- Hier is een blik waarom het zo geweldig is.
- The Evolution Of Computer Vision
- Hoe lang duurt het om een afbeelding te ontcijferen
- Toepassingen van computer vision
- CV in zelfrijdende auto’s
- CV In Facial Recognition
- CV In Augmented Reality & Mixed Reality
- CV In Healthcare
- Uitdagingen van computer vision
- Conclusie
Hier is een blik waarom het zo geweldig is.
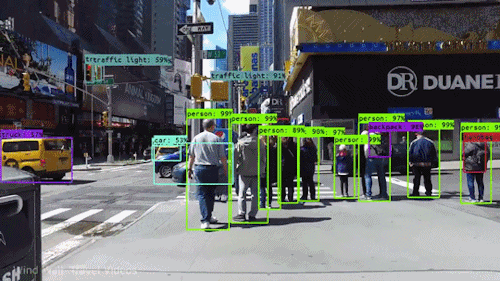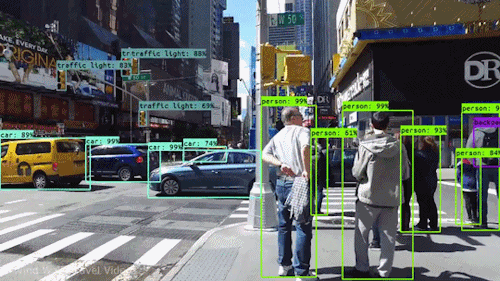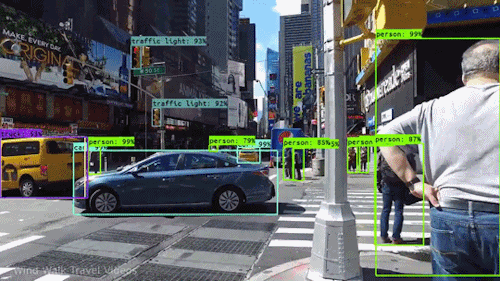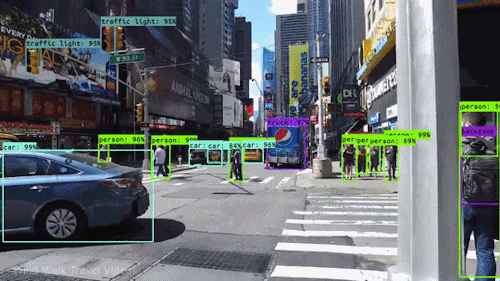
Een van de krachtigste en boeiendste vormen van AI is computer vision, waarmee u vrijwel zeker al ervaring hebt opgedaan zonder het te weten. Hier volgt een overzicht van wat het is, hoe het werkt en waarom het zo geweldig is (en alleen maar beter zal worden).
Computer vision is het gebied van de computerwetenschap dat zich richt op het repliceren van delen van de complexiteit van het menselijke vision-systeem en computers in staat stelt om objecten in afbeeldingen en video’s te identificeren en te verwerken op dezelfde manier als mensen dat doen. Tot voor kort werkte computervisie slechts in beperkte mate.
Dankzij de vooruitgang in kunstmatige intelligentie en innovaties in deep learning en neurale netwerken, heeft het veld de afgelopen jaren grote sprongen kunnen maken en is het in staat geweest om mensen te overtreffen in sommige taken met betrekking tot het detecteren en labelen van objecten.
Een van de drijvende factoren achter de groei van computervisie is de hoeveelheid gegevens die we tegenwoordig genereren en die vervolgens worden gebruikt om computervisie te trainen en beter te maken.

Naast een enorme hoeveelheid visuele gegevens (elke dag worden meer dan 3 miljard afbeeldingen online gedeeld) is nu ook de rekenkracht beschikbaar die nodig is om de gegevens te analyseren. Naarmate het gebied van computervisie is gegroeid met nieuwe hardware en algoritmen, zijn ook de nauwkeurigheidspercentages voor objectidentificatie toegenomen. In minder dan tien jaar tijd hebben de systemen van vandaag een nauwkeurigheid van 99% bereikt ten opzichte van 50%, waardoor ze nauwkeuriger zijn dan mensen bij het snel reageren op visuele input.
