Het hoeft ons niet te verbazen dat zelfs in delen van het genoom waar we niet duidelijk een “functionele” code zien (d.w.z. een code die evolutionair is vastgelegd als gevolg van een of ander selectief voordeel), er wel degelijk een soort code bestaat, maar niet zoals iets wat we tot nu toe als zodanig hebben beschouwd. En wat als het iets in drie dimensies zou doen naast de ene dimensie van de ATGC code? Een artikel dat zojuist is gepubliceerd in BioEssays verkent deze verleidelijke mogelijkheid…
Is het niet heerlijk om een werkelijk verbijsterend probleem te hebben om aan te knagen, één dat bijna eindeloze potentiële verklaringen genereert. Wat te denken van “wat doet al dat niet-coderende DNA in genomen?” – die 98,5% van het menselijk genetisch materiaal dat geen eiwitten produceert. Om eerlijk te zijn, de ontcijfering van niet-coderend DNA boekt grote vooruitgang via de identificatie van sequenties die worden getranscribeerd in RNA’s die de genexpressie moduleren, transgenerationeel kunnen worden doorgegeven (epigenetica) of het genexpressieprogramma van een stamcel of specifieke weefselcel bepalen. In veel genomen zijn enorme hoeveelheden herhaalde sequenties aangetroffen (overblijfselen van oude retrovirussen), en nogmaals, deze coderen niet voor eiwitten, maar er zijn tenminste geloofwaardige modellen voor wat zij in evolutionair opzicht doen (variërend van genomisch parasitisme tot symbiose en zelfs “exploitatie” door het genoom van de gastheer zelf voor het produceren van de genetische diversiteit waarop de evolutie werkt); Overigens, sommige niet-coderende DNA’s maken RNA’s die deze retrovirale sequenties tot zwijgen brengen, en retrovirale binnendringing in genomen wordt verondersteld de selectieve druk te zijn geweest voor de evolutie van RNA-interferentie (zogenaamde RNAi); repetitieve elementen van verschillende met name genoemde typen en tandem herhalingen zijn er in overvloed; introns (waarvan vele de bovengenoemde typen niet-coderende sequenties bevatten) blijken cruciaal te zijn voor genexpressie en -regulering, het meest opvallend via alternatieve splicing van de coderende segmenten die zij scheiden.
Toch is er nog genoeg om aan te knagen, want hoewel we steeds meer begrijpen van de aard en de oorsprong van veel van het niet-coderende genoom en we steeds meer inzicht krijgen in de “functie” ervan (hier gedefinieerd als evolutionair geselecteerd, gunstig effect op het gastheerorganisme), kunnen we nog lang niet alles verklaren, en – wat nog belangrijker is – we bekijken het als het ware met een lens met een zeer lage vergroting. Een van de intrigerende dingen van DNA-sequenties is dat een enkele sequentie meer dan één stukje informatie kan “coderen”, afhankelijk van wat het “leest” en in welke richting – virale genomen zijn klassieke voorbeelden waarin genen die in de ene richting worden gelezen om een bepaald eiwit te produceren, overlappen met een of meer genen die in de andere richting worden gelezen (d.w.z. vanaf de complementaire streng van het DNA) om verschillende eiwitten te produceren. Het is een beetje zoals het maken van eenvoudige boodschappen met omgekeerd-paar-woorden (een zogenaamde emordnilap). Bijvoorbeeld: REEDSTOPSFLOW, dat door een denkbeeldig leesapparaat zou kunnen worden gesplitst in REED STOPS FLOW. Achterstevoren gelezen zou dit WOLF SPOTS DEER opleveren.
