Here’s A Look Why It’s So Awesome.は、コンピュータビジョンについて知りたかったことのすべてです。
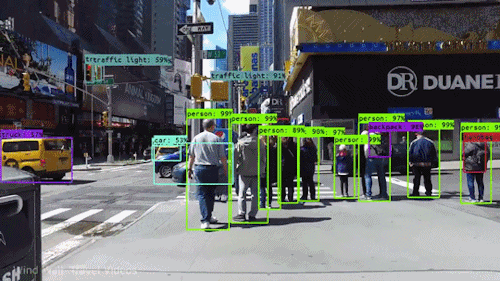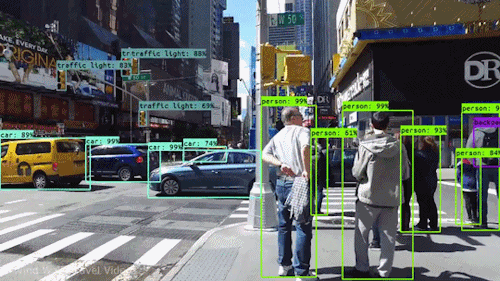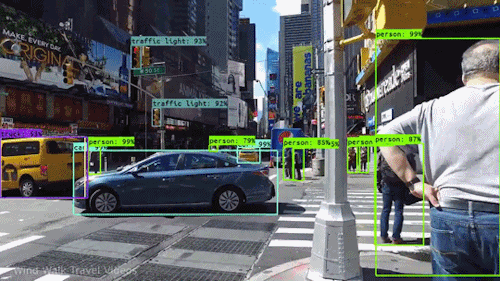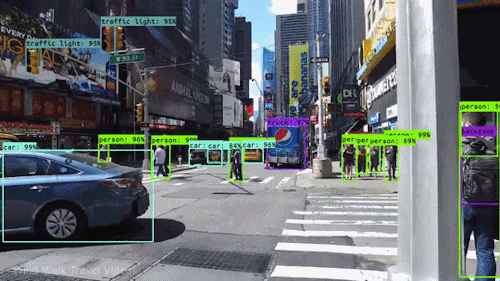
最も強力で魅力的な AIの種類の1つはコンピュータビジョンで、あなたはほとんど知らないうちにいろいろと体験していると思われます。 ここでは、コンピューター ビジョンとは何か、どのように機能するのか、そしてなぜそれほどまでに素晴らしいのか (そして、さらに良くなっていくのか) を見ていきます。
コンピューター ビジョンは、人間の視覚システムの複雑さの一部を再現し、人間と同じように画像やビデオ内のオブジェクトをコンピューターで識別および処理できるよう、コンピューター サイエンスの一分野として焦点をあてています。 最近まで、コンピューター ビジョンは限られた能力でしか機能しませんでした。
人工知能の進歩とディープラーニングやニューラルネットワークの革新により、この分野は近年大きく飛躍し、物体の検出やラベル付けに関するいくつかのタスクで人間を超えることができるようになりました。
コンピューター ビジョンの成長の原動力の 1 つは、今日私たちが生成する大量のデータで、それをトレーニングしてコンピューター ビジョンをより良いものにするために使用します。

膨大な量の視覚データとともに(毎日 30 億枚以上のイメージがオンラインで共有されています)、そのデータを解析するための演算能力も手に入れられるようになりました。 コンピューター ビジョンの分野が新しいハードウェアとアルゴリズムで成長するにつれ、オブジェクト識別の精度も向上してきました。 コンピュータ ビジョンの初期の実験は 1950 年代に始まり、1970 年代にはタイプされたテキストと手書きのテキストを区別するために初めて商業的に使用されましたが、今日では、コンピュータ ビジョンのアプリケーションは飛躍的に成長しています。
2022 年までに、コンピューター ビジョンとハードウェアの市場は 486 億ドルに達すると予想されます
神経科学と機械学習の両方における主要な未解決問題の 1 つは、人間の脳は一体どのように機能しているのか、そして、独自のアルゴリズムでそれをどのように近似できるのか、ということです。 したがって、ニューラル ネットは「脳の働き方を模倣する」とされていますが、それが実際に正しいかどうかは誰にもわかりません。
同じパラドックスがコンピューター ビジョンにも当てはまります。 つまり、視覚データを理解する方法をコンピュータに訓練させる1つの方法は、ラベル付けされた何千、何百万もの画像を送り、それらをさまざまなソフトウェア技術、つまりアルゴリズムにかけることです。
たとえば、コンピュータに猫の画像を 100 万枚与えると (私たちは皆、猫が大好きです😄😹)、コンピュータはそれらすべてをアルゴリズムにかけ、写真の色、形、形同士の距離、オブジェクトが互いに接している場所などを分析して、「猫」が意味するプロファイルを識別することができるようにします。 それが終わると、コンピューターは (理論的には) 他のラベルのない画像を与えた場合の経験を使用して、猫の画像を見つけることができます。
私たちのふわふわした猫の友人はちょっと横に置いておいて、もっと技術的に話をしましょう🤔😹。 以下は、エイブラハム・リンカーンの画像を保存するグレースケールイメージバッファの簡単な図解です。 各ピクセルの明るさは、0 (黒) から 255 (白) までの 8 ビット数値で表されます。

実は、ピクセル値はハードウェア レベルではほぼ例外なく 1 次元配列に保存されています。 例えば、上の画像のデータは、
{157, 153, 174, 168, 150, 152, 129, 151, 172, 161, 155, 156,