Eerste experimenten op het gebied van computervisie begonnen in de jaren 1950 en in de jaren 1970 werd het voor het eerst commercieel gebruikt om getypte en handgeschreven tekst van elkaar te onderscheiden; tegenwoordig zijn de toepassingen voor computervisie exponentieel gegroeid.
Tegen 2022 wordt verwacht dat de markt voor computer vision en hardware 48,6 miljard dollar zal bedragen
Een van de belangrijkste open vragen in zowel neurowetenschappen als machine learning is: hoe werken onze hersenen precies, en hoe kunnen we dat benaderen met onze eigen algoritmen? De realiteit is dat er zeer weinig werkende en allesomvattende theorieën over hersenverwerking zijn; dus ondanks het feit dat Neurale Netten verondersteld worden “de manier waarop de hersenen werken na te bootsen”, is niemand er zeker van of dat ook werkelijk zo is.
Dezelfde paradox geldt voor computervisie – aangezien we niet weten hoe de hersenen en de ogen beelden verwerken, is het moeilijk te zeggen hoe goed de algoritmen die bij de productie worden gebruikt onze eigen interne mentale processen benaderen.
Op een bepaald niveau draait computervisie allemaal om patroonherkenning. Dus een manier om een computer te trainen hoe visuele gegevens te begrijpen is om het te voeden beelden, veel beelden duizenden, miljoenen indien mogelijk die zijn gelabeld, en dan onderworpen die aan verschillende software technieken, of algoritmen, die de computer in staat stellen om te jagen naar patronen in alle elementen die betrekking hebben op die labels.
Zo, bijvoorbeeld, als je een computer een miljoen foto’s van katten geeft (we houden er allemaal van😄😹), dan zal hij ze allemaal onderwerpen aan algoritmen die hem de kleuren in de foto laten analyseren, de vormen, de afstanden tussen de vormen, waar objecten aan elkaar grenzen, enzovoort, zodat hij een profiel identificeert van wat “kat” betekent. Als hij klaar is, zal de computer (in theorie) zijn ervaring kunnen gebruiken als hij andere ongelabelde foto’s te zien krijgt om de foto’s te vinden die van een kat zijn.
Laten we onze pluizige kattenvrienden even terzijde laten en wat technischer worden🤔😹. Hieronder staat een eenvoudige illustratie van de grijswaarden-afbeeldingsbuffer waarin onze afbeelding van Abraham Lincoln wordt opgeslagen. De helderheid van elke pixel wordt weergegeven door een enkel 8-bits getal, waarvan het bereik loopt van 0 (zwart) tot 255 (wit):

In feite worden pixelwaarden bijna universeel, op hardwareniveau, opgeslagen in een eendimensionale matrix. De gegevens van de bovenstaande afbeelding zijn bijvoorbeeld opgeslagen op een manier die lijkt op deze lange lijst van niet-ondertekende tekens:
{157, 153, 174, 168, 150, 152, 129, 151, 172, 161, 155, 156,
155, 182, 163, 74, 75, 62, 33, 17, 110, 210, 180, 154,
180, 180, 50, 14, 34, 6, 10, 33, 48, 106, 159, 181,
206, 109, 5, 124, 131, 111, 120, 204, 166, 15, 56, 180,
194, 68, 137, 251, 237, 239, 239, 228, 227, 87, 71, 201,
172, 105, 207, 233, 233, 214, 220, 239, 228, 98, 74, 206,
188, 88, 179, 209, 185, 215, 211, 158, 139, 75, 20, 169,
189, 97, 165, 84, 10, 168, 134, 11, 31, 62, 22, 148,
199, 168, 191, 193, 158, 227, 178, 143, 182, 106, 36, 190,
205, 174, 155, 252, 236, 231, 149, 178, 228, 43, 95, 234,
190, 216, 116, 149, 236, 187, 86, 150, 79, 38, 218, 241,
190, 224, 147, 108, 227, 210, 127, 102, 36, 101, 255, 224,
190, 214, 173, 66, 103, 143, 96, 50, 2, 109, 249, 215,
187, 196, 235, 75, 1, 81, 47, 0, 6, 217, 255, 211,
183, 202, 237, 145, 0, 0, 12, 108, 200, 138, 243, 236,
195, 206, 123, 207, 177, 121, 123, 200, 175, 13, 96, 218};
Deze manier om beeldgegevens op te slaan kan tegen uw verwachtingen ingaan, omdat de gegevens zeker tweedimensionaal lijken wanneer ze worden weergegeven. Toch is dit het geval, aangezien het computergeheugen eenvoudigweg bestaat uit een steeds groter wordende lineaire lijst van adresruimten.

