Nemělo by nás překvapit, že i v částech genomu, kde zjevně nevidíme „funkční“ kód (tj. takový, který byl evolučně zafixován v důsledku nějaké selekční výhody), existuje určitý typ kódu, ale ne takový, jaký jsme za něj dosud považovali. A co kdyby kromě jednoho rozměru kódu ATGC dělal něco i ve třech rozměrech? Článek právě publikovaný v časopise BioEssays zkoumá tuto dráždivou možnost…
Není to báječné mít k dispozici opravdu zapeklitý problém, který generuje téměř nekonečné množství možných vysvětlení. Co třeba „co dělá všechna ta nekódující DNA v genomech?“ – těch 98,5 % lidského genetického materiálu, který nevytváří proteiny. Abychom byli spravedliví, dešifrování nekódující DNA dělá velké pokroky díky identifikaci sekvencí, které jsou přepisovány do RNA, jež modulují genovou expresi, mohou být předávány transgeneračně (epigenetika) nebo nastavují program genové exprese kmenové buňky nebo konkrétní tkáňové buňky. V mnoha genomech bylo nalezeno obrovské množství opakujících se sekvencí (pozůstatky dávných retrovirů), které opět nekódují bílkoviny, ale alespoň existují věrohodné modely toho, co dělají z evolučního hlediska (od genomového parazitismu přes symbiózu až po „využívání“ samotného hostitelského genomu k produkci genetické rozmanitosti, na níž evoluce funguje); mimochodem, některé nekódující DNA vytvářejí RNA, které tyto retrovirové sekvence umlčují, a předpokládá se, že vniknutí retrovirů do genomů bylo selekčním tlakem na evoluci RNA interference (tzv. RNAi); repetitivní elementy různých pojmenovaných typů a tandemové repetice jsou hojné; ukázalo se, že introny (z nichž mnohé obsahují výše zmíněné typy nekódujících sekvencí) mají zásadní význam pro genovou expresi a regulaci, a to nejnápadněji prostřednictvím alternativního sestřihu kódujících segmentů, které oddělují.
Stále je tu však spousta problémů k nahlodání, protože ačkoli stále více chápeme povahu a původ velké části nekódujícího genomu a děláme velké pokroky v jeho „funkci“ (zde definované jako evolučně vybraný, výhodný účinek na hostitelský organismus), zdaleka jsme nevysvětlili všechno, a – což je ještě důležitější – díváme se na to takříkajíc objektivem s velmi malým zvětšením. Jednou ze zajímavých věcí na sekvencích DNA je, že jedna sekvence může „kódovat“ více než jednu informaci v závislosti na tom, co ji „čte“ a v jakém směru – virové genomy jsou klasickým příkladem, kdy se geny čtené jedním směrem k produkci daného proteinu překrývají s jedním nebo více geny čtenými opačným směrem (tj. z komplementárního vlákna DNA) k produkci různých proteinů. Je to trochu jako vytváření jednoduchých zpráv pomocí slov s opačným párem (tzv. emordnilap). Např: REEDSTOPSFLOW, které by se pomyslným čtecím zařízením dalo rozdělit na REED STOPS FLOW. Přečteno pozpátku by to dalo WOLF SPOTS DEER.
Jestliže je evolučně výhodné, aby dvě zprávy byly zakódovány takto úsporně – jako je tomu v případě virových genomů, které mají tendenci vyvíjet se směrem k minimální složitosti z hlediska informačního obsahu, a tudíž snižovat potřebné zdroje pro reprodukci – pak se samotné zprávy vyvíjejí s vysokou mírou omezení. Co to znamená? No, mohli bychom náš původní příklad zprávy formulovat jako RUSH-STEM IMPEDES CURRENT, což by ztělesňovalo stejnou podstatnou informaci jako REED STOPS FLOW. Tato zpráva však při opačném čtení (nebo dokonce ve stejném smyslu, ale v jiných částech) nezakóduje nic navíc, co by mělo zvláštní význam. Pravděpodobně jediným způsobem, jak předat obě informace v původních zprávách současně, je právě formulace REEDSTOPSFLOW: to je velmi omezený systém! Kdybychom totiž prostudovali dostatek příkladů reverzně párových vět v angličtině, zjistili bychom, že jsou vcelku tvořeny spíše krátkými slovy a v sekvencích chybějí některé jazykové jednotky, jako jsou členy (the, a); kdybychom se podívali pozorněji, mohli bychom v takových sděleních dokonce zjistit nadprůměrné zastoupení některých písmen abecedy. Vnímali bychom je jako odchylky v používání slov a písmen, které by nám a priori umožnily pokusit se identifikovat takové „dvojfunkční“ části informace.
