- Hier ist ein Blick, warum es so fantastisch ist.
- Die Entwicklung der Computer Vision
- Wie lange dauert es, ein Bild zu entschlüsseln
- Anwendungen des maschinellen Sehens
- CV in selbstfahrenden Autos
- CV in der Gesichtserkennung
- CV in Augmented Reality & Mixed Reality
- CV im Gesundheitswesen
- Herausforderungen der Computer Vision
- Fazit
Hier ist ein Blick, warum es so fantastisch ist.
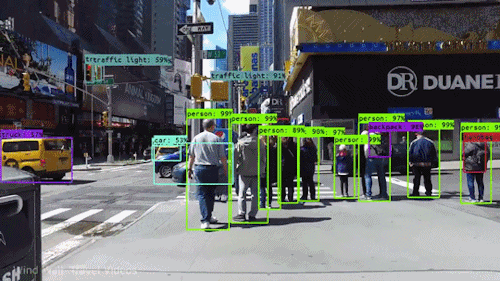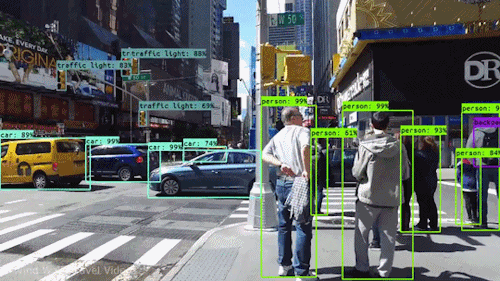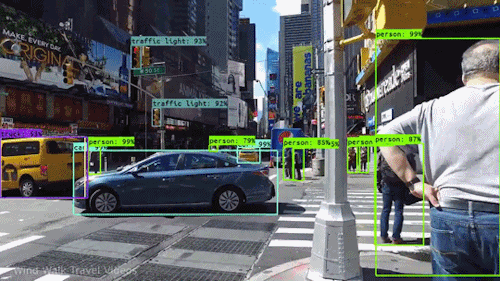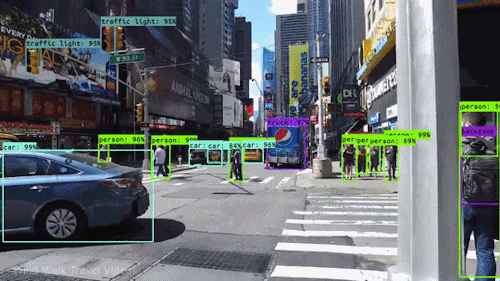
Eine der leistungsstärksten und überzeugendsten Arten von KI ist die Computer Vision, die Sie mit Sicherheit schon auf verschiedene Weise erlebt haben, ohne es zu wissen. Hier ein Blick darauf, was es ist, wie es funktioniert und warum es so fantastisch ist (und nur noch besser werden wird).
Computer Vision ist das Gebiet der Informatik, das sich darauf konzentriert, Teile der Komplexität des menschlichen Sehsystems nachzubilden und Computer in die Lage zu versetzen, Objekte in Bildern und Videos auf die gleiche Weise zu identifizieren und zu verarbeiten wie der Mensch. Bis vor kurzem funktionierte die Computer Vision nur in begrenztem Umfang.
Dank der Fortschritte in der künstlichen Intelligenz und der Innovationen im Bereich des Deep Learning und der neuronalen Netze konnte das Gebiet in den letzten Jahren große Sprünge machen und den Menschen bei einigen Aufgaben im Zusammenhang mit der Erkennung und Kennzeichnung von Objekten übertreffen.
Einer der treibenden Faktoren für das Wachstum der Computer Vision ist die Menge an Daten, die wir heute generieren und die dann zum Trainieren und Verbessern der Computer Vision verwendet werden.

Neben der enormen Menge an visuellen Daten (mehr als 3 Milliarden Bilder werden jeden Tag online ausgetauscht) ist nun auch die für die Analyse der Daten erforderliche Rechenleistung verfügbar. Mit der Entwicklung neuer Hardware und Algorithmen auf dem Gebiet der Computer Vision hat sich auch die Genauigkeit der Objekterkennung verbessert. In weniger als einem Jahrzehnt haben die heutigen Systeme eine Genauigkeit von 99 % erreicht, ausgehend von 50 %, und sind damit genauer als der Mensch, wenn es darum geht, schnell auf visuelle Eingaben zu reagieren.
Frühe Experimente mit dem Computersehen begannen in den 1950er Jahren, und in den 1970er Jahren wurde es erstmals kommerziell genutzt, um zwischen getipptem und handgeschriebenem Text zu unterscheiden; heute haben die Anwendungen für das Computersehen exponentiell zugenommen.