155, 182, 163, 74, 75, 62, 33, 17, 110, 210, 180, 154,
180, 180, 50, 14, 34, 6, 10, 33, 48, 106, 159, 181,
206, 109, 5, 124, 131, 111, 120, 204, 166, 15, 56, 180,
194, 68, 137, 251, 237, 239, 239, 228, 227, 87, 71, 201,
172, 105, 207, 233, 233, 214, 220, 239, 228, 98, 74, 206,
188, 88, 179, 209, 185, 215, 211, 158, 139, 75, 20, 169,
189, 97, 165, 84, 10, 168, 134, 11, 31, 62, 22, 148,
199, 168, 191, 193, 158, 227, 178, 143, 182, 106, 36, 190,
205, 174, 155, 252, 236, 231, 149, 178, 228, 43, 95, 234,
190, 216, 116, 149, 236, 187, 86, 150, 79, 38, 218, 241,
190, 224, 147, 108, 227, 210, 127, 102, 36, 101, 255, 224,
190, 214, 173, 66, 103, 143, 96, 50, 2, 109, 249, 215,
187, 196, 235, 75, 1, 81, 47, 0, 6, 217, 255, 211,
183, 202, 237, 145, 0, 0, 12, 108, 200, 138, 243, 236,
195, 206, 123, 207, 177, 121, 123, 200, 175, 13, 96, 218};
という符号なし文字の羅列のような形で格納されているのですが、表示すると確かに2次元に見えるので、この格納方法は予想に反しているかもしれません。 しかし、コンピュータのメモリは、単純にアドレス空間の増大する線形リストで構成されているので、これは事実です。

もう一度最初の写真に戻って、色の付いたものを追加すると想像してみてください。 今度はもっと複雑になってきます。 コンピュータは通常、同じ 0 ~ 255 のスケールで、赤、緑、青 (RGB) の 3 つの値のシリーズとして色を読み取ります。 このとき、各ピクセルには、位置のほかに3つの値が格納されています。

これは 1 つの画像に必要な多くのメモリと、アルゴリズムが繰り返し使用する多くのピクセルです。 しかし、意味のある精度でモデルをトレーニングするには、特にディープラーニングについて話している場合、通常は何万もの画像が必要であり、多ければ多いほどよいのです。
The Evolution Of Computer Vision
The Deep Learning の出現以前、コンピューター ビジョンが実行できるタスクは非常に限られており、開発者と人間のオペレーターによる多くの手動コーディングと労力が必要でした。 たとえば、顔認識を実行したい場合、次の手順を実行する必要があります:
- データベースを作成する。 追跡したいすべての被写体の個別の画像を特定のフォーマットでキャプチャする必要がありました。
- 画像に注釈を付ける。 次に、個々の画像ごとに、目と目の間の距離、鼻梁の幅、上唇と鼻の間の距離、および各人の固有の特徴を定義する数十の他の測定値など、いくつかの重要なデータポイントを入力する必要がありました。 次に、写真やビデオコンテンツから、新しい画像をキャプチャする必要があります。 そして、画像上の重要なポイントに印をつけながら、再び計測作業を行う必要がありました。
このすべての手動作業の後、アプリケーションはようやく新しい画像の測定値をデータベースに保存されているものと比較し、それが追跡中のプロファイルのいずれかに対応しているかどうかを伝えることができるようになるのです。 実際には、自動化はほとんど行われておらず、ほとんどの作業が手作業で行われていた。