Nyní se vraťme k „písmenům“, „slovům“ a „informacím“ zakódovaným v genomech. Pro dva odlišné kusy informace, které mají být zakódovány v témže kusu genetické sekvence, bychom podobně očekávali, že se omezení projeví v odchylkách použití slov a písmen – analogicky pro sekvence aminokyselin tvořící proteiny a jejich třípísmenný kód. Sekvence DNA tedy může kódovat protein a navíc i něco jiného. Toto „něco jiného“ je podle Giorgia Bernardiho informace, která řídí balení obrovské délky DNA v buňce do relativně malého jádra. Především je to kód, který řídí vazbu bílkovin obalujících DNA, známých jako histony. Bernardi to označuje jako „genomický kód“ – strukturální kód, který definuje tvar a zhuštění DNA do vysoce kondenzované formy známé jako „chromatin“.
Nezačali jsme ale s vysvětlením nekódující DNA, nikoli sekvencí kódujících proteiny? Ano, a v dlouhých úsecích nekódující DNA vidíme informaci přesahující pouhé repetice, tandemové repetice a zbytky dávných retrovirů: existuje typ kódu na úrovni preference GC páru chemických bází DNA ve srovnání s AT. Jak uvádí Bernardi v přehledu syntetizujícím průkopnickou práci jeho a dalších autorů, v základních sekvencích eukaryotického genomu se během evolučního přechodu mezi tzv. studenokrevnými a teplokrevnými organismy zvýšil obsah GC ve strukturních organizačních jednotkách genomu označovaných jako „izochory“. A je fascinující, že tento sekvenční bias se překrývá se sekvencemi, které mají mnohem omezenější funkci: jsou to právě již zmíněné sekvence kódující proteiny a ty – více než interferující nekódující sekvence – jsou vodítkem ke „genomickému kódu“.
Sekvence kódující proteiny jsou také v jádře zabaleny a zhuštěny – zejména když nejsou „v provozu“ (tj, přepisovány a následně překládány do bílkovin) – ale také obsahují relativně stálou informaci o přesné identitě aminokyselin, jinak by nedokázaly správně kódovat bílkoviny: evoluce by na takové mutace působila vysoce negativním způsobem, takže by bylo krajně nepravděpodobné, že se udrží a budou pro nás viditelné. Kód aminokyselin v DNA má však malý „háček“, který se vyvinul u nejjednodušších jednobuněčných organismů (bakterií a archeí) před miliardami let: kód je částečně nadbytečný. Například aminokyselina threonin může být v eukaryotické DNA zakódována ne méně než čtyřmi způsoby: ACT, ACC, ACA nebo ACG. Třetí písmeno je variabilní, a tudíž „k dispozici“ pro kódování další informace. Přesně to se děje při tvorbě „genomového kódu“, který v tomto případě vytváří příklon k formám ACC a ACG u teplokrevných organismů. Proto je vysoké omezení tohoto dodatečného „kódu“ – které se projevuje i v částech genomu, které nejsou pod takovým omezením jako sekvence kódující bílkoviny – dáno balením sekvencí kódujících bílkoviny, které ztělesňují dvě sady informací současně. To je analogické našemu příkladu vysoce omezené sekvence s dvojí informací REEDSTOPSFLOW.
Důležité však je, že omezení není tak přísné jako v našem příkladu anglického jazyka kvůli redundanci třetí pozice tripletového kódu pro aminokyseliny: lepší analogií by bylo SHE*ATE*STU*, kde hvězdička znamená proměnné písmeno, které pro stroj, jenž čte třípísmennou složku čtyřpísmenné zprávy, nedělá žádný rozdíl. Lze si pak představit druhou úroveň informace vytvořenou přidáním „D“ na tato místa s hvězdičkou, čímž vznikne SHEDATEDSTUD (SHE DATED STUD). Dále si představte druhý čtecí stroj, který hledá významové věty „citlivé povahy“ obsahující větší než průměrnou koncentraci D. Tento čtecí stroj s sebou nese skládací stroj, který na každé D umístí jakýsi kolík, který zprávu zalomí o 120 stupňů v rovině. a point where the message should be bent by 120 degrees in the same plane, we would end up with a more compact, triangular, version. V eukaryotických genomech se předpokládané vychýlení GC sekvence, které je zodpovědné za strukturní kondenzaci, rozšiřuje i do nekódujících sekvencí, z nichž některé mají identifikované aktivity, i když jsou sekvenčně méně omezené než DNA kódující proteiny. Tam řídí jejich kondenzaci prostřednictvím nukleozomů obsahujících histony a vytváří chromatin.