Bis 2022 wird der Markt für Computer Vision und Hardware voraussichtlich 48,6 Milliarden Dollar erreichen
Eine der wichtigsten offenen Fragen sowohl in den Neurowissenschaften als auch beim maschinellen Lernen lautet: Wie genau funktioniert unser Gehirn, und wie können wir uns dem mit unseren eigenen Algorithmen annähern? Die Realität ist, dass es nur sehr wenige funktionierende und umfassende Theorien über die Berechnung des Gehirns gibt; daher ist trotz der Tatsache, dass neuronale Netze angeblich „die Arbeitsweise des Gehirns nachahmen“, niemand ganz sicher, ob das tatsächlich stimmt.
Das gleiche Paradox gilt für das maschinelle Sehen – da wir nicht genau wissen, wie das Gehirn und die Augen Bilder verarbeiten, ist es schwierig zu sagen, wie gut die in der Produktion verwendeten Algorithmen unsere eigenen internen mentalen Prozesse annähern.
Auf einer bestimmten Ebene geht es beim maschinellen Sehen um Mustererkennung. Eine Möglichkeit, einen Computer darauf zu trainieren, visuelle Daten zu verstehen, besteht also darin, ihn mit Bildern zu füttern, mit vielen Bildern, Tausenden, wenn möglich Millionen, die beschriftet wurden, und diese dann verschiedenen Softwaretechniken oder Algorithmen zu unterziehen, die es dem Computer ermöglichen, Muster in allen Elementen aufzuspüren, die sich auf diese Beschriftungen beziehen.
Wenn man zum Beispiel einen Computer mit einer Million Bilder von Katzen füttert (wir alle lieben sie😄😹), wird er sie alle Algorithmen unterziehen, die es ihm ermöglichen, die Farben auf dem Foto, die Formen, die Abstände zwischen den Formen, die Stellen, an denen Objekte aneinander grenzen, und so weiter zu analysieren, so dass er ein Profil dessen erstellt, was „Katze“ bedeutet. Wenn er damit fertig ist, kann der Computer (theoretisch) seine Erfahrung nutzen, wenn er mit anderen, nicht beschrifteten Bildern gefüttert wird, um die Bilder zu finden, die von einer Katze stammen.
Lassen wir unsere flauschigen Katzenfreunde für einen Moment beiseite und werden wir etwas technischer🤔😹. Nachfolgend sehen Sie eine einfache Darstellung des Graustufenbildpuffers, in dem unser Bild von Abraham Lincoln gespeichert ist. Die Helligkeit jedes Pixels wird durch eine einzelne 8-Bit-Zahl dargestellt, deren Bereich von 0 (schwarz) bis 255 (weiß) reicht:

In der Tat werden Pixelwerte auf der Hardware-Ebene fast immer in einem eindimensionalen Feld gespeichert. Die Daten des obigen Bildes werden beispielsweise in einer Weise gespeichert, die dieser langen Liste von Zeichen ohne Vorzeichen ähnelt:
{157, 153, 174, 168, 150, 152, 129, 151, 172, 161, 155, 156,
155, 182, 163, 74, 75, 62, 33, 17, 110, 210, 180, 154,
180, 180, 50, 14, 34, 6, 10, 33, 48, 106, 159, 181,
206, 109, 5, 124, 131, 111, 120, 204, 166, 15, 56, 180,
194, 68, 137, 251, 237, 239, 239, 228, 227, 87, 71, 201,
172, 105, 207, 233, 233, 214, 220, 239, 228, 98, 74, 206,
188, 88, 179, 209, 185, 215, 211, 158, 139, 75, 20, 169,
189, 97, 165, 84, 10, 168, 134, 11, 31, 62, 22, 148,
199, 168, 191, 193, 158, 227, 178, 143, 182, 106, 36, 190,
205, 174, 155, 252, 236, 231, 149, 178, 228, 43, 95, 234,
190, 216, 116, 149, 236, 187, 86, 150, 79, 38, 218, 241,
190, 224, 147, 108, 227, 210, 127, 102, 36, 101, 255, 224,
190, 214, 173, 66, 103, 143, 96, 50, 2, 109, 249, 215,
187, 196, 235, 75, 1, 81, 47, 0, 6, 217, 255, 211,
183, 202, 237, 145, 0, 0, 12, 108, 200, 138, 243, 236,
195, 206, 123, 207, 177, 121, 123, 200, 175, 13, 96, 218};
Diese Art der Speicherung von Bilddaten mag Ihren Erwartungen zuwiderlaufen, da die Daten bei der Anzeige sicherlich zweidimensional erscheinen. Dies ist jedoch der Fall, da der Computerspeicher einfach aus einer immer größer werdenden linearen Liste von Adressräumen besteht.

