l’apprentissage automatique. L’apprentissage profond repose sur les réseaux neuronaux, une fonction à usage général qui peut résoudre tout problème représentable par des exemples. Lorsque vous fournissez à un réseau neuronal de nombreux exemples étiquetés d’un type spécifique de données, il sera capable d’extraire des modèles communs entre ces exemples et de les transformer en une équation mathématique qui aidera à classer les futurs éléments d’information.
Par exemple, la création d’une application de reconnaissance faciale avec l’apprentissage profond nécessite seulement de développer ou de choisir un algorithme préconstruit et de l’entraîner avec des exemples de visages des personnes qu’il doit détecter. Étant donné suffisamment d’exemples (beaucoup d’exemples), le réseau neuronal sera capable de détecter les visages sans autres instructions sur les caractéristiques ou les mesures.
L’apprentissage profond est une méthode très efficace pour faire de la vision par ordinateur. Dans la plupart des cas, la création d’un bon algorithme d’apprentissage profond se résume à rassembler une grande quantité de données d’entraînement étiquetées et à régler les paramètres tels que le type et le nombre de couches de réseaux neuronaux et les époques d’entraînement. Par rapport aux types précédents d’apprentissage automatique, l’apprentissage profond est à la fois plus facile et plus rapide à développer et à déployer.
La plupart des applications actuelles de vision par ordinateur, telles que la détection du cancer, les voitures à conduite autonome et la reconnaissance faciale, font appel à l’apprentissage profond. L’apprentissage profond et les réseaux neuronaux profonds sont passés du domaine conceptuel aux applications pratiques grâce à la disponibilité et aux progrès du matériel et des ressources informatiques en nuage.
Combien de temps faut-il pour déchiffrer une image
En bref, pas beaucoup. C’est la clé qui explique pourquoi la vision par ordinateur est si palpitante : Alors que dans le passé, même les superordinateurs pouvaient prendre des jours, des semaines, voire des mois pour effectuer tous les calculs nécessaires, les puces ultra-rapides et le matériel connexe d’aujourd’hui, ainsi qu’un internet rapide et fiable et les réseaux en nuage, rendent le processus rapide comme l’éclair. Un autre facteur crucial a été la volonté de nombreuses grandes entreprises effectuant des recherches sur l’IA de partager leurs travaux Facebook, Google, IBM et Microsoft, notamment en mettant en libre accès certains de leurs travaux d’apprentissage automatique.
Cela permet à d’autres de s’appuyer sur leurs travaux plutôt que de partir de zéro. En conséquence, l’industrie de l’IA est en train de mijoter, et des expériences qui, il n’y a pas si longtemps, prenaient des semaines à exécuter peuvent prendre 15 minutes aujourd’hui. Et pour de nombreuses applications réelles de la vision par ordinateur, tout ce processus se déroule en continu en microsecondes, de sorte qu’un ordinateur est aujourd’hui capable d’être ce que les scientifiques appellent « conscient de la situation ». »
Applications de la vision par ordinateur
La vision par ordinateur est l’un des domaines de l’apprentissage automatique où les concepts fondamentaux sont déjà intégrés dans les principaux produits que nous utilisons tous les jours.
Vision par ordinateur dans les voitures autopilotées
Mais les entreprises technologiques ne sont pas les seules à tirer parti de l’apprentissage automatique pour les applications d’image.
La vision par ordinateur permet aux voitures autopilotées de donner un sens à leur environnement. Les caméras capturent des vidéos sous différents angles autour de la voiture et les transmettent à un logiciel de vision par ordinateur, qui traite ensuite les images en temps réel pour trouver les extrémités des routes, lire les panneaux de signalisation, détecter les autres voitures, les objets et les piétons. La voiture autonome peut alors se diriger dans les rues et sur les autoroutes, éviter de heurter des obstacles et (espérons-le) conduire en toute sécurité ses passagers à leur destination.