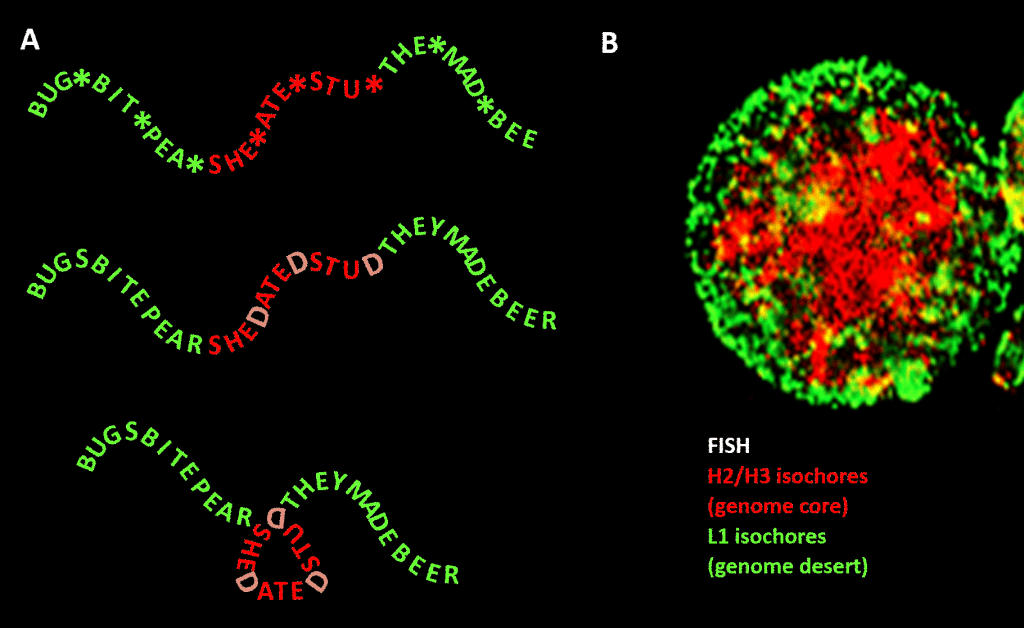
Obrázek. Analogie mezi kondenzací zprávy založené na slovech a kondenzací genomové DNA v buněčném jádře. Panel A: Informace v informaci, posloupnost slov s proměnlivou čtvrtou mezerou, která po vyplnění určitými písmeny vytváří další zprávu. Jedna zpráva je čtena třípísmenným čtecím strojem; druhá čtecím strojem, který dokáže interpretovat informaci sahající až na čtvrtou proměnnou pozici sekvence. Druhý čtecí stroj rozpozná „citlivou“ informaci, která by měla být skryta, a v místech, kde se na 4. pozici objevuje písmeno „D“, složí řetězec slov, tedy stlačí „citlivou“ část a odstraní ji z dohledu. To je analogie principu genomické 3D komprese prostřednictvím chromatinu, jak je znázorněno na panelu B: fluorescenční snímek (prostřednictvím fluorescenční in situ hybridizace – FISH) buněčného jádra. Izochory H2/H3, jejichž obsah GC se během evoluce od studenokrevných k teplokrevným obratlovcům zvýšil, jsou stlačeny do chromatinového jádra a izochory L1 (s nižším obsahem GC) na periferii zůstávají v méně kondenzovaném stavu. Podle Bernardiho je „genomický kód“ obsažený v drahách genomu s vysokým obsahem GC přečten mechanismem pro umístění nukleozomů v buňce a interpretován jako sekvence, která má být vysoce stlačená v euchromatinu. Poděkování: Panel A: koncept a výroba obrázků: Andrew Moore; Panel B: vzor FISH izochor H2/H3 a L1 z lymfocytu indukovaného PHA – s laskavým svolením S. Sacconeho – jak je reprodukován v Ref. .].
Tyto oblasti DNA pak lze považovat za strukturně důležité prvky při vytváření správného tvaru a oddělení kondenzovaných kódujících sekvencí v genomu, bez ohledu na jakoukoli jinou možnou funkci, kterou tyto nekódující sekvence mají: v podstatě by to bylo „vysvětlení“ přetrvávání sekvencí v genomech, kterým nelze přisoudit žádnou „funkci“ (ve smyslu evolučně vybrané aktivity), (nebo alespoň žádnou podstatnou funkci).
Poslední analogií – tentokrát mnohem těsněji související – by mohly být samotné sekvence aminokyselin ve velkých proteinech, které dělají různé zákruty, otočky, záhyby atd. Můžeme žasnout nad tak složitými strukturami a ptát se „ale musí být pro svou funkci až tak složité?“. No, možná to dělají proto, aby se části bílkoviny zahušťovaly a umisťovaly do přesné orientace a místa, které vytváří trojrozměrnou strukturu, jež byla evolucí úspěšně vybrána. Ale s vědomím, že „genomický kód“ překrývá sekvence kódující bílkoviny, můžeme dokonce začít mít podezření, že zde působí i jiný selekční tlak…
Andrew Moore, Ph.D.
Editor-in-Chief, BioEssays