Nu, als het evolutionair voordeel oplevert dat twee boodschappen zo economisch gecodeerd zijn – zoals het geval is in virale genomen, die de neiging hebben te evolueren naar een minimale complexiteit in termen van informatie-inhoud, waardoor de noodzakelijke middelen voor reproductie worden verminderd – dan evolueren de boodschappen zelf met een hoge mate van dwang. Wat betekent dit? Welnu, we zouden onze oorspronkelijke voorbeeldboodschap kunnen formuleren als RUSH-STEM IMPEDES CURRENT, wat dezelfde essentiële informatie zou inhouden als REED STOPS FLOW. Maar als dat bericht omgekeerd wordt gelezen (of zelfs in dezelfde zin, maar in verschillende brokken), bevat het niets extra’s dat bijzonder betekenisvol is. Waarschijnlijk is de enige manier om beide stukjes informatie in de oorspronkelijke berichten tegelijk over te brengen de eigenlijke formulering REEDSTOPSFLOW: dat is een zeer beperkt systeem! Als we voldoende voorbeelden van omgekeerd samengestelde zinnen in het Engels zouden bestuderen, zouden we zien dat ze over het algemeen uit vrij korte woorden bestaan, en dat in de sequenties bepaalde taaleenheden ontbreken, zoals lidwoorden (the, a); als we nauwkeuriger zouden kijken, zouden we zelfs kunnen vaststellen dat bepaalde letters van het alfabet in dergelijke berichten meer dan gemiddeld vertegenwoordigd zijn. We zouden dit zien als vertekeningen in woord- en lettergebruik die ons, a priori, in staat zouden stellen een poging te wagen om dergelijke “dubbelfuncties” van informatie te identificeren.
Nu keren we terug naar de “letters”, “woorden”, en “informatie” die in genomen is gecodeerd. Voor twee verschillende stukken informatie die in hetzelfde stuk genetische sequentie zijn gecodeerd, zouden we verwachten dat de beperkingen zich zouden manifesteren in vertekeningen in het gebruik van woorden en letters – de analogieën, respectievelijk, voor aminozuursequenties die proteïnen vormen en hun drielettercode. Een DNA-sequentie kan dus coderen voor een eiwit en daarnaast voor iets anders. Dit “iets anders”, volgens Giorgio Bernardi, is informatie die de verpakking van de enorme lengte DNA in een cel in de relatief kleine kern leidt. Hoofdzakelijk is het de code die de binding van de DNA-verpakkingsproteïnen, bekend als histonen, leidt. Bernardi noemt dit de “genomische code” – een structurele code die de vorm en de verdichting van het DNA bepaalt in de sterk gecondenseerde vorm die bekend staat als “chromatine”.
Maar zijn we niet begonnen met een verklaring voor niet-coderend DNA, niet voor eiwit-coderende sequenties? Ja, en in de lange stukken niet-coderend DNA zien we informatie die verder gaat dan louter herhalingen, tandem herhalingen en overblijfselen van oude retrovirussen: er is een soort code op het niveau van de voorkeur voor het GC-paar van chemische DNA-basen ten opzichte van AT. Zoals Bernardi beschrijft, met een synthese van zijn baanbrekend werk en dat van anderen, is in de kernsequenties van het eukaryotisch genoom het GC-gehalte in structurele organisatorische eenheden van het genoom, de zogenaamde “isochores”, toegenomen tijdens de evolutionaire overgang tussen zogenaamde koudbloedige en warmbloedige organismen. En, fascinerend, deze sequentie bias overlapt met sequenties die veel meer beperkt zijn in functie: dit zijn de eerder genoemde eiwit-coderende sequenties, en zij – meer dan de tussenliggende niet-coderende sequenties – vormen de aanwijzing voor de “genomische code”.