CV Dans la reconnaissance faciale
La vision par ordinateur joue également un rôle important dans les applications de reconnaissance faciale, la technologie qui permet aux ordinateurs de faire correspondre les images des visages des personnes à leur identité. Les algorithmes de vision par ordinateur détectent les caractéristiques faciales des images et les comparent à des bases de données de profils de visages. Les appareils grand public utilisent la reconnaissance faciale pour authentifier l’identité de leurs propriétaires. Les applications de médias sociaux utilisent la reconnaissance faciale pour détecter et étiqueter les utilisateurs. Les organismes d’application de la loi s’appuient également sur la technologie de reconnaissance faciale pour identifier les criminels dans les flux vidéo.
CV Dans la réalité augmentée &Réalité mixte
La vision par ordinateur joue également un rôle important dans la réalité augmentée et mixte, la technologie qui permet aux appareils informatiques tels que les smartphones, les tablettes et les lunettes intelligentes de superposer et d’intégrer des objets virtuels sur l’imagerie du monde réel. Grâce à la vision par ordinateur, les équipements de réalité augmentée détectent les objets du monde réel afin de déterminer les emplacements sur l’écran d’un appareil où placer un objet virtuel. Par exemple, les algorithmes de vision par ordinateur peuvent aider les applications de RA à détecter les plans tels que les plateaux de table, les murs et les sols, une partie très importante de l’établissement de la profondeur et des dimensions et du placement des objets virtuels dans le monde physique.
CV dans les soins de santé
La vision par ordinateur a également joué un rôle important dans les avancées de la technologie de la santé. Les algorithmes de vision par ordinateur peuvent aider à automatiser des tâches telles que la détection de grains de beauté cancéreux sur des images de la peau ou la recherche de symptômes sur des radiographies et des IRM.
Défis de la vision par ordinateur
Aider les ordinateurs à voir s’avère très difficile.
Inventer une machine qui voit comme nous est une tâche faussement difficile, non seulement parce qu’il est difficile de faire en sorte que les ordinateurs le fassent, mais aussi parce que nous ne sommes pas entièrement sûrs de la façon dont la vision humaine fonctionne en premier lieu.
L’étude de la vision biologique nécessite une compréhension des organes de perception comme les yeux, ainsi que l’interprétation de la perception dans le cerveau. De nombreux progrès ont été réalisés, à la fois dans la cartographie du processus et en termes de découverte des astuces et des raccourcis utilisés par le système, bien que, comme toute étude qui implique le cerveau, il y ait un long chemin à parcourir.

De nombreuses applications populaires de vision par ordinateur consistent à essayer de reconnaître des choses dans des photographies ; par exemple :
- Classification des objets : Quelle grande catégorie d’objet se trouve dans cette photographie?
- Identification d’objets : Quel type d’un objet donné se trouve dans cette photographie?
- Vérification de l’objet : L’objet est-il dans la photographie?
- Détection d’objets : Où se trouvent les objets dans la photographie?
- Détection des points de repère de l’objet : Quels sont les points clés de l’objet dans la photographie?
- Segmentation d’objets : Quels pixels appartiennent à l’objet dans l’image?
- Reconnaissance d’objets : Quels sont les objets présents sur cette photographie et où sont-ils ?
En dehors de la simple reconnaissance, les autres méthodes d’analyse comprennent :
- L’analyse du mouvement vidéo utilise la vision par ordinateur pour estimer la vitesse des objets dans une vidéo, ou de la caméra elle-même.
- Dans la segmentation d’images, les algorithmes partitionnent les images en plusieurs ensembles de vues.
- La reconstruction de scènes crée un modèle 3D d’une scène entrée par des images ou des vidéos.
- Dans la restauration d’images, le bruit tel que le flou est supprimé des photos en utilisant des filtres basés sur l’apprentissage automatique.
Toute autre application qui implique la compréhension des pixels par le biais d’un logiciel peut sans risque être étiquetée comme vision par ordinateur.
Conclusion
Malgré les progrès récents, qui ont été impressionnants, nous ne sommes toujours pas près de résoudre la vision par ordinateur. Cependant, il existe déjà de multiples institutions et entreprises de santé qui ont trouvé des moyens d’appliquer des systèmes de CV, alimentés par des CNN, à des problèmes du monde réel. Et cette tendance n’est pas prête de s’arrêter.
Si vous voulez entrer en contact et qu’au passage, vous connaissez une bonne blague, vous pouvez vous connecter avec moi sur Twitter ou LinkedIn.
Merci de me lire !😄 🙌
.