Laten we nog eens teruggaan naar het eerste plaatje en ons voorstellen dat er een gekleurd plaatje wordt toegevoegd. Nu begint het ingewikkelder te worden. Computers lezen kleur gewoonlijk als een reeks van 3 waarden – rood, groen en blauw (RGB) – op diezelfde schaal van 0-255. Nu heeft elke pixel in feite 3 waarden die de computer kan opslaan, naast de positie. Als we president Lincoln zouden inkleuren, zou dat leiden tot 12 x 16 x 3 waarden, of 576 getallen.

Dat is veel geheugen voor één afbeelding en veel pixels voor een algoritme om over te itereren. Maar om een model met significante nauwkeurigheid te trainen, vooral als je het hebt over Deep Learning, heb je meestal tienduizenden afbeeldingen nodig, en hoe meer hoe beter.
The Evolution Of Computer Vision
Vóór de komst van deep learning waren de taken die computervisie kon uitvoeren zeer beperkt en vergden ze veel handmatige codering en inspanning van ontwikkelaars en menselijke operators. Als u bijvoorbeeld gezichtsherkenning wilde uitvoeren, zou u de volgende stappen moeten uitvoeren:
- Een database maken: Je moest individuele beelden vastleggen van alle onderwerpen die je wilde volgen in een specifiek formaat.
- Annoteer beelden: Vervolgens zou u voor elke individuele afbeelding verschillende belangrijke gegevenspunten moeten invoeren, zoals de afstand tussen de ogen, de breedte van de neusbrug, de afstand tussen bovenlip en neus, en tientallen andere metingen die de unieke kenmerken van elke persoon bepalen.
- Nieuwe beelden vastleggen: Vervolgens zou je nieuwe beelden moeten vastleggen, hetzij van foto’s of video-inhoud. En dan moest je het meetproces opnieuw doorlopen, waarbij je de belangrijkste punten op het beeld markeerde. Ook moest je rekening houden met de hoek waaronder de foto was genomen.
Na al dit handmatige werk zou de applicatie uiteindelijk in staat zijn om de metingen in de nieuwe foto te vergelijken met die welke in de database waren opgeslagen en je vertellen of het overeenkwam met een van de profielen die het bijhield. In feite was er heel weinig automatisering en werd het meeste werk handmatig gedaan. En de foutmarge was nog steeds groot.
Machine-leren bood een andere benadering voor het oplossen van computervisieproblemen. Met machine learning hoefden ontwikkelaars niet langer elke regel handmatig in hun vision-toepassingen te coderen. In plaats daarvan programmeerden zij “features”, kleinere toepassingen die specifieke patronen in beelden konden detecteren. Vervolgens gebruikten ze een statistisch leeralgoritme zoals lineaire regressie, logistische regressie, beslisbomen of support vector machines (SVM) om patronen te detecteren en beelden te classificeren en objecten daarin te detecteren.
Machine-leren hielp bij het oplossen van veel problemen die historisch gezien een uitdaging vormden voor klassieke software-ontwikkelingshulpmiddelen en -benaderingen. Jaren geleden waren ingenieurs op het gebied van machinaal leren bijvoorbeeld in staat om software te maken die overlevingsvensters voor borstkanker beter kon voorspellen dan menselijke deskundigen. Het bouwen van de functies van de software vereiste echter de inspanningen van tientallen ingenieurs en borstkankerexperts en nam veel tijd in beslag.