Eiwit-coderende sequenties zijn ook opeengepakt en gecondenseerd in de kern – vooral wanneer zij niet “in gebruik” zijn (d.w.z., maar zij bevatten ook relatief constante informatie over de exacte aminozuuridentiteit, anders zouden zij er niet in slagen om eiwitten correct te coderen: de evolutie zou op een zeer negatieve manier op dergelijke mutaties reageren, waardoor het uiterst onwaarschijnlijk zou zijn dat zij zouden blijven bestaan en voor ons zichtbaar zouden zijn. Maar de aminozuurcode in DNA heeft een klein “addertje onder het gras” dat miljarden jaren geleden in de meest eenvoudige eencellige organismen (bacteriën en archaea) is ontstaan: de code is gedeeltelijk overbodig. Het aminozuur Threonine bijvoorbeeld kan in eukaryotisch DNA op niet minder dan vier manieren worden gecodeerd: ACT, ACC, ACA of ACG. De derde letter is variabel en dus “beschikbaar” voor de codering van extra informatie. Dit is precies wat er gebeurt om de “genomische code” te produceren, in dit geval een voorkeur creërend voor de ACC en ACG vormen in warmbloedige organismen. De hoge druk op deze extra “code” – die ook wordt waargenomen in delen van het genoom die niet onder een dergelijke druk staan als eiwit-coderende sequenties – wordt dus opgelegd door de verpakking van eiwit-coderende sequenties die twee reeksen informatie tegelijk belichamen. Dit is analoog aan ons voorbeeld van de zeer beperkte sequentie met dubbele informatie REEDSTOPSFLOW.
Belangrijk is echter dat de beperking niet zo strikt is als in ons Engelstalige voorbeeld vanwege de redundantie van de derde positie van de tripletcode voor aminozuren: een betere analogie zou zijn SHE*ATE*STU* waarbij de asterisk staat voor een variabele letter die geen verschil maakt voor de machine die de drielettercomponent van de vierletterige boodschap leest. Men zou zich dan een tweede informatieniveau kunnen voorstellen dat wordt gevormd door een “D” toe te voegen aan deze sterretjes, om SHEDATEDSTUD (SHE DATED STUD) te maken. Stel u vervolgens een tweede leesmachine voor die op zoek gaat naar betekenisvolle zinnen van “gevoelige aard” die een meer dan gemiddelde concentratie van D’s bevatten. Deze leesmachine heeft een vouwmachine bij zich die op elke D een soort knijper plaatst, waardoor de boodschap 120 graden in een vlak wordt geknikt. een punt waar de boodschap 120 graden in hetzelfde vlak zou moeten worden geknikt, zouden we eindigen met een compactere, driehoekige, versie. In eukaryote genomen strekt de GC-sequentievooringenomenheid die verantwoordelijk zou zijn voor structurele condensatie zich uit tot niet-coderende sequenties, waarvan sommige activiteiten hebben geïdentificeerd, hoewel ze minder sequentiegebonden zijn dan eiwitcoderend DNA. Daar stuurt het hun condensatie via histon-bevattende nucleosomen om chromatine te vormen.
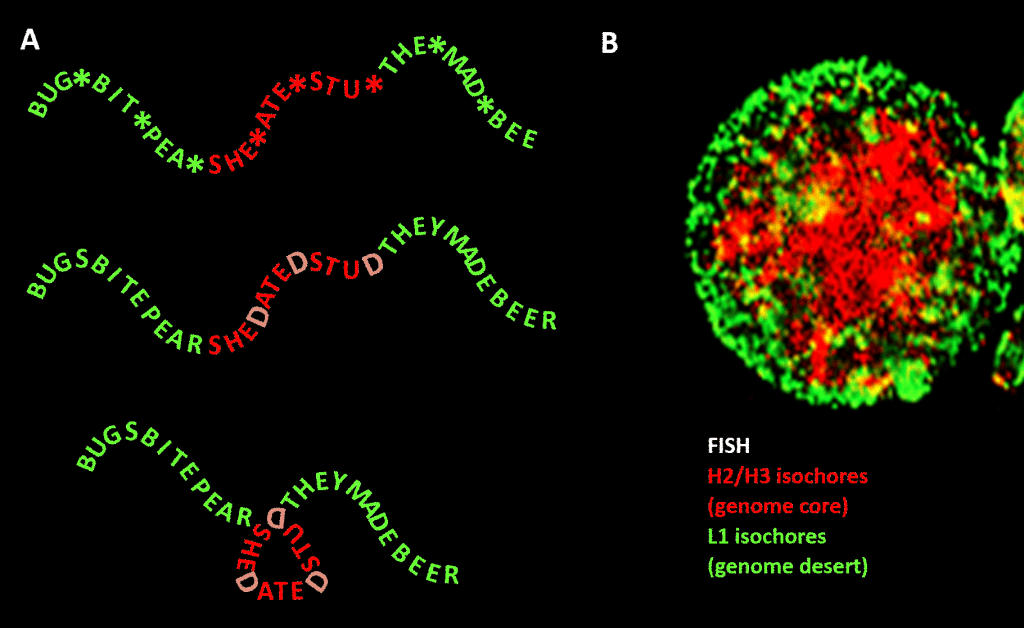