Kehren wir noch einmal zum ersten Bild zurück und stellen wir uns vor, dass wir ein farbiges Bild hinzufügen. Jetzt werden die Dinge etwas komplizierter. Computer lesen Farben normalerweise als eine Reihe von drei Werten – Rot, Grün und Blau (RGB) – auf derselben Skala von 0 bis 255. Nun hat jedes Pixel tatsächlich 3 Werte, die der Computer zusätzlich zu seiner Position speichern muss. Wenn wir Präsident Lincoln einfärben würden, ergäben sich 12 x 16 x 3 Werte, also 576 Zahlen.

Das ist eine Menge Speicherplatz für ein Bild und eine Menge Pixel für einen Algorithmus, der darüber iterieren muss. Aber um ein Modell mit aussagekräftiger Genauigkeit zu trainieren, vor allem wenn es um Deep Learning geht, braucht man normalerweise Zehntausende von Bildern, und je mehr, desto besser.
Die Entwicklung der Computer Vision
Vor dem Aufkommen von Deep Learning waren die Aufgaben, die Computer Vision ausführen konnte, sehr begrenzt und erforderten viel manuelle Programmierung und Aufwand durch Entwickler und menschliche Bediener. Wenn man zum Beispiel eine Gesichtserkennung durchführen wollte, musste man folgende Schritte durchführen:
- Erstellen einer Datenbank: Man müsste einzelne Bilder von allen Personen, die man erfassen wollte, in einem bestimmten Format aufnehmen.
- Bilder beschriften: Dann mussten Sie für jedes einzelne Bild mehrere Schlüsseldaten eingeben, z. B. den Abstand zwischen den Augen, die Breite des Nasenrückens, den Abstand zwischen Oberlippe und Nase und Dutzende anderer Messungen, die die einzigartigen Merkmale jeder Person definieren.
- Neue Bilder aufnehmen: Als Nächstes mussten Sie neue Bilder aufnehmen, sei es von Fotos oder Videoinhalten. Und dann musste man den Messprozess erneut durchlaufen und die wichtigsten Punkte auf dem Bild markieren. Dabei musste auch der Aufnahmewinkel berücksichtigt werden.
Nach all dieser manuellen Arbeit war die Anwendung schließlich in der Lage, die Messungen im neuen Bild mit den in der Datenbank gespeicherten zu vergleichen und festzustellen, ob das Bild mit einem der verfolgten Profile übereinstimmte. Der Automatisierungsgrad war jedoch sehr gering, und der Großteil der Arbeit wurde manuell erledigt. Und die Fehlermarge war immer noch groß.
Maschinelles Lernen bot einen anderen Ansatz zur Lösung von Bildverarbeitungsproblemen. Mit maschinellem Lernen mussten die Entwickler nicht mehr jede einzelne Regel manuell in ihre Bildverarbeitungsanwendungen einprogrammieren. Stattdessen programmierten sie „Features“, kleinere Anwendungen, die bestimmte Muster in Bildern erkennen konnten. Sie verwendeten dann einen statistischen Lernalgorithmus wie lineare Regression, logistische Regression, Entscheidungsbäume oder Support Vector Machines (SVM), um Muster zu erkennen und Bilder zu klassifizieren und Objekte darin zu erkennen.
Maschinelles Lernen half bei der Lösung vieler Probleme, die in der Vergangenheit eine Herausforderung für klassische Softwareentwicklungswerkzeuge und -ansätze waren. So konnten Ingenieure für maschinelles Lernen vor Jahren eine Software entwickeln, die Überlebenszeitfenster für Brustkrebs besser vorhersagen konnte als menschliche Experten. Die Entwicklung der Funktionen der Software erforderte jedoch die Bemühungen von Dutzenden von Ingenieuren und Brustkrebsexperten und nahm viel Zeit in Anspruch.
Deep Learning bot einen grundlegend anderen Ansatz für das maschinelle Lernen. Deep Learning stützt sich auf neuronale Netze, eine Allzweckfunktion, die jedes durch Beispiele darstellbare Problem lösen kann. Wenn man einem neuronalen Netzwerk viele markierte Beispiele einer bestimmten Art von Daten zur Verfügung stellt, ist es in der Lage, gemeinsame Muster zwischen diesen Beispielen zu extrahieren und sie in eine mathematische Gleichung umzuwandeln, die bei der Klassifizierung zukünftiger Informationen hilft.