Diepe leerprocessen bieden een fundamenteel andere benadering van machine learning. Deep learning is gebaseerd op neurale netwerken, een functie voor algemeen gebruik die elk probleem kan oplossen dat door voorbeelden kan worden weergegeven. Wanneer je een neuraal netwerk voorziet van veel gelabelde voorbeelden van een specifiek soort gegevens, zal het in staat zijn om gemeenschappelijke patronen tussen die voorbeelden te extraheren en deze om te zetten in een wiskundige vergelijking die zal helpen bij het classificeren van toekomstige stukken informatie.
Bij het maken van een gezichtsherkenningstoepassing met deep learning hoef je bijvoorbeeld alleen maar een vooraf geconstrueerd algoritme te ontwikkelen of te kiezen en het te trainen met voorbeelden van de gezichten van de mensen die het moet detecteren. Gegeven genoeg voorbeelden (veel voorbeelden), zal het neurale netwerk in staat zijn om gezichten te detecteren zonder verdere instructies over kenmerken of metingen.
Diep leren is een zeer effectieve methode om computervisie te doen. In de meeste gevallen komt het creëren van een goed deep learning-algoritme neer op het verzamelen van een grote hoeveelheid gelabelde trainingsgegevens en het afstemmen van de parameters, zoals het type en het aantal lagen van neurale netwerken en trainingsepochs. Vergeleken met eerdere soorten machinaal leren, is deep learning zowel gemakkelijker als sneller te ontwikkelen en in te zetten.
De meeste van de huidige computervisietoepassingen zoals kankerdetectie, zelfrijdende auto’s en gezichtsherkenning maken gebruik van deep learning. Deep learning en diepe neurale netwerken zijn van het conceptuele rijk naar praktische toepassingen verhuisd dankzij de beschikbaarheid en vooruitgang in hardware en cloud computing resources.
Hoe lang duurt het om een afbeelding te ontcijferen
In het kort niet veel. Dat is de sleutel tot waarom computervisie zo opwindend is: Terwijl vroeger zelfs supercomputers dagen, weken of zelfs maanden nodig hadden om alle vereiste berekeningen uit te voeren, maken de ultrasnelle chips en aanverwante hardware van vandaag, samen met het snelle, betrouwbare internet en cloudnetwerken, het proces bliksemsnel. Een andere cruciale factor is de bereidheid van veel van de grote bedrijven die AI-onderzoek doen, om hun werk te delen. Facebook, Google, IBM en Microsoft, met name door een deel van hun werk op het gebied van machinaal leren open te sourcen.
Dit stelt anderen in staat om op hun werk voort te bouwen in plaats van vanaf nul te beginnen. Het resultaat is dat de AI-industrie op volle toeren draait, en experimenten die tot voor kort weken duurden, nu in 15 minuten kunnen worden uitgevoerd. En voor veel real-world toepassingen van computer vision, dit proces gebeurt allemaal continu in microseconden, zodat een computer vandaag de dag in staat is om te zijn wat wetenschappers noemen “situationeel bewust.”
Toepassingen van computer vision
Computer vision is een van de gebieden in Machine Learning waar kernconcepten al worden geïntegreerd in belangrijke producten die we elke dag gebruiken.
CV in zelfrijdende auto’s
Maar het zijn niet alleen techbedrijven die Machine Learning inzetten voor beeldtoepassingen.
Computer vision stelt zelfrijdende auto’s in staat om hun omgeving te begrijpen. Camera’s nemen videobeelden op vanuit verschillende hoeken rond de auto en voeden deze aan computervisiesoftware, die vervolgens de beelden in realtime verwerkt om de uiteinden van wegen te vinden, verkeersborden te lezen, andere auto’s, objecten en voetgangers te detecteren. De zelfrijdende auto kan dan zijn weg op straten en snelwegen sturen, vermijden obstakels te raken, en (hopelijk) zijn passagiers veilig naar hun bestemming rijden.