機械学習は、コンピュータビジョンの問題を解決するための異なるアプローチを提供しました。 機械学習により、開発者はビジョン アプリケーションに一つひとつのルールを手動でコーディングする必要がなくなりました。 その代わりに、画像内の特定のパターンを検出できる小さなアプリケーションである「特徴」をプログラムするのです。 次に、線形回帰、ロジスティック回帰、決定木、またはサポート ベクトル マシン (SVM) などの統計的学習アルゴリズムを使用して、パターンを検出し、画像を分類して、その中のオブジェクトを検出します。 たとえば、何年も前に、機械学習エンジニアは、人間の専門家よりも優れた乳がんの生存期間を予測できるソフトウェアを作成することができました。 しかし、そのソフトウェアの機能を構築するためには、何十人ものエンジニアと乳がんの専門家の努力が必要で、開発には多くの時間がかかりました。
深層学習は機械学習を行う上で根本的に異なるアプローチを提供しました。 ディープラーニングは、例によって表現可能なあらゆる問題を解決できる汎用関数であるニューラルネットワークに依存しています。 ニューラル ネットワークに、特定の種類のデータのラベル付けされた多くの例を与えると、それらの例間の共通のパターンを抽出し、将来の情報の断片を分類するのに役立つ数式に変換することができます。
たとえば、深層学習で顔認識アプリケーションを作成するには、あらかじめ構築されたアルゴリズムを開発または選択して、検出すべき人物の顔の例でそれを訓練するだけです。 十分な例 (たくさんの例) があれば、ニューラルネットワークは、特徴や測定値についてさらなる指示がなくても顔を検出できるようになります。
ディープラーニングは、コンピューター ビジョンを行うための非常に効果的な方法です。 ほとんどの場合、優れた深層学習アルゴリズムを作成するには、ラベル付けされた学習データを大量に集め、ニューラルネットワークの種類や層の数、学習エポックなどのパラメーターを調整することに尽きます。 以前のタイプの機械学習と比較して、深層学習は開発と展開が簡単かつ迅速です。
Most of current computer vision applications such as cancer detection, self-driving cars and facial recognition makes use of deep learning.がん検知、自動運転車、顔認識など、現在のコンピューター ビジョン アプリケーションのほとんどは、深層学習を利用しています。 ディープラーニングとディープニューラルネットワークは、ハードウェアとクラウド コンピューティング リソースの利用可能性と進歩のおかげで、概念的な領域から実用的なアプリケーションへと移行しました」
How Long Does It Take To Decipher An Image
In short not much. これが、コンピュータ ビジョンがスリリングである理由の鍵です。 以前は、スーパーコンピューターでさえ、必要なすべての計算を完了するのに数日、数週間、あるいは数か月かかったかもしれませんが、今日の超高速チップと関連ハードウェア、および高速で信頼できるインターネットとクラウド ネットワークにより、プロセスが非常に高速になりました。 もう 1 つの重要な要因は、AI 研究を行っている多くの大企業が、Facebook、Google、IBM、Microsoft など、特に機械学習の一部をオープンソース化することによって、その研究を共有しようとする意欲があることです。 その結果、AI 産業はどんどん発展し、少し前まで数週間かかっていた実験が、今では 15 分で終わるようになりました。 また、コンピューター ビジョンの多くの実世界のアプリケーションでは、このプロセスはすべてマイクロ秒単位で継続的に行われるため、今日のコンピューターは科学者が「状況認識」と呼ぶものを実現することができます。
CV In Self-Driving Cars