Figuur. Analogie tussen de condensatie van een op woorden gebaseerde boodschap en de condensatie van genomisch DNA in de celkern. Paneel A: Informatie binnen informatie, een opeenvolging van woorden met een variabele vierde spatie die, wanneer ze met bepaalde letters wordt gevuld, een volgend bericht genereert. Het ene bericht wordt gelezen door een leesmachine met drie letters; het andere door een leesmachine die informatie kan interpreteren die zich uitstrekt tot de vierde-variabele-positie van de reeks. De tweede lezer herkent “gevoelige” informatie die moet worden verborgen, en op de punten waar een “D” op de 4e positie verschijnt, vouwt hij de woordenreeks om, waardoor het “gevoelige” gedeelte wordt samengedrukt en aan het zicht wordt onttrokken. Dit is een analogie voor het principe van genomische 3D-compressie via chromatine, zoals afgebeeld in paneel B: een fluorescentiebeeld (via Fluorescentie In-Situ Hybridisatie – FISH) van de celkern. H2/H3 isochoren, die in GC-gehalte toenamen tijdens de evolutie van koudbloedige naar warmbloedige gewervelde dieren, worden samengeperst tot een chromatine kern, waardoor L1 isochoren (met lager GC-gehalte) aan de periferie in een minder gecondenseerde toestand achterblijven. De “genomische code” belichaamd in de hoge GC-lijnen van het genoom wordt, volgens Bernardi , gelezen door de nucleosoom-positioneringsmachine van de cel en geïnterpreteerd als sequentie die sterk moet worden samengeperst in euchromatine. Acknowledgements: Paneel A: concept en figuur productie: Andrew Moore; Panel B: een FISH patroon van H2 / H3 en L1 isochores van een lymfocyt geïnduceerd door PHA-courtesy van S. Saccone-zoals gereproduceerd in Ref. .]
Deze gebieden van DNA kunnen dan worden beschouwd als structureel belangrijke elementen in het vormen van de juiste vorm en scheiding van gecondenseerde coderende sequenties in het genoom, ongeacht enige andere mogelijke functie die deze niet-coderende sequenties hebben: in essentie zou dit een “verklaring” zijn voor de persistentie in genomen van sequenties waaraan geen “functie” (in termen van evolutionair-geselecteerde activiteit), kan worden toegeschreven (of, tenminste, geen substantiële functie).
Een laatste analogie – deze keer veel nauwer verwant – zou de aminozuur-sequenties in grote eiwitten kunnen zijn, die een verscheidenheid aan kronkels, bochten, vouwen enz. maken. We kunnen ons verwonderen over zulke ingewikkelde structuren en vragen “maar moeten ze zo ingewikkeld zijn voor hun functie?” Misschien wel om delen van het eiwit in de juiste richting en op de juiste plaats samen te persen en te positioneren, zodat de driedimensionale structuur ontstaat die met succes door de evolutie is geselecteerd. Maar met de wetenschap dat de “genomische code” eiwitcoderende sequenties overlapt, zouden we zelfs kunnen gaan vermoeden dat er ook nog een andere selectieve druk aan het werk is…
Andrew Moore, Ph.D.
Editor-in-Chief, BioEssays