CV In Facial Recognition
Computer vision speelt ook een belangrijke rol in gezichtsherkenningstoepassingen, de technologie die computers in staat stelt afbeeldingen van gezichten van mensen te matchen met hun identiteiten. Computervisie-algoritmen detecteren gezichtskenmerken in beelden en vergelijken deze met databases van gezichtsprofielen. Consumentenapparatuur gebruikt gezichtsherkenning om de identiteit van de eigenaar te verifiëren. Apps voor sociale media gebruiken gezichtsherkenning om gebruikers te detecteren en te taggen. Wetshandhavingsinstanties vertrouwen ook op gezichtsherkenningstechnologie om criminelen in videofeeds te identificeren.
CV In Augmented Reality & Mixed Reality
Computer vision speelt ook een belangrijke rol in augmented en mixed reality, de technologie die computerapparaten zoals smartphones, tablets en slimme brillen in staat stelt om virtuele objecten op beelden van de echte wereld te leggen en in te bedden. Met behulp van computervisie detecteren AR-toestellen objecten in de echte wereld om te bepalen waar op het scherm van een apparaat een virtueel object moet worden geplaatst. Zo kunnen computervisie-algoritmen AR-toepassingen helpen bij het detecteren van vlakken zoals tafelbladen, muren en vloeren, een zeer belangrijk onderdeel van het vaststellen van diepte en dimensies en het plaatsen van virtuele objecten in de fysieke wereld.
CV In Healthcare
Computer vision is ook een belangrijk onderdeel geweest van de vooruitgang in health-tech. Computer vision-algoritmen kunnen helpen bij het automatiseren van taken zoals het opsporen van moedervlekken in huidbeelden of het vinden van symptomen in röntgen- en MRI-scans.
Uitdagingen van computer vision
Het helpen van computers om te zien blijkt heel moeilijk te zijn.
Het uitvinden van een machine die ziet zoals wij is een bedrieglijk moeilijke taak, niet alleen omdat het moeilijk is om computers het te laten doen, maar ook omdat we niet helemaal zeker weten hoe het menselijk zicht in de eerste plaats werkt.
Om biologisch zicht te bestuderen is inzicht nodig in de waarnemingsorganen zoals de ogen, en ook in de interpretatie van de waarneming in de hersenen. Er is veel vooruitgang geboekt, zowel bij het in kaart brengen van het proces als bij het ontdekken van de trucs en sluipwegen die door het systeem worden gebruikt, hoewel er, zoals bij elke studie waarbij de hersenen betrokken zijn, nog een lange weg te gaan is.

Veel populaire computervisietoepassingen bestaan uit het proberen te herkennen van dingen op foto’s; bijvoorbeeld:
- Objectclassificatie: Welke brede categorie van objecten staat op deze foto?
- Object Identificatie: Welk type van een bepaald object staat op deze foto?
- Objectverificatie: Staat het object op de foto?
- Object Detectie: Waar staan de objecten op de foto?
- Object Landmark Detection: Wat zijn de belangrijkste punten voor het object op de foto?
- Object Segmentatie: Welke pixels behoren tot het object in de foto?
- Objectherkenning: Welke objecten staan op deze foto en waar staan ze?
Naast herkenning zijn er nog andere analysemethoden, zoals:
- Video motion analysis maakt gebruik van computervisie om de snelheid van objecten in een video, of de camera zelf, te schatten.
- In beeldsegmentatie verdelen algoritmen beelden in meerdere sets weergaven.
- Scene reconstructie creëert een 3D-model van een scène die wordt ingevoerd via afbeeldingen of video.
- Bij beeldrestauratie wordt ruis, zoals onscherpte, uit foto’s verwijderd met behulp van op Machine Learning gebaseerde filters.
Elke andere toepassing waarbij pixels met behulp van software worden begrepen, kan gerust als computervisie worden bestempeld.
Conclusie
Ondanks de recente vooruitgang, die indrukwekkend is geweest, zijn we nog steeds niet eens in de buurt van het oplossen van computervisie. Er zijn echter al meerdere instellingen en bedrijven in de gezondheidszorg die manieren hebben gevonden om CV-systemen, aangedreven door CNN’s, toe te passen op problemen in de echte wereld. En het ziet er niet naar uit dat deze trend snel zal stoppen.
Als je contact met me wilt opnemen en je kent trouwens een goede mop, dan kun je me bereiken op Twitter of LinkedIn.
Dank voor het lezen!😄 🙌