Beim Erstellen einer Gesichtserkennungsanwendung mit Deep Learning muss man beispielsweise nur einen vorgefertigten Algorithmus entwickeln oder auswählen und ihn mit Beispielen von Gesichtern der Personen trainieren, die er erkennen soll. Bei genügend Beispielen (vielen Beispielen) ist das neuronale Netz in der Lage, Gesichter zu erkennen, ohne dass weitere Anweisungen zu Merkmalen oder Messungen erforderlich sind.
Deep Learning ist eine sehr effektive Methode für die Computer Vision. In den meisten Fällen läuft die Entwicklung eines guten Deep-Learning-Algorithmus darauf hinaus, eine große Menge an markierten Trainingsdaten zu sammeln und die Parameter wie die Art und Anzahl der Schichten des neuronalen Netzes und die Trainingsepochen einzustellen. Im Vergleich zu früheren Arten des maschinellen Lernens ist Deep Learning sowohl einfacher als auch schneller zu entwickeln und einzusetzen.
Die meisten der aktuellen Computer-Vision-Anwendungen wie Krebserkennung, selbstfahrende Autos und Gesichtserkennung nutzen Deep Learning. Deep Learning und tiefe neuronale Netze sind dank der Verfügbarkeit und der Fortschritte bei Hardware und Cloud-Computing-Ressourcen aus dem konzeptionellen Bereich in die Praxis übergegangen.
Wie lange dauert es, ein Bild zu entschlüsseln
Kurz gesagt: nicht viel. Das ist der Schlüssel dazu, warum Computer Vision so spannend ist: Während früher selbst Supercomputer Tage, Wochen oder sogar Monate brauchten, um alle erforderlichen Berechnungen durchzuführen, machen die heutigen ultraschnellen Chips und die dazugehörige Hardware zusammen mit dem schnellen und zuverlässigen Internet und den Cloud-Netzwerken den Prozess blitzschnell. Ein weiterer entscheidender Faktor ist die Bereitschaft vieler großer KI-Forschungsunternehmen wie Facebook, Google, IBM und Microsoft, ihre Arbeit mit anderen zu teilen, insbesondere durch die Freigabe von Teilen ihrer maschinellen Lernverfahren.
Dadurch können andere auf ihrer Arbeit aufbauen, anstatt bei Null anzufangen. Das Ergebnis ist, dass die KI-Industrie immer schneller voranschreitet und Experimente, die vor kurzem noch Wochen dauerten, heute vielleicht 15 Minuten in Anspruch nehmen. Und bei vielen realen Anwendungen des maschinellen Sehens läuft dieser Prozess kontinuierlich in Mikrosekunden ab, so dass ein Computer heute in der Lage ist, das zu tun, was Wissenschaftler als „situationsbewusst“ bezeichnen.
Anwendungen des maschinellen Sehens
Das maschinelle Sehen ist einer der Bereiche des maschinellen Lernens, in dem Kernkonzepte bereits in wichtige Produkte integriert werden, die wir täglich nutzen.
CV in selbstfahrenden Autos
Aber nicht nur Technologieunternehmen nutzen maschinelles Lernen für Bildanwendungen.
Computer Vision ermöglicht es selbstfahrenden Autos, ihre Umgebung zu erfassen. Kameras nehmen Videos aus verschiedenen Winkeln rund um das Auto auf und leiten sie an eine Bildverarbeitungssoftware weiter, die die Bilder dann in Echtzeit verarbeitet, um die äußersten Enden von Straßen zu finden, Verkehrsschilder zu lesen und andere Autos, Objekte und Fußgänger zu erkennen. Das selbstfahrende Auto kann sich dann auf Straßen und Autobahnen orientieren, Hindernissen ausweichen und seine Passagiere (hoffentlich) sicher an ihr Ziel bringen.
CV in der Gesichtserkennung
Computer Vision spielt auch eine wichtige Rolle bei Anwendungen der Gesichtserkennung, der Technologie, die es Computern ermöglicht, Bilder von Gesichtern mit der Identität von Menschen abzugleichen. Bildverarbeitungsalgorithmen erkennen Gesichtsmerkmale in Bildern und vergleichen sie mit Datenbanken mit Gesichtsprofilen. Verbrauchergeräte nutzen die Gesichtserkennung, um die Identität ihrer Besitzer zu bestätigen. Anwendungen für soziale Medien nutzen die Gesichtserkennung, um Nutzer zu erkennen und zu markieren. Auch Strafverfolgungsbehörden verlassen sich auf die Gesichtserkennungstechnologie, um Kriminelle in Videoaufnahmen zu identifizieren.