しかし、画像アプリケーションに機械学習を活用しているのは、ハイテク企業だけではありません。 カメラは車の周囲のさまざまな角度からビデオをキャプチャし、コンピュータ ビジョン ソフトウェアに送ります。コンピュータ ビジョン ソフトウェアはリアルタイムで画像を処理し、道路の端を見つけ、交通標識を読み、他の車、オブジェクト、および歩行者を検出します。
CV In Facial Recognition
Computer Vision は、顔認識アプリケーションにおいても重要な役割を担っており、コンピュータが人の顔の画像とその身元を照合するための技術です。 コンピュータビジョンのアルゴリズムは、画像から顔の特徴を検出し、顔のプロフィールのデータベースと比較します。 消費者向け機器では、顔認識により所有者の身元が認証されます。 ソーシャルメディアのアプリでは、顔認識を使ってユーザーを検出し、タグ付けしています。
CV In Augmented Reality & Mixed Reality
Computer Vision は、スマートフォン、タブレット、スマート グラスなどのコンピューティング デバイスで、現実世界の画像に仮想オブジェクトを重ねたり埋め込むことを可能にする技術である拡張現実および複合現実でも重要な役割を担っています。 AR機器では、コンピュータビジョンを使って現実世界の物体を検出し、デバイスのディスプレイ上に仮想オブジェクトを配置する位置を決定する。 たとえば、コンピュータ ビジョン アルゴリズムは、AR アプリケーションで、タブレット、壁、床などの平面を検出するのに役立ち、奥行きと寸法を確立し、物理世界に仮想オブジェクトを配置するのに非常に重要な役割を果たします。 コンピュータ ビジョン アルゴリズムは、皮膚画像から癌性のほくろを検出したり、X 線や MRI スキャンから症状を発見したりといったタスクの自動化に役立っています。
人間のように見る機械を発明することは、コンピュータにそれをさせるのが難しいだけでなく、そもそも人間の視覚がどのように機能するのかが完全にわかっていないため、ごまかしのきかない難しい作業です。
生物学的視覚を研究するには、目などの知覚器官と、脳内での知覚の解釈について理解することが必要です。 プロセスを図式化する上でも、システムが使用するトリックやショートカットを発見する上でも、多くの進歩がありましたが、脳に関わる他の研究と同様に、まだまだ先のことです。

Many popular computer vision applications involves try to recognize things in photographs; for example:
- Object Classification:
- オブジェクトの識別:この写真に写っているオブジェクトはどのような大まかなカテゴリなのか。
- Object Verification:この写真に写っているのはどのタイプの物体なのか?
- 物体が写真に写っているか:物体の検出。
- Object Landmark Detection:対象物が写真のどこに写っているかを検出する。
- オブジェクトのセグメンテーション: 写真内のオブジェクトのキーポイントは何ですか。
- Object Recognition:画像内のどのピクセルがオブジェクトに属するか。
認識以外にも、次のような分析方法があります。
- ビデオモーション分析では、ビデオ内のオブジェクトやカメラ自体の速度を推定するためにコンピューター ビジョンを使用します。
- 画像分割では、アルゴリズムにより画像を複数のビュー セットに分割します。
- 画像の復元では、機械学習ベースのフィルターを使用して、写真からぼかしなどのノイズを除去します。
ソフトウェアを通じてピクセルを理解するその他のアプリケーションは、コンピューター ビジョンとして安全にラベル付けすることができます。 しかし、すでに複数の医療機関や企業が、CNN を搭載した CV システムを実世界の問題に適用する方法を見出しています。 そして、この傾向はすぐには止まりそうにありません。
連絡を取りたい場合、ついでに良いジョークを知っている場合は、Twitter または LinkedIn で私とつながることができます。
読んでくださってありがとうございます!😄 🙌