CV in Augmented Reality & Mixed Reality
Computer Vision spielt auch eine wichtige Rolle in Augmented und Mixed Reality, der Technologie, die es Computergeräten wie Smartphones, Tablets und Smart Glasses ermöglicht, virtuelle Objekte über reale Bilder zu legen und einzubetten. Mithilfe von Computer Vision erkennen AR-Geräte Objekte in der realen Welt, um die Stellen auf dem Display eines Geräts zu bestimmen, an denen ein virtuelles Objekt platziert werden soll. So können Computer-Vision-Algorithmen AR-Anwendungen dabei helfen, Ebenen wie Tischplatten, Wände und Böden zu erkennen, was für die Bestimmung von Tiefe und Dimensionen und die Platzierung virtueller Objekte in der realen Welt sehr wichtig ist.
CV im Gesundheitswesen
Computer-Vision ist auch ein wichtiger Bestandteil der Fortschritte in der Gesundheitstechnologie. Bildverarbeitungsalgorithmen können dabei helfen, Aufgaben wie die Erkennung von krebsartigen Muttermalen in Hautbildern oder das Auffinden von Symptomen in Röntgen- und MRT-Scans zu automatisieren.
Herausforderungen der Computer Vision
Computern das Sehen beizubringen, erweist sich als sehr schwierig.
Eine Maschine zu erfinden, die so sieht wie wir, ist eine trügerisch schwierige Aufgabe, nicht nur, weil es schwierig ist, Computer dazu zu bringen, es zu tun, sondern weil wir nicht ganz sicher sind, wie das menschliche Sehen überhaupt funktioniert.
Das Studium des biologischen Sehens erfordert ein Verständnis der Wahrnehmungsorgane wie der Augen sowie der Interpretation der Wahrnehmung im Gehirn. Es wurden viele Fortschritte gemacht, sowohl bei der Darstellung des Prozesses als auch bei der Entdeckung der Tricks und Abkürzungen, die das System verwendet, obwohl wie bei jeder Studie, die das Gehirn mit einbezieht, noch ein langer Weg vor uns liegt.

Viele populäre Computer-Vision-Anwendungen beinhalten den Versuch, Dinge auf Fotos zu erkennen; zum Beispiel:
- Objektklassifizierung: Welche Art von Objekt ist auf diesem Foto zu sehen?
- Objektidentifikation: Welcher Typ eines bestimmten Objekts befindet sich auf diesem Foto?
- Objektverifizierung: Ist das Objekt auf dem Foto?
- Objekterkennung: Wo befinden sich die Objekte auf dem Foto?
- Objekterkennung (Landmark Detection): Was sind die Schlüsselpunkte für das Objekt auf dem Foto?
- Objektsegmentierung: Welche Pixel gehören zu dem Objekt auf dem Bild?
- Objekterkennung: Welche Objekte sind auf diesem Foto zu sehen und wo befinden sie sich?
Neben der reinen Erkennung gibt es noch weitere Analysemethoden:
- Bei der Videobewegungsanalyse wird die Computervision verwendet, um die Geschwindigkeit von Objekten in einem Video oder der Kamera selbst zu schätzen.
- Bei der Bildsegmentierung teilen Algorithmen Bilder in mehrere Sätze von Ansichten auf.
- Die Szenenrekonstruktion erstellt ein 3D-Modell einer Szene, die über Bilder oder Videos eingegeben wurde.
- Bei der Bildrestaurierung wird Rauschen wie z. B. Unschärfe mit Hilfe von auf maschinellem Lernen basierenden Filtern aus Fotos entfernt.
Jede andere Anwendung, bei der es um das Verstehen von Pixeln durch Software geht, kann getrost als Computer Vision bezeichnet werden.
Fazit
Trotz der beeindruckenden Fortschritte in jüngster Zeit sind wir noch nicht einmal annähernd so weit, Computer Vision zu lösen. Es gibt jedoch bereits mehrere Einrichtungen und Unternehmen des Gesundheitswesens, die Wege gefunden haben, CV-Systeme auf der Grundlage von CNNs auf reale Probleme anzuwenden. Und dieser Trend wird wahrscheinlich nicht so bald aufhören.
Wenn Sie mit mir in Kontakt treten wollen und übrigens einen guten Witz kennen, können Sie sich mit mir auf Twitter oder LinkedIn in Verbindung setzen.
Danke fürs Lesen!😄 🙌